facedetecor 人脸识别
//添加依赖
//JAVA
// repositories {
// maven {
// url "http://dl.bintray.com/fotoapparat/fotoapparat"
// }
// }
//
// compile 'io.fotoapparat:facedetector:1.0.0'
//
//// If you are using Fotoapparat add this one as well
// compile 'io.fotoapparat.fotoapparat:library:1.2.0' // or later version
//
//
// 流程:
// 1. 选择照片
//2. 将照片加载到 bitmap 中并缩放到设置的宽高
//3. 用 FaceDetector 来检测人脸,得到 Face 类数组(多人脸检测)
// 4. 在照片 bitmap 检测到的人脸上面画上方框和年龄
//
//#### 选择照片
//
// 将 Intent 设置 Type 和 Action,启动 activity 选择照片并得到照片的 uri。
// JAVA
// Intent intent = new Intent();
// intent.setType("image/*");
// intent.setAction(Intent.ACTION_GET_CONTENT);
// startActivityForResult(intent, OPEN_PHOTO_FOLDER_REQUEST_CODE);
//
//
// #### 加载照片到 bitmap 并缩放
//
//1. 通过uri用stream
//JAVA
// public void initBitmap(Uri uri,int width,int height) {
// try {
// ContentResolver resolver = mContext.getContentResolver();
// BitmapFactory.Options options = new BitmapFactory.Options();
// options.inPreferredConfig = Bitmap.Config.RGB_565;//need this config
// Bitmap bitmap = BitmapFactory.decodeStream(resolver.openInputStream(uri), null, options);
// mBitmap = ThumbnailUtils.extractThumbnail(bitmap, width, height);//scale the bitmap
// detectFace();
// } catch (Exception ex) {
// Log.e(TAG,"exception: "+ex.getMessage());
// }
// }
//
//
// 2. 通过真实路径的加载
//JAVA
// private void initFRViewWithPath(Uri uri) {
// String[] projection = {MediaStore.Images.Media.DATA};
// // Cursor cursor = managedQuery(uri, projection, null, null, null);//deprecated
// CursorLoader cursorLoader = new CursorLoader(this,uri,projection,null,null,null);
// Cursor cursor = cursorLoader.loadInBackground();
// int column_index = cursor.getColumnIndexOrThrow(MediaStore.Images.Media.DATA);
// cursor.moveToFirst();
//
// String path = cursor.getString(column_index);
// Log.e(TAG,"real path: "+path);
// mFRView.initBitmap(path,mFRView.getWidth (),mFRView.getHeight());
// }
// public void initBitmap(String path,int width,int height) {
// BitmapFactory.Options options = new BitmapFactory.Options();
// options.inPreferredConfig = Bitmap.Config.RGB_565;
// mBitmap = BitmapFactory.decodeFile(path, options);
// mBitmap = ThumbnailUtils.extractThumbnail(mBitmap,width,height);//scale the bitmap
// detectFace();
// }
//
//
// ### 人脸检测
//
//JAVA
// private void detectFace() {
// if(mBitmap != null) {
// mImageWidth = mBitmap.getWidth();
// mImageHeight = mBitmap.getHeight();
// mFaces = new FaceDetector.Face[NUMBER_OF_FACES];
// mFaceDetector = new FaceDetector(mImageWidth, mImageHeight, NUMBER_OF_FACES);
// mNumberOfFaceDetected = mFaceDetector.findFaces(mBitmap, mFaces);
// invalidate();
// }
// }
//
//
// #### 人脸画框
//
// 在 onDraw 中用 canvas 将检测到的人脸画上框并写上年龄。
//
// JAVA
// @Override
// protected void onDraw(Canvas canvas) {
// super.onDraw(canvas);
// if(mBitmap != null) {
// canvas.drawBitmap(mBitmap, 0, 0, null);
// Paint paint = new Paint();
// paint.setColor(Color.WHITE);
// paint.setStyle(Paint.Style.STROKE);
// paint.setStrokeWidth(2);
// paint.setTextSize(50);
//
// for(int i=0; i < mNumberOfFaceDetected; i++){
// FaceDetector.Face face = mFaces[i];
// PointF pointF = new PointF();
// face.getMidPoint(pointF);
// mEyesDistance = face.eyesDistance();
// canvas.drawRect(
// (int)(pointF.x - mEyesDistance),
// (int)(pointF.y - mEyesDistance/2),
// (int)(pointF.x + mEyesDistance),
// (int)(pointF.y + mEyesDistance*3/2),
// paint);
// canvas.drawText("28",pointF.x,pointF.y - mEyesDistance/2-5,paint);
// }
// }
// }
//
简单工厂模式
也称为静态工厂方法模式,由一个工厂对象决定创建出哪一种产品类的实例。
简单工厂模式中有如下角色:
- 工厂类:核心,负责创建所有实例的内部逻辑,由外界直接调用。
- 抽象产品类:要创建所有对象的抽象父类,负责描述所有实例所共有的公共接口。
- 具体产品类:要创建的产品。
简单示例
1、抽象产品类
1 | public abstract class Computer { |
2、具体产品类
1 | public class LenovaComputer extends Computer { |
3、工厂类
1 | public class ComputerFactory { |
- 它需要知道所有工厂类型,因此只适合工厂类负责创建的对象比较少的情况。
- 避免直接实例化类,降低耦合性。
- 增加新产品需要修改工厂,违背开放封闭原则。
工厂方法模式
定义一个用于创建对象的接口,使类的实例化延迟到子类。
工厂方法有以下角色:
- 抽象产品类。
- 具体产品类。
- 抽象工厂类:返回一个泛型的产品对象。
- 具体工厂类:返回具体的产品对象。
简单示例
抽象产品类和具体产品类同简单工厂一样。
3、抽象工厂类
1 | public abstract class ComputerFactory { |
4、具体工厂类
1 | public class GDComputerFactory extends ComputerFactory { |
- 相比简单工厂,如果我们需要新增产品类,无需修改工厂类,直接创建产品即可。
建造者模式
将一个复杂对象的构建和它的表示分离,使得同样的构建过程可以创建不同的表示。
建造者有以下角色:
- 导演类:负责安排已有模块的安装顺序,最后通知建造者开始建造。
- 建造者:抽象Builder类,用于规范产品的组建。
- 具体建造者:实现抽象Builder类的所有方法,并返回建造好的对象。
- 产品类。
简单示例
1、产品类
1 | public class Computer { |
2、抽象建造者
1 | public abstract class Builder { |
3、具体建造者
1 | public class MoonComputerBuilder extends Builder { |
4、导演类
1 | public class Director { |
- 屏蔽产品内部组成细节。
- 具体建造者类之间相互独立,容易扩展。
- 会产生多余的建造者对象和导演类。
代理模式
为其它对象提供一种代理以控制这个对象的访问。
代理模式中有以下角色:
抽象主题类:声明真实主题和代理的共同接口方法。
真实主题类。
代理类:持有对真实主题类的引用。
客户端类。
静态代理示例代码
1、抽象主题类
1 | public interface IShop { |
2、真实主题类
1 | public class JsonChao implements IShop { |
3、代理类
1 | public class Purchasing implements IShop { |
4、客户端类
1 | public class Clent { |
动态代理
在代码运行时通过反射来动态地生成代理类的对象,并确定到底来代理谁。
动态代理示例代码
在java的java.lang.reflect包下面提供了一个Proxy类和一个InvocationHandler接口,通过这个类和接口可以生成JDK动态代理类和动态代理对象。
InvocationHandler接口是给动态代理类实现的,负责处理被代理对象的操作的,而proxy是用来创建动态代理类实例对象的,因为只有得到了这个对象我们才能调用哪些需要代理的方法。
改写静态代理的代理类和客户端类,如下所示:
1、动态代理类
1 | public class DynamicPurchasing implements InvocationHandler { |
2、客户端类1
2
3
4
5
6
7
8
9
10public class Clent {
public static void main(String[] args) {
IShop jsonChao = new JsonChao();
DynamicPurchasing mDynamicPurchasing = new DynamicPurchasing(jsonChao);
ClassLoader cl = jsonChao.getClass.getClassLoader();
IShop purchasing = Proxy.newProxyInstance(cl, new Class[]{IShop.class}, mDynamicPurchasing);
purchasing.buy();
}
}
真实主题类发生变化时,由于它实现了公用的接口,因此代理类不需要修改。
装饰模式
动态地给一个对象添加一些额外的职责。
装饰模式有以下角色:
抽象组件:接口/抽象类,被装饰的最原始的对象。
具体组件:被装饰的具体对象。
抽象装饰者:扩展抽象组件的功能。
具体装饰者:装饰者具体实现类。
示例代码
1、抽象组件1
2
3public abstract class Swordsman {
public abstract void attackMagic();
}
2、具体组件1
2
3
4
5
6public class YangGuo extends Swordsman {
public void attackMagic() {
...
}
}
3、抽象装饰者
抽象装饰者必须持有抽象组件的引用,以便扩展功能。1
2
3
4
5
6
7
8
9
10
11public abstract class Master extends Swordsman {
private Swordsman swordsman;
public Master(Swordsman swordsman) {
this.swordman = swordman;
}
public void attackMagic() {
swordsman.attackMagic();
}
}
4、具体装饰者1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class HongQiGong extends Master {
public HongQiGong(Swordsman swordsman) {
this.swordsman = swordsman;
}
public void teachAttackMagic() {
...
}
public void attackMagic() {
super.attackMagic();
teackAttackMagic();
}
}
5、使用1
2
3YangGuo mYangGuo = new YangGuo();
HongQiGong mHongQiGong = new HongQiGong(mYangGuo);
mHongQiGong.attackMagic();
使用组合,动态地扩展对象的功能,在运行时能够使用不同的装饰器实现不同的行为。
比继承更易出错,旨在必要时使用。
外观模式(门面模式)
一个子系统的内部和外部通信必须通过一个统一的对象进行。即提供一个高层的接口,方便子系统更易于使用。
外观模式有以下角色:
- 外观类:将客户端的请求代理给适当的子系统对象。
- 子系统类:可以有一个或多个子系统,用于处理外观类指派的任务。注意子系统不含外观类的引用。
简单示例
1、子系统类(这个有三个子系统)
1 | public class ZhaoShi { |
2、外观类
1 | public class ZhangWuJi { |
3、使用
1 | ZhangWuJi zhangWuJi = new ZhangWuJi(); |
- 将对子系统的依赖转换为对外观类的依赖。
- 对外部隐藏子系统的具体实现。
- 这种外观特性增强了安全性。
享元模式
使用共享对象有效支持大量细粒度(性质相似)的对象。
额外的两个概念:
- 1、内部状态:共享信息,不可改变。
- 2、外部状态:依赖标记,可以改变。
享元模式有以下角色:
- 抽象享元角色:定义对象内部和外部状态的接口。
- 具体享元角色:实现抽象享元角色的任务。
- 享元工厂:管理对象池及创建享元对象。
简单示例
1、抽象享元角色
1 | public interface IGoods { |
2、具体享元角色
1 | public class Goods implements IGoods { |
3、享元工厂
1 | public class GoodsFactory { |
4、使用
1 | Goods goods1 = GoodsFactory.getGoods("Android进阶之光"); |
goods1为新创建的对象,后面的都是从对象池中取出的缓存对象。
适配器模式
将一个接口转换为另一个需要的接口。
适配器有以下角色:
- 要转换的接口。
- 要转换的接口的实现类。
- 转换后的接口。
- 转换后的接口的实现类。
- 适配器类。
简单示例
1、要转换的接口(火鸡)
1 | public interface Turkey { |
2、要转换的接口的实现类
1 | public class WildTurkey implements Turkey { |
3、转换后的接口(鸭子)
1 | public interface Duck { |
4、转换后的接口的实现类。
1 | public class MallardDuck implements Duck { |
5、适配器类
1 | public class TurkeyAdapter implements Duck { |
6、使用
1 | WildTurkey wildTurkey = new WildTurkey(); |
- 注重适度使用即可。
模板方法模式
定义了一套算法框架,将某些步骤交给子类去实现。使得子类不需改变框架结构即可重写算法中的某些步骤。
模板方法模式有以下角色:
- 抽象类:定义了一套算法框架。
- 具体实现类。
简单示例
1、抽象类
1 | public abstract class AbstractSwordsman { |
2、具体实现类
1 | public class ZhangWuJi extends AbstractSwordsman { |
3、使用
1 | ZhangWuJi zhangWuJi = new ZhangWuJi(); |
- 可以使用hook方法实现子类对父类的反向控制。
- 可以把核心或固定的逻辑搬移到基类,其它细节交给子类实现。
- 每个不同的实现都需要定义一个子类,复用性小。
观察者模式(发布 - 订阅模式)
定义对象间的一种1对多的依赖关系,每当这个对象的状态改变时,其它的对象都会接收到通知并被自动更新。
观察者模式有以下角色:
- 抽象被观察者:将所有已注册的观察者对象保存在一个集合中。
- 具体被观察者:当内部状态发生变化时,将会通知所有已注册的观察者。
- 抽象观察者:定义了一个更新接口,当被观察者状态改变时更新自己。
- 具体被观察者:实现抽象观察者的更新接口。
简单示例
1、抽象观察者
1 | public interface observer { |
2、具体观察者
1 | public class WeXinUser implements observer { |
3、抽象被观察者
1 | public interface observable { |
4、具体被观察者
1 | public class Subscription implements observable { |
5、使用
1 | Subscription subscription = new Subscription(); |
- 实现了观察者和被观察者之间的抽象耦合,容易扩展。
- 有利于建立一套触发机制。
- 一个被观察者卡顿,会影响整体的执行效率。采用异步机制可解决此类问题。
策略模式
定义:将一组算法封装到鞠具有共同接口的独立的类中。
类图: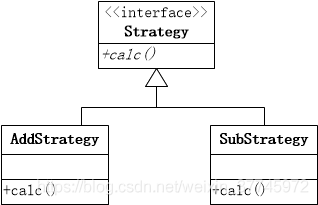
(1)实现Strategy接口
1 | public interface Strategy { |
(2)实现AddStrategy
1 | public class AddStrategy implements Strategy{ |
(3)实现SubStrategy
1 | public class SubStrategy implements Strategy { |
(4)新建测试类
1 | public class testStrategy { |
委托模式
两个对象参与处理同一个请求,接受请求的对象将请求委托给另一个对象来处理。
简单委托模式实现:
(1)新建RealPrinter
1 | public class RealPrinter { |
(2)新建Printer类
1 | public class Printer { |
(3)新建Test类
1 | public class Test { |
组件化基础
认识组件化
多module划分为业务和基础功能
- 组件:指的是单一的功能组件,如视频组件(VideoSDK)、支付组件(PaySDK)、路由组件(Router)等,每个组件都能单独抽出来制作成SDK。
- 模块: 指的是独立的业务模块,如直播模块(LiveModule)、首页模块(HomeModule)、即时通信模块(IMModule)等。模块相对于组件来说粒度更大,模块可能包含多种不同的组件。
组件化开发的好处:
- 避免重复造轮子,可以节省开发和维护的成本。
- 可以通过组件和模块为业务基准合理地安排人力,提高开发效率。
- 不同的项目可以共用一个组件或模块,确保整体技术方案的统一性。
- 为未来插件化共用同一套底层模型做准备。
模块化开发的好处:
- 业务模块的解耦,业务移植更加简单。
- 多团队根据业务内容进行并行开发和测试。
- 单个业务可以单独编译打包,加快编译速度。
- 多个App共用模块,降低了研发和维护成本。
两者的缺点:
- 旧项目重新适配组件化的开发需要相应的人力及时间成本。
两者的本质思想:
- 代码重用和业务解耦。
区别:
- 模块化是业务导向,组件化是功能导向。
引申:
项目方法数超过65535个时的解决方案:
- MultiDex分包。
- 插件化。
依赖
AS独有的三种依赖方式:
Jar dependency: 通过Gradle配置引入lib文件夹中的所有.jar后缀的文件,还能引用.aar后缀的文件。
Base module: 对应的是module dependency,实质上是将其打包成aar文件,方便其他库进行依赖。
Library dependency: 第三方依赖通过其完成仓库索引依赖,仓库包含网络仓库和本地库。
dependencies { compile fileTree(include:[‘*.jar’], dir: ‘libs’) compile project(‘:base’) annotationProcessor ‘com.alibaba:arouter-compiler:1.1.1’ }
一般情况下,AS定义使用dependencies包含全部资源引入。
注意:
- 读入自身目录使用的是fileTree。
- 读入其他资源module使用的是”project“字段,而”:base“中冒号的意思是文件目录内与自己相同层级的其他module。
聚合和解耦
- AS正是以依赖的方式给每个module之间提供了沟通和交流的渠道,从而形成聚合。
- 聚合和解耦是项目架构的基础。
- 组件化架构就是在文件层级上有效地控制沟通和个体独立性的做法。
重新认识AndroidManifest
问题:每个module都有一份配合的AndroidManifest文件来记载其信息,最终生成一个App的时候,其只有一份AndroidManifest来指导App应该如何配置,那么如何记录这么多个module独立的配置信息呢?
答案:将多个AndroidManifest合成一个
合成的生成地址目录为app/build/intermediates/manifest/full/debug/AndroidManifest.xml, intermediates文件夹包含的是App生成过程中产生的“中间文件”。
AndroidManifest属性变更
1.注册Activity
1 | <application |
name需要具体包名+属性名,这是因为AndroidManifest会引用多个module中的文件,需要知道具体路径,不然在编译期打包时会找不到每个文件的具体位置。
2.注册Application
如果功能module中有两个自定义Application,在解决冲突后,Application最终会载入后编译的module的Application。
3.权限声明
- 如果在一个功能module中声明所需要的权限,那么在主module中就会看到相应的权限。
- 如果在其他module中都声明相同的权限,最终的AndroidManifest会合并这个重复声明的权限,所以相同的权限只会声明一次。
- 如果考虑最终权限有可能被遗漏的问题,可以将全部的权限都在Base module中声明,这样全部权限都是有的。
4.shareUid
通过声明Shared User id,拥有同一个User id的多个App可以配置成运行在同一个进程中,所以默认可以互相访问任意数据。
问题:如果只是在功能module中声明shareUid,那么最终的AndroidManifest会如何呢?
答案:只有在主module(Application module)中声明sharedUserId,才会最终打包到full AndroidManifest中。
注意:
- 每个module打包aar时都会将versionCode和versionName补全。
你所不知道的Application
Applicaiton的基础和作用
Application是整个App的一个单例对象,并且其生命周期是最长的,相当于整个App的生命周期。
Application中比较重要的方法:
- onTerminate——当终止应用程序对象时调用,不保证一定被调用,当程序被内核终止以便为其他应用程序释放资源时将不会提醒,并且不调用应用程序对象的onTerminate方法而直接终止进程。
- onLowMemory——当后台程序已经终止且资源还匮乏时会调用这个方法。好的应用程序会在此释放资源。
Applicaiton提供的最好用的方法:
- registerActivityLifecycleCallbacks()和unregisterActivityLifecycleCallbacks()。
作用:用于注册或注销对App内所有Activity的生命周期监听。
组件化Application
如果Library项目中也定义了与主项目相同的属性(例如默认生成的android:icon 和android:theme),则此时会合并失败。
解决方式:使用tools:replace=“android:name”来声明Application是可被替换的。
在full文件夹中的AndroidManifest查看最终编入的是哪个Application。
Jetpack
- 带你领略Android Jetpack组件的魅力
- Android Jetpack 架构组件之 Lifecycle(使用篇)
- Android Jetpack 架构组件之 Lifecycle(源码篇)
- Android Jetpack 架构组件之 ViewModel (源码篇)
- Android Jetpack 架构组件之 LiveData(使用、源码篇)
- Android Jetpack架构组件之 Paging(使用、源码篇)
- Android Jetpack 架构组件之 Room(使用、源码篇)
- Android Jetpack 架构组件之Navigation
- Android Jetpack架构组件之WorkManger
- 实战:从0搭建Jetpack版的WanAndroid客户端
大鱼吃小鱼
给一个整型数组,从左到右大的数字会把它右边第一个小的数字吃掉,给出最后稳定下来的结果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20private static int[] a(int[] fishes) {
if (fishes == null || fishes.length == 0) {
return null;
}
int cnt = 0;
int i = 0,len = fishes.length;
while (i < len) {
int j = i + 1;
while (j < len && fishes[j] < fishes[i]) {
j++;
}
if(j == len) {
break;
}
fishes[cnt + 1] = fishes[j];
cnt++;
i = j;
}
return Arrays.copyOfRange(fishes,0,cnt + 1);
}
生产者消费者模型
1 | import java.util.ArrayList; |
1 | package javacourse.ch30; |
其实也可以用阻塞队列实现
阻塞队列的特点:
- 当队列元素已满的时候,阻塞插入操作
- 当队列元素为空的时候,阻塞获取操作
不同的阻塞队列:
ArrayBlockingQueue 与 LinkedBlockingQueue 都是支持 FIFO (先进先出),但是 LinkedBlockingQueue 是无界的,而ArrayBlockingQueue 是有界的。
演示
还是设置生产者生产速度大于消费者消费速度(通过 sleep() 方法实现)
缓冲区 BlockQueueBufferArea.java:
1 | public class BlockQueueBufferArea { |
生产者 Producer.java:
1 | public class Producer extends Thread { |
消费者 Consumer.java:
1 | public class Consumer extends Thread { |
测试 Test.java:
1 | public class Test { |
打印结果如下:
1 | Producer_Thread-5产品池被放入了一个资源 |
简述GC过程,object类的finalize()方法是如何影响GC的
基本预备相关知识
1 java的GC只负责内存相关的清理,所有其它资源的清理必须由程序员手工完成。要不然会引起资源泄露,有可能导致程序崩溃。
2 调用GC并不保证GC实际执行。
3 finalize抛出的未捕获异常只会导致该对象的finalize执行退出。
4 用户可以自己调用对象的finalize方法,但是这种调用是正常的方法调用,和对象的销毁过程无关。
5 JVM保证在一个对象所占用的内存被回收之前,如果它实现了finalize方法,则该方法一定会被调用。Object的默认finalize什么都不做,为了效率,GC可以认为一个什么都不做的finalize不存在。
6 对象的finalize调用链和clone调用链一样,必须手工构造。
1 | protected void finalize() throws Throwable { |
finalize的作用
- finalize()是Object的protected方法,子类可以覆盖该方法以实现资源清理工作,GC在回收对象之前调用该方法。
- finalize()与C++中的析构函数不是对应的。C++中的析构函数调用的时机是确定的(对象离开作用域或delete掉),但Java中的finalize的调用具有不确定性
- 不建议用finalize方法完成“非内存资源”的清理工作,但建议用于:① 清理本地对象(通过JNI创建的对象);② 作为确保某些非内存资源(如Socket、文件等)释放的一个补充:在finalize方法中显式调用其他资源释放方法。其原因可见下文[finalize的问题]
- 当对象不再被任何对象引用时,GC会调用该对象的finalize()方法
- 可以在finalize()让这个对象再次被引用,避免被GC回收;但是最常用的目的还是做cleanup
- Java不保证这个finalize()一定被执行;但是保证调用finalize的线程没有持有任何user-visible同步锁。
- 在finalize里面抛出的异常会被忽略,同时方法终止。
- 当finalize被调用之后,JVM会再一次检测这个对象是否能被存活的线程访问得到,如果不是,则清除该对象。也就是finalize只能被调用一次;也就是说,覆盖了finalize方法的对象需要经过两个GC周期才能被清除。
finalize的问题
- 一些与finalize相关的方法,由于一些致命的缺陷,已经被废弃了,如System.runFinalizersOnExit()方法、Runtime.runFinalizersOnExit()方法
- System.gc()与System.runFinalization()方法增加了finalize方法执行的机会,但不可盲目依赖它们
- Java语言规范并不保证finalize方法会被及时地执行、而且根本不会保证它们会被执行
- finalize方法可能会带来性能问题。因为JVM通常在单独的低优先级线程中完成finalize的执行
- 对象再生问题:finalize方法中,可将待回收对象赋值给GC Roots可达的对象引用,从而达到对象再生的目的
- finalize方法至多由GC执行一次(用户当然可以手动调用对象的finalize方法,但并不影响GC对finalize的行为)
对象的销毁过程
在对象的销毁过程中,按照对象的finalize的执行情况,可以分为以下几种,系统会记录对象的对应状态:
unfinalized 没有执行finalize,系统也不准备执行。
finalizable 可以执行finalize了,系统会在随后的某个时间执行finalize。
finalized 该对象的finalize已经被执行了。
GC怎么来保持对finalizable的对象的追踪呢。GC有一个Queue,叫做F-Queue,所有对象在变为finalizable的时候会加入到该Queue,然后等待GC执行它的finalize方法。
这时我们引入了对对象的另外一种记录分类,系统可以检查到一个对象属于哪一种。
reachable 从活动的对象引用链可以到达的对象。包括所有线程当前栈的局部变量,所有的静态变量等等。
finalizer-reachable 除了reachable外,从F-Queue可以通过引用到达的对象。
unreachable 其它的对象。
具体的finalize流程:
对象可由两种状态,涉及到两类状态空间,一是终结状态空间 F = {unfinalized, finalizable, finalized};二是可达状态空间 R = {reachable, finalizer-reachable, unreachable}。各状态含义如下:
- unfinalized: 新建对象会先进入此状态,GC并未准备执行其finalize方法,因为该对象是可达的
- finalizable: 表示GC可对该对象执行finalize方法,GC已检测到该对象不可达。正如前面所述,GC通过F-Queue队列和一专用线程完成finalize的执行
- finalized: 表示GC已经对该对象执行过finalize方法
- reachable: 表示GC Roots引用可达
- finalizer-reachable(f-reachable):表示不是reachable,但可通过某个finalizable对象可达
- unreachable:对象不可通过上面两种途径可达
变迁说明:
- 新建对象首先处于[reachable, unfinalized]状态(A)
- 随着程序的运行,一些引用关系会消失,导致状态变迁,从reachable状态变迁到f-reachable(B, C, D)或unreachable(E, F)状态
- 若JVM检测到处于unfinalized状态的对象变成f-reachable或unreachable,JVM会将其标记为finalizable状态(G,H)。若对象原处于[unreachable, unfinalized]状态,则同时将其标记为f-reachable(H)。
- 在某个时刻,JVM取出某个finalizable对象,将其标记为finalized并在某个线程中执行其finalize方法。由于是在活动线程中引用了该对象,该对象将变迁到(reachable, finalized)状态(K或J)。该动作将影响某些其他对象从f-reachable状态重新回到reachable状态(L, M, N)
- 处于finalizable状态的对象不能同时是unreahable的,由第4点可知,将对象finalizable对象标记为finalized时会由某个线程执行该对象的finalize方法,致使其变成reachable。这也是图中只有八个状态点的原因
- 程序员手动调用finalize方法并不会影响到上述内部标记的变化,因此JVM只会至多调用finalize一次,即使该对象“复活”也是如此。程序员手动调用多少次不影响JVM的行为
- 若JVM检测到finalized状态的对象变成unreachable,回收其内存(I)
- 若对象并未覆盖finalize方法,JVM会进行优化,直接回收对象(O)
- 注:System.runFinalizersOnExit()等方法可以使对象即使处于reachable状态,JVM仍对其执行finalize方法
1 | package com.Leetcode.coding; |
给定一个有序的整型数组和一个数c,从里面选定两个数x、y,使得x+y<=c且x+y尽可能的大
先用二分法找到小于等于c的最大位置,接着按两数之和做。
1 | private static int[] b(int[] nums, int y) { |
anr异常、oom异常、UI卡顿
ANR(Application Not Responding)
ANR定义: 在Android上,如果你的应用程序有一段时间内响应不够灵敏,系统会向用户显示一个对话框,这个对话框称作为应用程序无响应(ANR: Application Not Responding)对话框.用户可以选择”等待”而让程序继续运行,也可以选择”强制关闭”.所以一个流畅的合理的应用程序中不能出现ANR,而让用户每次都要处理这个对话框.因此,在程序里对响应性能的设计很重要,这样系统不会显示ANR给用户.
默认情况下,在Android中Activity的最长执行时间是5秒,BroadcastReceiver的最长执行时间则是10秒.
在Android里,应用程序的响应性是由Activity Manager和WindowManager系统服务监视的 。当它监测到以下情况中的一个时,Android就会针对特定的应用程序显示ANR:
- 在5秒内没有响应输入的事件(例如,按键按下,屏幕触摸)
- BroadcastReceiver在10秒内没有执行完毕
造成以上两点的原因有很多,比如在主线程中做了非常耗时的操作,比如说是下载,io异常等。
潜在的耗时操作,例如网络或数据库操作,或者高耗时的计算如改变位图尺寸,应该在子线程里(或者以数据库操作为例,通过异步请求的方式)来完成。而不是说你的主线程阻塞在那里等待子线程的完成——也不是调用 Thread.wait()或是Thread.sleep()。替代的方法是,主线程应该为子线程提供一个Handler,以便完成时能够提交给主线程。以这种方式设计你的应用程序,将能保证你的主线程保持对输入的响应性并能避免由于5秒输入事件的超时引发的ANR对话框。
造成原因
a)主线程被IO操作(从4.0之后网络IO不允许在主线程中)阻塞。
b)主线程中存在耗时的计算。
c)哪些操作是在主线程:
Activity的所有生命周期回调都是执行在主线程的;
Service默认是执行在主线程的;
BroadcastReceiver的onReceive回掉是执行在主线程的;
没有使用子线程的looper的Hander的handleMessage,post(Runnable)是执行在主线程的;
3 如何解决
- 运行在主线程里的任何方法都尽可能少做事情。特别是,Activity应该在它的关键生命周期方法(如onCreate()和onResume())里尽可能少的去做创建操作。(可以采用重新开启子线程的方式,然后使用Handler+Message的方式做一些操作,比如更新主线程中的ui等)
- 应用程序应该避免在BroadcastReceiver里做耗时的操作或计算。但不再是在子线程里做这些任务(因为 BroadcastReceiver的生命周期短),替代的是,如果响应Intent广播需要执行一个耗时的动作的话,应用程序应该启动一个 Service。(此处需要注意的是可以在BroadcastReceiver中启动Service,但是却不可以在Service中启动BroadcastReceiver)
- 避免在Intent Receiver里启动一个Activity,因为它会创建一个新的画面,并从当前用户正在运行的程序上抢夺焦点。如果你的应用程序在响应Intent广播时需要向用户展示什么,你应该使用Notification Manager来实现。
- 使用Thread或者HandlerThread提高优先级。
OOM(Out Of Memory)
当前占用的内存加上我们申请的内存资源超过了Dalvik虚拟机的最大内存限制就会跑出的Out of memory异常。即:
一、加载对象过大
二、相应资源过多,没有来不及释放。
容易混淆的
a)内存溢出:oom。
b)内存抖动:短时间内大量的对象被创建,然后被马上释放。瞬间产生的对象会严重占用内存区。
c)内存泄露:进程中的某些内容没有被其他引用到了,但会直接或间接引用到(其他还没有被回收的对象),导致GC无法回收。
3 如何解决
在内存引用上做些处理,常用的有软引用、强化引用、弱引用
在内存中加载图片时直接在内存中做处理,如:边界压缩.
优化Dalvik虚拟机的堆内存分配
对于Android平台来说,其托管层使用的Dalvik JavaVM从目前的表现来看还有很多地方可以优化处理,比如我们在开发一些大型游戏或耗资源的应用中可能考虑手动干涉GC处理,使用dalvik.system.VMRuntime类提供的setTargetHeapUtilization方法可以增强程序堆内存的处理效率。当然具体原理我们可以参考开源工程,这里我们仅说下使用方法: private final static floatTARGET_HEAP_UTILIZATION = 0.75f; 在程序onCreate时就可以调用VMRuntime.getRuntime().setTargetHeapUtilization(TARGET_HEAP_UTILIZATION);即可。
自定义堆内存大小
对于一些Android项目,影响性能瓶颈的主要是Android自己内存管理机制问题,目前手机厂商对RAM都比较吝啬,对于软件的流畅性来说RAM对性能的影响十分敏感,除了 优化Dalvik虚拟机的堆内存分配外,我们还可以强制定义自己软件的对内存大小,我们使用Dalvik提供的dalvik.system.VMRuntime类来设置最小堆内存为例:
private final static int CWJ_HEAP_SIZE = 6 1024 1024 ;
VMRuntime.getRuntime().setMinimumHeapSize(CWJ_HEAP_SIZE); //设置最小heap内存为6MB大小。当然对于内存吃紧来说还可以通过手动干涉GC去处理注意了,这个设置dalvik虚拟机的配置的方法对Android4.0 设置无效。
动态内存管理
bitmap显示缩略图,不要网络请求去加载大图;
ListView监听滑动事件,在滑动的时候不去调用网络请求;
及时释放内存;
图片压缩,http://blog.csdn.net/harryweasley/article/details/51955467
inBitmap属性,提高安卓系统在Bitmap分配和释放的执行效率;
避免在onDraw方法里执行对象的创建;
谨慎使用多进程;
UI卡顿
1 原理
a)60fps ———> 16ms
b)overdraw 过度绘制,一针绘制好多次。
* 手机GPU选项,减少红色,尽量出现蓝色;
* UI布局中有大量重叠的部分,还有一些非必要重叠部分,比如:布局文件layout有背景,里面的布局文件也有自己的背景,这时候,仅仅移除非必须的背景图片,就能减少红色焦区;
2 原因分析
a)人为在UI线程中做轻微耗时操作,导致UI线程卡顿;
b)布局Layout过于复杂,无法在16ms内完成渲染;
c)统一时间动画执行次数过多,导致CPU或GPU负载过重;
d)View过度绘制,导致某些像素在同一帧时间内被绘制多次,从而使CPU或GPU负载过重;
e)View频繁的触发measure、layout,导致measure、layout累计耗时过多,及整个View频繁的重新渲染;
f)内存频繁触发GC过多,导致暂时阻塞渲染操作;
g)沉余资源及逻辑等导致加载和执行缓慢;
h)ANR;
3 总结
a)布局优化.
b)列表及Adapter优化.
c)背景和图片等内存分配优化.
d)避免ANR.卡顿、死锁性能优化
bitmap优化
- recycle 回收;
LRU(Least Recently Used)缓存:当缓存满时,优先淘汰即删除近期最少使用的缓存对象。
计算inSampleSize:是调整Bitmap压缩比例的,该值必须>=1,比如inSampleSize = 2,那么Bitmap的宽和高都变为原来的1/2。
缩略图。
三级缓存:网络、本地、内存。
Bitmap.compress方法压缩图片:
1 | ByteArrayOutputStream baos = new ByteArrayOutputStream(); |
- 采样率压缩
1 | BitmapFactory.Options options = new BitmapFactory.Options(); |
设置inSampleSize的值(int类型)后,假如设为2,则宽和高都为原来的1/2,宽高都减少了,自然内存也降低了。
我上面的代码没用过options.inJustDecodeBounds = true; 因为我是固定来取样的数据,为什么这个压缩方法叫采样率压缩,是因为配合inJustDecodeBounds,先获取图片的宽、高【这个过程就是取样】,然后通过获取的宽高,动态的设置inSampleSize的值。
当inJustDecodeBounds设置为true的时候,BitmapFactory通过decodeResource或者decodeFile解码图片时,将会返回空(null)的Bitmap对象,这样可以避免Bitmap的内存分配,但是它可以返回Bitmap的宽度、高度以及MimeType。
Matrix缩放
1
2
3
4
5
6Matrix matrix = new Matrix();
matrix.setScale(0.5f, 0.5f);
bm = Bitmap.createBitmap(bit, 0, 0, bit.getWidth(),
bit.getHeight(), matrix, true);
Log.i("wechat", "压缩后图片的大小" + (bm.getByteCount() / 1024 / 1024)
+ "M宽度为" + bm.getWidth() + "高度为" + bm.getHeight());RGB565
1
2
3
4
5
6
7
8BitmapFactory.Options options2 = new BitmapFactory.Options();
options2.inPreferredConfig = Bitmap.Config.RGB_565;
bm = BitmapFactory.decodeFile(Environment
.getExternalStorageDirectory().getAbsolutePath()
+ "/DCIM/Camera/test.jpg", options2);
Log.i("wechat", "压缩后图片的大小" + (bm.getByteCount() / 1024 / 1024)
+ "M宽度为" + bm.getWidth() + "高度为" + bm.getHeight());createScaledBitmap
1
2
3bm = Bitmap.createScaledBitmap(bit, 150, 150, true);
Log.i("wechat", "压缩后图片的大小" + (bm.getByteCount() / 1024) + "KB宽度为"
+ bm.getWidth() + "高度为" + bm.getHeight());options.inJustDecodeBounds = true 表示只读图片,不加载到内存中,设置这个参数为ture,就不会给图片分配内存空间,但是可以获取到图片的大小等属性; 设置为false, 就是要加载这个图片.
1
2
3
4
5
6
7
8
9
10
11
12
13
14public static Bitmap decodeSampledBitmapFromResource(Resources res, int resId, int reqWidth, int reqHeight) {
// 先把inJustDecodeBounds设置为true 取得原始图片的属性
final BitmapFactory.Options options = new BitmapFactory.Options();
options.inJustDecodeBounds = true;
BitmapFactory.decodeResource(res, resId, options);
// 然后算一下我们想要的最终的属性
options.inSampleSize = calculateInSampleSize(options, reqWidth, reqHeight);
// 在decode的时候 别忘记直接 把这个属性改为false 否则decode出来的是null
options.inJustDecodeBounds = false;
return BitmapFactory.decodeResource(res, resId, options);
}- 读bitmaphttps://blog.csdn.net/zanelove/article/details/44278783
1
2
3
4
5
6
7
8
9public static Bitmap readBitMap(Context context, int resId){
BitmapFactory.Options opt = new BitmapFactory.Options();
opt.inPreferredConfig = Bitmap.Config.RGB_565;
opt.inPurgeable = true;
opt.inInputShareable = true;
//获取资源图片
InputStream is = context.getResources().openRawResource(resId);
return BitmapFactory.decodeStream(is,null,opt);
}
JNI
JNI是Java Native Interface的缩写,它提供了若干的API实现了Java和其他语言的通信(主要是C&C++).这是百度百科上说的.通俗来说,就是JAVA调用C/C++函数的接口.如果你要想调用C系列的函数,你就必须遵守这样的约定.
1 | public class NativeDemo { |
wait方法和notify的区别
调用sleep方法可以让当前正在运行的线程进入睡眠状态,即暂时停止运行指定的单位时间。并且该线程在睡眠期间不会释放对象锁。
sleep方法的目的是让当前线程暂停运行一段时间,而与对象锁相关的信息无影响,如果执行sleep方法时是处于持有对象锁的状态,那么睡眠时依然持有对象锁,如果执行sleep方法时不是处于持有对象锁的状态,睡眠期间也不会持有对象锁。
调用wait方法可以让当前线程(即调用object.wait方法的那个线程)进入等待唤醒状态,该线程会处于等待唤醒状态直到另一个线程调用了object对象的notify方法或者notifyAll方法。该方法没有形参,相当于调用了参数为0的wait(long timeout)方法。
同时,要调用wait方法,前提是获取了这个对象的锁。在调用wait方法时,线程会释放锁并进入等待状态。在被唤醒后,该线程会一直处于等待获取锁的状态直到它重新获取到锁,然后才可以重新恢复运行状态。
注释也强调了,该方法应该只在获取了对象的锁之后才去调用,即wait方法应该放在synchronized(obj){}块中,否则运行期间会抛出IllegalMonitorStateException异常。
举例来解释,比方说多线程下,object对象是共享对象,那么对object对象的操作可以放在synchronized(object)同步块中,当线程A在同步块中执行object.wait方法,线程A就进入了等待状态。这时在线程Q中的同步块中执行object.notify(),就能唤醒线程A。另一种情形,假如线程ABC都执行了object.wait方法,那么当线程Q中执行了object.notify(),则只能唤醒其中一个,至于具体是哪一个,是任意的。
调用notify唤醒的线程,处于等待获取锁状态,且这个被唤醒的线程,相对于其他在等待获取锁的线程,没有任何特权,也没有任何劣势,即公平竞争。
如注释中所描述,同步块,可以是对共享对象进行同步处理,也可以直接对实例方法进行同步处理,还可以对类进行同步处理。
如果,当前调用notify方法的线程没有获取对象锁,则将抛出IllegalMonitorStateException异常。
notifyAll方法与notify方法很类似,不同之处是notify方法唤醒任意一个线程而notifyAll方法唤醒的是所有线程。
wait方法和sleep方法的对比
- 正如方法定义所描述,这两个方法都是native方法,且都会抛出InterruptedException,其中sleep方法是类方法,而wait方法是实例方法。
- sleep方法是Thread类的方法,而wait方法是Object类的方法,由于一切类都是继承自Object类,因此Thread类中也有wait方法。
- wait方法和sleep方法都可以通过interrupt方法打断线程的暂停状态,从而使得线程立刻抛出IntterruptedException。
- sleep方法的作用是让当前线程暂停指定的时间,无关对象锁;而wait方法则是用于多个线程间的信息交互,与对象锁有关。
- sleep方法是类方法,而锁是对象级别的。因此sleep方法并不影响锁的相关行为。因此如果在调用sleep方法时该线程是处理持有对象锁的状态,睡眠状态中仍然持有锁。而wait方法能安全使用的前提是获取了对象锁,wait方法之所以可以用于多个线程间的信息交流,正是它会释放对象锁。
- 这里引用知乎用户“孙立伟”的一段话:Thread.sleep和Object.wait都会暂停当前的线程,对于CPU资源来说,不管是哪种方式暂停的线程,都表示它暂时不再需要CPU的执行时间。操作系统会将执行时间分配给其它线程。区别是,调用wait后,需要别的线程执行notify/notifyAll才能够重新获得CPU执行时间。
为什么wait方法在Object对象中?
简单说:因为synchronized中的这把锁可以是任意对象,所以任意对象都可以调用wait()和notify();所以wait和notify属于Object。
专业说:因为这些方法在操作同步线程时,都必须要标识它们操作线程的锁,只有同一个锁上的被等待线程,可以被同一个锁上的notify唤醒,不可以对不同锁中的线程进行唤醒。
也就是说,等待和唤醒必须是同一个锁。而锁可以是任意对象,所以可以被任意对象调用的方法是定义在object类中。
recyclerView的复用机制 和listView的区别
可直接参考掘金
ListView
1.Adapter继承的是BaseAdapter。
2.可以直接在布局中设置分割线。
3.点击事件自带setOnItemClickListener方法
4.自带增加头部尾部方法 addHeaderView和addFooterView
5.ListView只有刷新所有数据的方法,局部刷新需自己定义
6.没有动画效果
7.缓存机制原理大致相同(缓存层级不同,获取缓存流程不同)
RecyclerView
1.Adapter继承的是RecyclerView.Adapter
2.不能在布局中直接设置分割线,可以自定义,在setAdapter之前添加分割线
3.RecyclerView提供addOnItemTouchListener监听item的触摸事件,通过addOnItemTouchListener加上Gesture Detector来实现item响应方法(也可以自定义方法进行处理)
4.RecyclerView需要借助Adapter实现头尾布局,通过设置ViewHolder不同的类型实现
5.RecyclerView可以调用notifyItemChanged实现局部刷新
6.RecyclerView自带动画效果,如果需要自定义动画可通过自定义RecyclerView.ItemAnimator类,然后调用setItemAnimator设置
7.缓存机制原理大致相同(缓存层级不同,获取缓存流程不同)
RecyclerView 优化
1.布局优化
减少层次结构、减少过渡绘制,可以提高item的解析测量与绘制的效率
2.关闭动画效果
如果不需要动画效果,可以取消RecyclerView的默认动画 mRecyclerView.setItemAnimator(null);
3.Item等高
把所有的 Item 的高度固定大小,这样可以减少测量次数,尤其是对于 GridLayoutManager。
mRecyclerView.setHasFixedSize(true);
4.使用getExtraLayoutSpace为LayoutManager设置更多的预留空间
当item布局内容比较高,屏幕内只能展示一条item或者说一条显示都不全的时候,第一次滑动到第二个元素就会卡顿。
RecyclerView (以及其他基于adapter的view,比如ListView、GridView等)使用了缓存机制重用子 view(即系统只将屏幕可见范围之内的元素保存在内存中,在滚动的时候不断的重用这些内存中已经存在的view,而不是新建view)。
这个机制会导致一个问题,启动应用之后,在屏幕可见范围内,如果只有一张卡片可见,当滚动的时 候,RecyclerView找不到可以重用的view了,它将创建一个新的,因此在滑动到第二个feed的时候就会有一定的延时,但是第二个feed之 后的滚动是流畅的,因为这个时候RecyclerView已经有能重用的view了。
如何解决这个问题呢,其实只需重写getExtraLayoutSpace()方法。根据官方文档的描述 getExtraLayoutSpace将返回LayoutManager应该预留的额外空间(显示范围之外,应该额外缓存的空间)。
5.RecycledViewPool
当多个RecyclerView有相同的item布局结构时,多个RecyclerView共用一个RecycledViewPool可以避免创建ViewHolder的开销,避免GC。RecycledViewPool对象可通过RecyclerView对象获取,也可以自己实现。
6.避免创建过多对象
onCreateViewHolder 和 onBindViewHolder 对时间都比较敏感,尽量避免繁琐的操作和循环创建对象。例如创建 OnClickListener,可以全局创建一个,然后数据通过 itemView.setTag 携带。
7.局部刷新
可以用一下一些方法,替代notifyDataSetChanged,已达到局部刷新的目的。
notifyItemChanged(int position)
notifyItemInserted(int position)
notifyItemRemoved(int position)
notifyItemMoved(int fromPosition, int toPosition)
notifyItemRangeChanged(int positionStart, int itemCount)
notifyItemRangeInserted(int positionStart, int itemCount)
notifyItemRangeRemoved(int positionStart, int itemCount)
如果必须用 notifyDataSetChanged(),那么最好设置 mAdapter.setHasStableIds(true)
8.重写onSroll事件
对于大量图片的RecyclerView,滑动暂停后再加载;RecyclerView中存在几种绘制复杂,占用内存高的楼层类型,但是用户只是快速滑动到底部,并没有必要绘制计算这几种复杂类型,所以也可以考虑对滑动速度,滑动状态进行判断,满足条件后再加载这几种复杂的。
RecyclerView
RecyclerView 基础使用关键点同样有两点:
继承重写 RecyclerView.Adapter 和 RecyclerView.ViewHolder
设置布局管理器,控制布局效果
1 | // 第一步:继承重写 RecyclerView.Adapter 和 RecyclerView.ViewHolder |
在最开始就提到,RecyclerView 能够支持各种各样的布局效果,这是 ListView 所不具有的功能,那么这个功能如何实现的呢?其核心关键在于 RecyclerView.LayoutManager 类中。从前面的基础使用可以看到,RecyclerView 在使用过程中要比 ListView 多一个 setLayoutManager 步骤,这个 LayoutManager 就是用于控制我们 RecyclerView 最终的展示效果的。
而 LayoutManager 只是一个抽象类而已,系统已经为我们提供了三个相关的实现类LinearLayoutManager(线性布局效果)、GridLayoutManager(网格布局效果)、StaggeredGridLayoutManager(瀑布流布局效果)。如果你想用 RecyclerView 来实现自己 YY 出来的一种效果,则应该去继承实现自己的 LayoutManager,并重写相应的方法,而不应该想着去改写 RecyclerView。关于 LayoutManager 的使用有下面一些常见的 API(有些在 LayoutManager 实现的子类中)
1 | canScrollHorizontally();//能否横向滚动 |
Runnable和Callable
Java多线程有两个重要的接口,Runnable和Callable,分别提供一个run方法和call方法,二者是有较大差异的。
1)Runnable提供run方法,无法通过throws抛出异常,所有CheckedException必须在run方法内部处理。Callable提供call方法,直接抛出Exception异常。
2)Runnable的run方法无返回值,Callable的call方法提供返回值用来表示任务运行的结果
3)Runnable可以作为Thread构造器的参数,通过开启新的线程来执行,也可以通过线程池来执行。而Callable只能通过线程池执行。
Callable任务通过线程池的submit方法提交。且submit方法返回Future对象,通过Future的get方法可以获得具体的计算结果。而且get是个阻塞的方法,如果任务未执行完,则一直等待。
1 | class IntegerCallableTask implements Callable<Integer> { |
execute和submit
execute和submit都属于线程池的方法,execute只能提交Runnable类型的任务,而submit既能提交Runnable类型任务也能提交Callable类型任务。
execute会直接抛出任务执行时的异常,submit会吃掉异常,可通过Future的get方法将任务执行时的异常重新抛出。
execute所属顶层接口是Executor,submit所属顶层接口是ExecutorService,实现类ThreadPoolExecutor重写了execute方法,抽象类AbstractExecutorService重写了submit方法。
怎么终止线程池?
shutdown()和shutdownNow()
shutdown与shutdownNow有什么区别?
shutdown会把线程池的状态改为SHUTDOWN,而shutdownNow把当前线程池状态改为STOP
shutdown只会中断所有空闲的线程,而shutdownNow会中断所有的线程。
shutdown返回方法为空,会将当前任务队列中的所有任务执行完毕;而
shutdownNow把任务队列中的所有任务都取出来返回。
类加载机制
JVM的类加载机制的五个阶段
加载:读取class文件,并根据class文件描述创建java.lang.Class对象的过程
验证:确保Class文件符合当前虚拟机的要求,保障虚拟机自身的安全
准备:在方法区中为类变量分配内存并设置类中变量的初始值
解析:将常量池中的符号引用替换为直接引用
初始化:执行类构造器的< client>方法为类进行初始化
类加载器有哪几种?
启动类加载器:负责加载Java_HOME/lib目录中的类库
扩展类加载器:负责加载Java_HOME/lib/ext目录中的类库
应用程序类加载器:负责加载用户路径(classpath)上的类库
此外,我们还可以通过继承java.lang.ClassLoader实现自定义加载器
常见布局
LinearLayout:线性布局,在某一方向上一次排列内部视图
RelativeLayout:相对布局,默认是FrameLayout,可以取一个控件作为参考控件,以此安排该控件的位置
FrameLayout:帧布局,默认叠放在左上角
ConstraintLayout:约束布局,利用可视化操作进行布局
MaterialCardView:卡片式布局,在帧布局的基础上额外提供了圆角和阴影等效果
DrawerLayout:抽屉式布局,即滑动菜单,内含两个控件,第一个为主界面,第二个为菜单界面
CoordinatorLayout:协调器布局,加强版帧布局,普通情况下与帧布局效果相同,可以监听其索引子控件的各种事件,并自动帮助我们做出最为合理的相应。
什么情况下用线性布局,什么情况适合相对布局?
线性布局的局限性在于只能针对一个方向上布局视图,所以适用于所有控件width或height属性为match_parent的情况,此时不需要考虑另一个方向上的布局情况。
而相对布局就弥补了线性布局的这个短板,它通过相对定位可以让内部视图出现在任意位置,适用于比较复杂的布局情况。
简述布局中的merge标签
用来与include标签搭配进行布局嵌套。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
<merge
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="wrap_content"
tools:ignore="all">
<Button
android:id="@+id/back"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignParentStart="true"
android:textAllCaps="false"
android:text="返回"/>
<Button
android:id="@+id/title"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_centerHorizontal="true"
android:background="@android:color/white"
android:textAllCaps="false"
android:text="标题"/>
<Button
android:id="@+id/share"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignParentEnd="true"
android:text="分享"
android:textAllCaps="false"/>
</merge>
<include
android:layout_width="match_parent"
android:layout_height="wrap_content"
layout="@layout/merge_item"/>
merge标签中的子集是直接加到Activity的FrameLayout根节点下,(Activity视图的根节点都是frameLayout).如果你所创建的Layout并不是用FrameLayout作为根节点(而是应用LinearLayout等定义root标签),就不能通过merge来优化UI结构.
当应用Include或者ViewStub标签从外部导入xml结构时,可以将被导入的xml用merge作为根节点表示,这样当被嵌入父级结构中后可以很好的将它所包含的子集融合到父级结构中,而不会出现冗余的节点.
另外需要注意的是:
< merge />只可以作为xml FrameLayout的根节点.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<FrameLayout
android:id="@+id/main_frame"
android:layout_width="match_parent"
android:layout_height="match_parent"/>
</LinearLayout>
<merge
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent">
<Button
android:id="@+id/btn1"
android:layout_height="wrap_content"
android:layout_width="wrap_content"
android:text="按钮1"/>
<Button
android:id="@+id/btn2"
android:layout_height="wrap_content"
android:layout_width="wrap_content"
android:text="按钮2"/>
<Button
android:id="@+id/btn3"
android:layout_height="wrap_content"
android:layout_width="wrap_content"
android:text="按钮3"/>
</merge>
当需要扩充的xml layout本身是由merge作为根节点的话,需要将被导入的xml layout置于 viewGroup中,同时需要设置attachToRoot为True.
总之,标签在UI的结构优化中起着非常重要的作用,它可以删减多余的层级,优化UI。多用于替换FrameLayout或者当一个布局包含另一个时,标签消除视图层次结构中多余的视图组。例如你的主布局文件是垂直布局,引入了一个垂直布局的include,这是如果include布局使用的LinearLayout就没意义了,使用的话反而减慢你的UI表现。这时可以使用标签优化。
动画
- Frame Animation
帧动画,通过顺序播放一系列图像从而产生动画效果,图片过多时容易造成OOM(Out Of Memory内存用完)异常。 - Tween Animation
补间动画(又叫view动画),是通过对场景里的对象不断做图像变换(透明度、缩放、平移、旋转)从而产生动画效果,是一种渐进式动画,并且View动画支持自定义。 - Accribute Animation
属性动画,这也是在android3.0之后引进的动画,在手机的版本上是android4.0就可以使用这个动画,通过动态的改变对象的属性从而达到动画效果。
同为动态改变对象,补间动画和属性动画有什么区别?
补间动画只是改变了View的显示效果而已,并不会真正的改变View的属性。而属性动画可以改变View的显示效果和属性。举个例子:例如屏幕左上角有一个Button按钮,使用补间动画将其移动到右下角,此刻你去点击右下角的Button,它是绝对不会响应点击事件的,因此其作用区域依然还在左上角。只不过是补间动画将其绘制在右下角而已,而属性动画则不会。
IPC
安卓中如何进行进程间通信?
Bundle、文件共享、Messenger、AIDL、ContentProvider、Socket
Binder机制是什么?
Binder机制是 Android系统中进程间通讯(IPC)的一种方式,Android中ContentProvider、Intent、aidl都是基于Binder。
如何使用Binder?
(1)获得ServiceManager的对象引用
(2)向duServiceManager注册新的Service
(3)在Client中通过ServiceManager获得Service对象引用
(3)在Client中发送请求,由Service返回结果。
Binder机制的好处:
1、只需要进行一次数据拷贝,性能上仅次于共享内存
2、基于C/S架构,职责明确,架构清晰,稳定性较好
3、为每个App分配UID,UID可用来识别进程身份,安全性较好
权限
Android中权限分为哪两类 ?有什么区别?
危险权限和普通权限,普通权限只需要在注册文件中声明即可,危险权限不仅需要在注册文件中声明,还需要向用户申请权限许可。
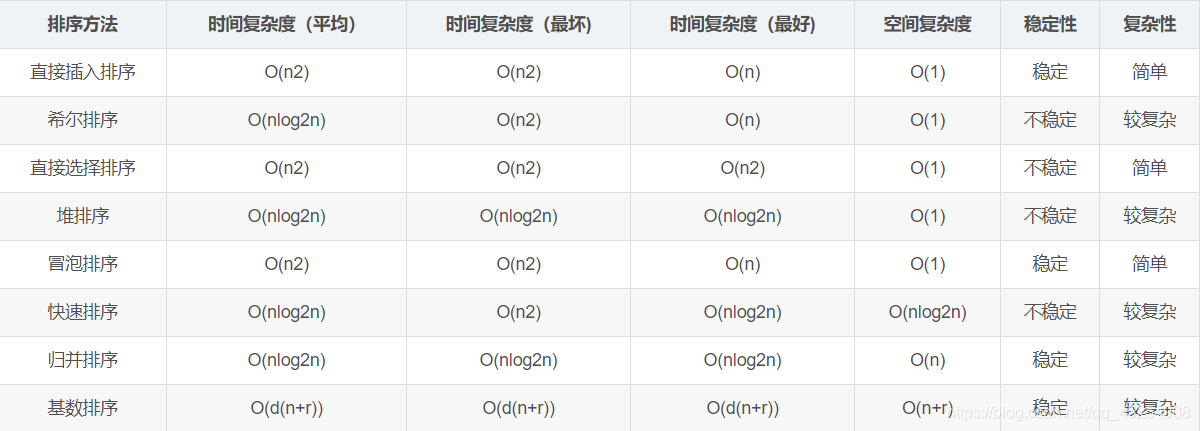
排序算法
http1.0 http1.1 http2.0 的区别
一、HTTP的历史
早在 HTTP 建立之初,主要就是为了将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器。也是说对于前端来说,我们所写的HTML页面将要放在我们的 web 服务器上,用户端通过浏览器访问url地址来获取网页的显示内容,但是到了 WEB2.0 以来,我们的页面变得复杂,不仅仅单纯的是一些简单的文字和图片,同时我们的 HTML 页面有了 CSS,Javascript,来丰富我们的页面展示,当 ajax 的出现,我们又多了一种向服务器端获取数据的方法,这些其实都是基于 HTTP 协议的。同样到了移动互联网时代,我们页面可以跑在手机端浏览器里面,但是和 PC 相比,手机端的网络情况更加复杂,这使得我们开始了不得不对 HTTP 进行深入理解并不断优化过程中。
二、HTTP的基本优化
影响一个 HTTP 网络请求的因素主要有两个:带宽和延迟。
带宽:如果说我们还停留在拨号上网的阶段,带宽可能会成为一个比较严重影响请求的问题,但是现在网络基础建设已经使得带宽得到极大的提升,我们不再会担心由带宽而影响网速,那么就只剩下延迟了。
延迟:
浏览器阻塞(HOL blocking):浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有 4 个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。
DNS 查询(DNS Lookup):浏览器需要知道目标服务器的 IP 才能建立连接。将域名解析为 IP 的这个系统就是 DNS。这个通常可以利用DNS缓存结果来达到减少这个时间的目的。
建立连接(Initial connection):HTTP 是基于 TCP 协议的,浏览器最快也要在第三次握手时才能捎带 HTTP 请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
三、HTTP1.0和HTTP1.1的一些区别
HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。 主要区别主要体现在:
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
四、HTTPS与HTTP的一些区别
- HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
- HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
- HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
五、SPDY:HTTP1.x的优化
2012年google如一声惊雷提出了SPDY的方案,优化了HTTP1.X的请求延迟,解决了HTTP1.X的安全性,具体如下:
- 降低延迟,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通过多个请求stream共享一个tcp连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了带宽的利用率。
- 请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
- header压缩。前面提到HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
- 基于HTTPS的加密协议传输,大大提高了传输数据的可靠性。
- 服务端推送(server push),采用了SPDY的网页,例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。SPDY构成图:
SPDY位于HTTP之下,TCP和SSL之上,这样可以轻松兼容老版本的HTTP协议(将HTTP1.x的内容封装成一种新的frame格式),同时可以使用已有的SSL功能。
六、HTTP2.0性能惊人
HTTP/2: the Future of the Internet https://link.zhihu.com/?target=https://http2.akamai.com/demo 是 Akamai 公司建立的一个官方的演示,用以说明 HTTP/2 相比于之前的 HTTP/1.1 在性能上的大幅度提升。 同时请求 379 张图片,从Load time 的对比可以看出 HTTP/2 在速度上的优势。
七、HTTP2.0:SPDY的升级版
HTTP2.0可以说是SPDY的升级版(其实原本也是基于SPDY设计的),但是,HTTP2.0 跟 SPDY 仍有不同的地方,如下:
HTTP2.0和SPDY的区别:
- HTTP2.0 支持明文 HTTP 传输,而 SPDY 强制使用 HTTPS
- HTTP2.0 消息头的压缩算法采用 HPACK http://http2.github.io/http2-spec/compression.html,而非 SPDY 采用的 DEFLATE http://zh.wikipedia.org/wiki/DEFLATE
八、HTTP2.0和HTTP1.X相比的新特性
新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
服务端推送(server push),同SPDY一样,HTTP2.0也具有server push功能。
九、HTTP2.0的升级改造
- 前文说了HTTP2.0其实可以支持非HTTPS的,但是现在主流的浏览器像chrome,firefox表示还是只支持基于 TLS 部署的HTTP2.0协议,所以要想升级成HTTP2.0还是先升级HTTPS为好。
- 当你的网站已经升级HTTPS之后,那么升级HTTP2.0就简单很多,如果你使用NGINX,只要在配置文件中启动相应的协议就可以了,可以参考NGINX白皮书,NGINX配置HTTP2.0官方指南 https://www.nginx.com/blog/nginx-1-9-5/。
- 使用了HTTP2.0那么,原本的HTTP1.x怎么办,这个问题其实不用担心,HTTP2.0完全兼容HTTP1.x的语义,对于不支持HTTP2.0的浏览器,NGINX会自动向下兼容的。
十、附注
HTTP2.0的多路复用和HTTP1.X中的长连接复用有什么区别?
HTTP/1.* 一次请求-响应,建立一个连接,用完关闭;每一个请求都要建立一个连接;
HTTP/1.1 Pipeling解决方式为,若干个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞;
HTTP/2多个请求可同时在一个连接上并行执行。某个请求任务耗时严重,不会影响到其它连接的正常执行;
具体如图:
服务器推送到底是什么?
服务端推送能把客户端所需要的资源伴随着index.html一起发送到客户端,省去了客户端重复请求的步骤。正因为没有发起请求,建立连接等操作,所以静态资源通过服务端推送的方式可以极大地提升速度。具体如下:
- 普通的客户端请求过程:
- 服务端推送的过程:
为什么需要头部压缩?
假定一个页面有100个资源需要加载(这个数量对于今天的Web而言还是挺保守的), 而每一次请求都有1kb的消息头(这同样也并不少见,因为Cookie和引用等东西的存在), 则至少需要多消耗100kb来获取这些消息头。HTTP2.0可以维护一个字典,差量更新HTTP头部,大大降低因头部传输产生的流量。具体参考:HTTP/2 头部压缩技术介绍
HTTP2.0多路复用有多好?
HTTP 性能优化的关键并不在于高带宽,而是低延迟。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
HTTP/2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。
http3.0
HTTP1.1在应用层以纯文本的形式进行通信,每次通信都要带完整的HTTP的头,而且不考虑pipeli模式的化,每次的过程总是像上面描述的那样一去一回。那样在实时性、并发想上都存在问题
头部压缩:HTTP2.0会对HTTP的头进行一定的压缩,将原来每次都要携带的大量key value在两端建立一个索引表,对相同的头只发送索引表中的索引
HTTP2.0协议将一个TCP的连接中,切分成多个流。每个流都有自己的ID,而且流可以是客户端发服务端,也可以是服务端发客户端,它其实只是一个虚拟的通道。流是有优先级的
HTTP2.0还将所有的传输信息分割为更小的信息和帧,并对它们采用二进制格式编码。常见的帧有Header帧,用于传输Header内容,并且会开启一个新的流,再就是Data帧,用来传输正文实体。多个Data帧属于一个流
通过这两种机制,http2.0的客户端可以将对个请求不同的流中,然后将请求内容拆成帧,进行二进制传输。这些真可以打散乱序发送,然后根据每个帧首部的流标识符重新组装,并且可以根据优先级,决定先处理那个流的数据
二进制传输就是以上
例子:
假设一个页面要发送三个独立的请求,一个获取css,一个获取js,一个获取图片jpg。如果使用HTTP1.1就是串行的,但是如果使用HTTP2.0,就可以在一个连接里,客户端和服务端都可以同时发送多个请求或回应,而且不用按照顺序一对一对应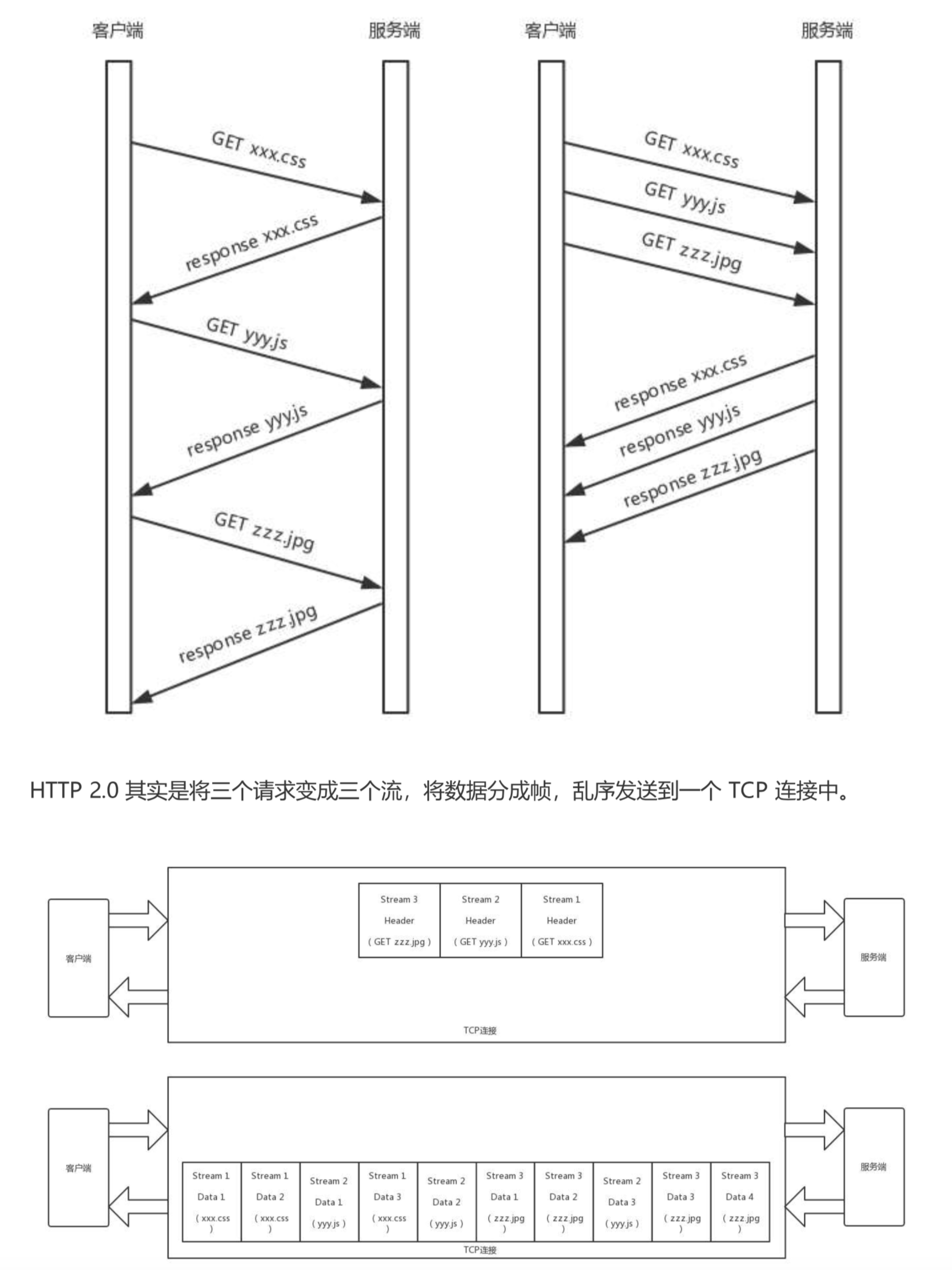
http2.0成功解决了http1.1的队首阻塞问题,同时,也不需要通过http1.x的pipeline机制用多条tcp连接来实现并行请求和响应;减少了tcp连接数对服务器性能的影响,同时将页面的多个数据css,js,jpg等通过一个数据链接进行传输,能够加快页面组件的传输速度。
QUIC协议
HTTP2.0 也是基于TCP协议的,tcp协议在处理包时是有严格顺序的
当其中一个数据包遇到问题,TCP连接需要等待找个包完成重传之后才能继续进行,虽然HTTP2.0通过多个stream,使得逻辑上一个tcp连接上的并行内容,进行多路数据的传输,然而这中间没有关联的数据,一前一后,前面stream2的帧没有收到,后面stream1的帧也会因此堵塞
于是google的 QUIC协议从TCP切换到UDP
- 机制一:自定义连接机制
一条tcp连接是由四元组标识的,分别是源ip、源端口、目的端口,一旦一个元素发生变化时,就会断开重连,重新连接。在次进行三次握手,导致一定的延时
在TCP是没有办法的,但是基于UDP,就可以在QUIC自己的逻辑里面维护连接的机制,不再以四元组标识,而是以一个64
位的随机数作为ID来标识,而且UDP是无连接的,所以当ip或者端口变化的时候,只要ID不变,就不需要重新建立连接
- 机制二:自定义重传机制
tcp为了保证可靠性,通过使用序号和应答机制,来解决顺序问题和丢包问题
任何一个序号的包发过去,都要在一定的时间内得到应答,否则一旦超时,就会重发这个序号的包,通过自适应重传算法(通过采样往返时间RTT不断调整)
但是,在TCP里面超时的采样存在不准确的问题。例如发送一个包,序号100,发现没有返回,于是在发送一个100,过一阵返回ACK101.客户端收到了,但是往返的时间是多少,没法计算。是ACK到达的时候减去第一还是第二。
QUIC也有个序列号,是递增的,任何宇哥序列号的包只发送一次,下次就要加1,那样就计算可以准确了
但是有一个问题,就是怎么知道包100和包101发送的是同样的内容呢?quic定义了一个offset概念。QUIC既然是面向连接的,也就像TCP一样,是一个数据流,发送的数据在这个数据流里面有个偏移量offset,可以通过offset查看数据发送到了那里,这样只有这个offset的包没有来,就要重发。如果来了,按照offset拼接,还是能够拼成一个流。
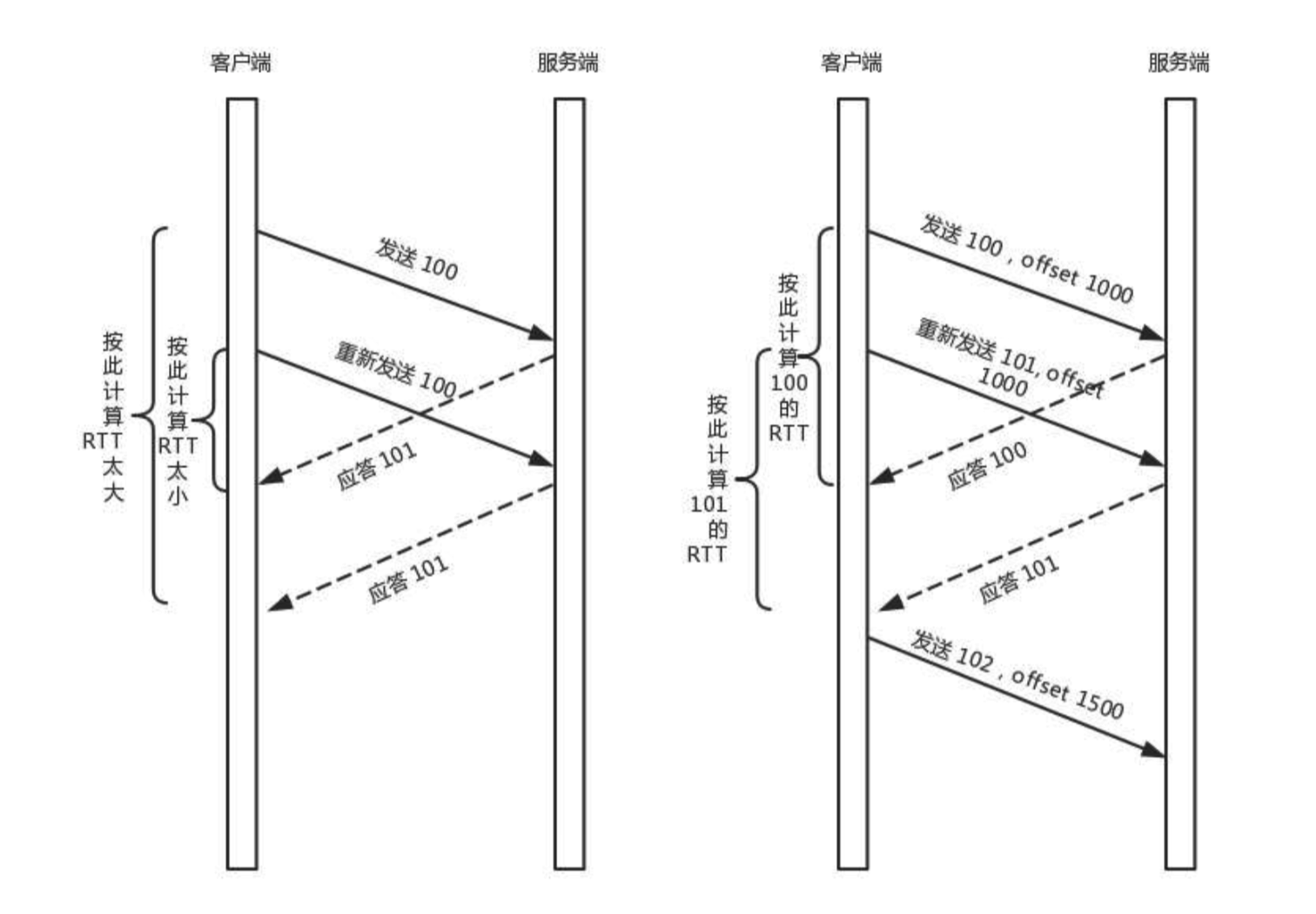
- 机制三: 无阻塞的多路复用
有了自定义的连接和重传机制,就可以解决上面HTTP2.0的多路复用问题
同HTTP2.0一样,同一条 QUIC连接上可以创建多个stream,来发送多个HTTP请求,但是,QUIC是基于UDP的,一个连接上的多个stream之间没有依赖。这样,假如stream2丢了一个UDP包,后面跟着stream3的一个UDP包,虽然stream2的那个包需要重新传,但是stream3的包无需等待,就可以发给用户。
- 机制四:自定义流量控制
TCP的流量控制是通过滑动窗口协议。QUIC的流量控制也是通过window_update,来告诉对端它可以接受的字节数。但是QUIC的窗口是适应自己的多路复用机制的,不但在一个连接上控制窗口,还在一个连接中的每个steam控制窗口。
在TCP协议中,接收端的窗口的起始点是下一个要接收并且ACK的包,即便后来的包都到了,放在缓存里面,窗口也不能右移,因为TCP的ACK机制是基于序列号的累计应答,一旦ACK了一个序列号,就说明前面的都到了,所以是要前面的没到,后面的到了也不能ACK,就会导致后面的到了,也有可能超时重传,浪费带宽
QUIC的ACK是基于offset的,每个offset的包来了,进了缓存,就可以应答,应答后就不会重发,中间的空档会等待到来或者重发,而窗口的起始位置为当前收到的最大offset,从这个offset到当前的stream所能容纳的最大缓存,是真正的窗口的大小,显然,那样更加准确。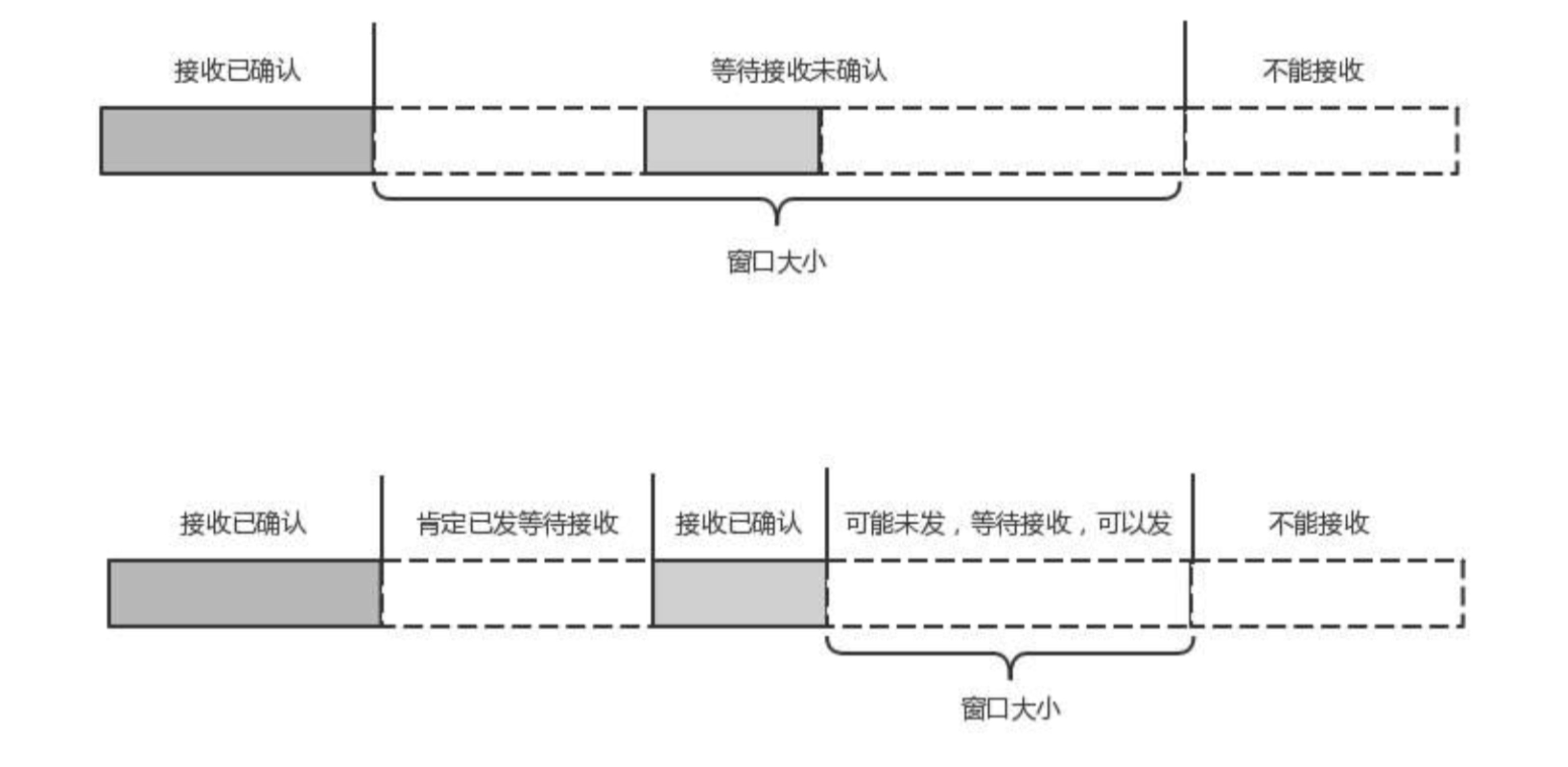
ping的过程
同一网段内
首先,如果主机A,要去ping主机B,那么主机A,就要封装二层报文,他会先查自己的MAC地址表,如果没有B的MAC地址,就会向外发送一个ARP广播包,交换机会收到这个报文后,交换机有学习MAC地址的功能,所以他会检索自己有没有保存主机B的MAC地址,如果有,就返回给主机A,如果没有,就会向所有端口发送ARP广播,其它主机收到后,发现不是在找自己,就纷纷丢弃了该报文,不去理会。直到主机B收到了报文后,就立即响应,我的MAC地址是多少,同时学到主机A的MAC地址,并按同样的ARP报文格式返回给主机A。如图:
不同网段内
如果主机A要ping主机C,那么主机A发现主机C的IP和自己不是同一网段,他就去找网关转发,但是他也不知道网关的MAC地址情况下呢?他就会向之前那个步骤一样先发送一个ARP广播,学到网关的MAC地址,再发封装ICMP报文给网关路由器.当路由器收到主机A发过来的ICMP报文,发现自己的目的地址是其本身MAC地址,根据目的的IP2.1.1.1,查路由表,发现2.1.1.1/24的路由表项,得到一个出口指针,去掉原来的MAC头部,加上自己的MAC地址向主机C转发。(如果网关也没有主机C的MAC地址,还是要向前面一个步骤一样,ARP广播一下即可相互学到。路由器2端口能学到主机D的MAC地址,主机D也能学到路由器2端口的MAC地址。)最后,在主机C已学到路由器2端口MAC地址,路由器2端口转发给路由器1端口,路由1端口学到主机A的MAC地址的情况下,他们就不需要再做ARP解析,就将ICMP的回显请求回复过来
判断一点是否在三角形内
可通过面积,如果点p在三角形内则拆分的三个三角形面积相等
https://www.cnblogs.com/graphics/archive/2010/08/05/1793393.html
Java线程的6种状态及切换
Java中线程的状态分为6种。
- 初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
- 运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。
线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。- 阻塞(BLOCKED):表示线程阻塞于锁。
- 等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
- 超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
- 终止(TERMINATED):表示该线程已经执行完毕。
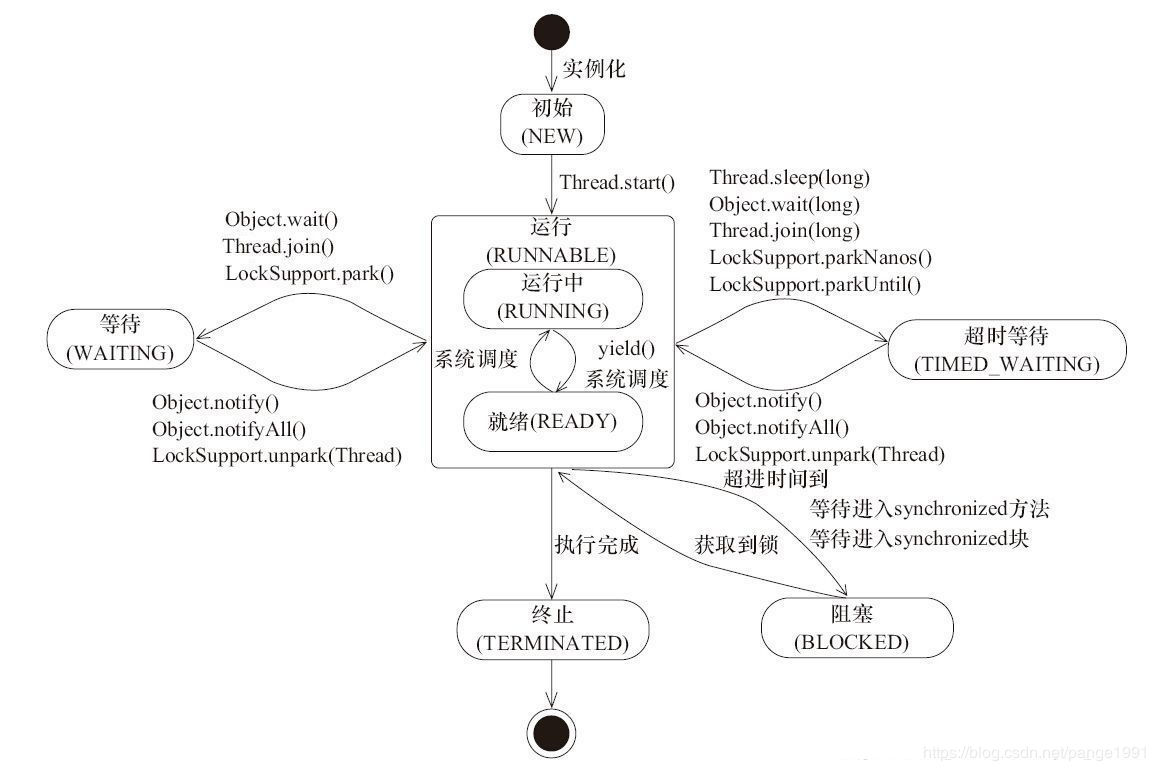
初始状态
实现Runnable接口和继承Thread可以得到一个线程类,new一个实例出来,线程就进入了初始状态。
就绪状态
- 就绪状态只是说你资格运行,调度程序没有挑选到你,你就永远是就绪状态。
- 调用线程的start()方法,此线程进入就绪状态。
- 当前线程sleep()方法结束,其他线程join()结束,等待用户输入完毕,某个线程拿到对象锁,这些线程也将进入就绪状态。
- 当前线程时间片用完了,调用当前线程的yield()方法,当前线程进入就绪状态。
- 锁池里的线程拿到对象锁后,进入就绪状态。
运行中状态
线程调度程序从可运行池中选择一个线程作为当前线程时线程所处的状态。这也是线程进入运行状态的唯一一种方式。
阻塞状态
阻塞状态是线程阻塞在进入synchronized关键字修饰的方法或代码块(获取锁)时的状态。
等待
处于这种状态的线程不会被分配CPU执行时间,它们要等待被显式地唤醒,否则会处于无限期等待的状态。
超时等待
处于这种状态的线程不会被分配CPU执行时间,不过无须无限期等待被其他线程显示地唤醒,在达到一定时间后它们会自动唤醒。
终止状态
- 当线程的run()方法完成时,或者主线程的main()方法完成时,我们就认为它终止了。这个线程对象也许是活的,但是,它已经不是一个单独执行的线程。线程一旦终止了,就不能复生。
- 在一个终止的线程上调用start()方法,会抛出java.lang.IllegalThreadStateException异常。
等待队列
- 调用obj的wait(), notify()方法前,必须获得obj锁,也就是必须写在synchronized(obj) 代码段内。
- 与等待队列相关的步骤和图
- 线程1获取对象A的锁,正在使用对象A。
- 线程1调用对象A的wait()方法。
- 线程1释放对象A的锁,并马上进入等待队列。
- 锁池里面的对象争抢对象A的锁。
- 线程5获得对象A的锁,进入synchronized块,使用对象A。
- 线程5调用对象A的notifyAll()方法,唤醒所有线程,所有线程进入同步队列。若线程5调用对象A的notify()方法,则唤醒一个线程,不知道会唤醒谁,被唤醒的那个线程进入同步队列。
- notifyAll()方法所在synchronized结束,线程5释放对象A的锁。
- 同步队列的线程争抢对象锁,但线程1什么时候能抢到就不知道了。
同步队列状态
- 当前线程想调用对象A的同步方法时,发现对象A的锁被别的线程占有,此时当前线程进入同步队列。简言之,同步队列里面放的都是想争夺对象锁的线程。
- 当一个线程1被另外一个线程2唤醒时,1线程进入同步队列,去争夺对象锁。
- 同步队列是在同步的环境下才有的概念,一个对象对应一个同步队列。
- 线程等待时间到了或被notify/notifyAll唤醒后,会进入同步队列竞争锁,如果获得锁,进入RUNNABLE状态,否则进入BLOCKED状态等待获取锁。
几个方法的比较
- Thread.sleep(long millis),一定是当前线程调用此方法,当前线程进入TIMED_WAITING状态,但不释放对象锁,millis后线程自动苏醒进入就绪状态。作用:给其它线程执行机会的最佳方式。
- Thread.yield(),一定是当前线程调用此方法,当前线程放弃获取的CPU时间片,但不释放锁资源,由运行状态变为就绪状态,让OS再次选择线程。作用:让相同优先级的线程轮流执行,但并不保证一定会轮流执行。实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。Thread.yield()不会导致阻塞。该方法与sleep()类似,只是不能由用户指定暂停多长时间。
- thread.join()/thread.join(long millis),当前线程里调用其它线程t的join方法,当前线程进入WAITING/TIMED_WAITING状态,当前线程不会释放已经持有的对象锁。线程t执行完毕或者millis时间到,当前线程一般情况下进入RUNNABLE状态,也有可能进入BLOCKED状态(因为join是基于wait实现的)。
- obj.wait(),当前线程调用对象的wait()方法,当前线程释放对象锁,进入等待队列。依靠notify()/notifyAll()唤醒或者wait(long timeout) timeout时间到自动唤醒。
- obj.notify()唤醒在此对象监视器上等待的单个线程,选择是任意性的。notifyAll()唤醒在此对象监视器上等待的所有线程。
- LockSupport.park()/LockSupport.parkNanos(long nanos),LockSupport.parkUntil(long deadlines), 当前线程进入WAITING/TIMED_WAITING状态。对比wait方法,不需要获得锁就可以让线程进入WAITING/TIMED_WAITING状态,需要通过LockSupport.unpark(Thread thread)唤醒。
责任链模式
可参考掘金
责任链模式(Chain of Responsibility Pattern):避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。职责链模式是一种对象行为型模式。
角色
Handler(抽象处理者):它定义了一个处理请求的接口,一般设计为抽象类,由于不同的具体处理者处理请求的方式不同,因此在其中定义了抽象请求处理方法。因为每一个处理者的下家还是一个处理者,因此在抽象处理者中定义了一个抽象处理者类型的对象,作为其对下家的引用。通过该引用,处理者可以连成一条链。
ConcreteHandler(具体处理者):它是抽象处理者的子类,可以处理用户请求,在具体处理者类中实现了抽象处理者中定义的抽象请求处理方法,在处理请求之前需要进行判断,看是否有相应的处理权限,如果可以处理请求就处理它,否则将请求转发给后继者;在具体处理者中可以访问链中下一个对象,以便请求的转发。
类图如下所示:
纯与不纯的责任链模式
纯的责任链模式:
- 一个具体处理者对象只能在两个行为中选择一个:要么承担全部责任,要么将责任推给下家,不允许出现某一个具体处理者对象在承担了一部分或全部责任后 又将责任向下传递的情况
- 一个请求必须被某一个处理者对象所接收,不能出现某个请求未被任何一个处理者对象处理的情况
不纯的责任链模式:
- 允许某个请求被一个具体处理者部分处理后再向下传递
- 或者一个具体处理者处理完某请求后其后继处理者可以继续处理该请求
- 而且一个请求可以最终不被任何处理者对象所接收
总结
职责链模式的主要优点
- 对象仅需知道该请求会被处理即可,且链中的对象不需要知道链的结构,由客户端负责链的创建,降低了系统的耦合度
- 请求处理对象仅需维持一个指向其后继者的引用,而不需要维持它对所有的候选处理者的引用,可简化对象的相互连接
- 在给对象分派职责时,职责链可以给我们更多的灵活性,可以在运行时对该链进行动态的增删改,改变处理一个请求的职责
- 新增一个新的具体请求处理者时无须修改原有代码,只需要在客户端重新建链即可,符合 “开闭原则”
职责链模式的主要缺点
- 一个请求可能因职责链没有被正确配置而得不到处理
- 对于比较长的职责链,请求的处理可能涉及到多个处理对象,系统性能将受到一定影响,且不方便调试
- 可能因为职责链创建不当,造成循环调用,导致系统陷入死循环
适用场景
- 有多个对象可以处理同一个请求,具体哪个对象处理该请求待运行时刻再确定,客户端只需将请求提交到链上,而无须关心请求的处理对象是谁以及它是如何处理的
- 在不明确指定接收者的情况下,向多个对象中的一个提交一个请求
- 可动态指定一组对象处理请求,客户端可以动态创建职责链来处理请求,还可以改变链中处理者之间的先后次序
SharePreference
SharePreference
一般用于保存偏好设置,比如说我们设置里的条目
sharepreference使用步骤
1、拿到sharepreference
1 | //拿到share preference |
这里的this是指上下文Context,在Activity中,因为Activity直接或间接继承了Context,所以直接使用this。
其中Context.MODE_PRIVATE是我们最常用的,只允许自己的程序访问
写入的数据保存在:
/data/data/
2、进入编辑模式
1 | //拿到编辑器 |
3、保存数据
1 | //保存数据 |
保存数据时,根据数据的类型boolean,String,float,等等
4、提交数据编辑器
1 | //提交编辑器 |
sharepreference同样属于内部存储,与files/cache相同,在data/data包名下shared_prefs以xml文件形式保存。
它的内容保存都是以键值对的方式保存。
sharepreference数据回显
1 | //数据回显 |
删除数据:
1 | SharedPreferences.Editor relieveEditor = getSharedPreferences("AllTopic", MODE_PRIVATE).edit(); |
清除sharepreference中的值:
1 | SharedPreferences sp = getSharedPreferences("setting_info", Context.MODE_PRIVATE); |
commit()操作 会先写数据到内存缓存,然后创建一个Runnable,通过调用下面的语句将Runnable加入到写文件的队列中
1 | QueuedWork.queue(writeToDiskRunnable, false);// 执行writeToDiskRunnable时不能延迟 |
apply()操作 会先写数据到内存缓存,然后创建一个Runnable,通过调用下面的语句将Runnable加入到写文件的队列中
1 | QueuedWork.queue(writeToDiskRunnable, true);// 延迟执行Runnable |
SharePreference中所有的内存级别缓存都是线程安全的,内部通过使用Synchronized 维护
备注: SharePreference 是线程安全的,内部的commit,apply都实现了线程同步,但是不支持多进程访问,除了初始化时从xml文件读取数据,其他时候都是内存级别的,所以数据不能共享
xml 时可以实现数据共享的,但是多个进程同时访问同一个xml文件,是无法保证数据的同步,正确性
SharePreference写数据到缓存时,只会将有变化的数据重新写入文件, 另外,则使用backup文件(初始化时使用,如果写文件的过程中出错,则使用backup恢复数据)
针对多进程共享SharePreference,可以通过ContentProvider包括一层,能不用SharePreference实现
commit 是在当前线程中写数据到文件
apply在异步线程中写数据到文件
commit:
- commit方法是有一个boolean的返回值
- 当数据变化进行存储时是一个原子性的操作
- 当两个editor对象同时对一个共享的preferences参数进行操作时,永远都是最后一个调用commit方法的editor变更了最后的数据值
apply:
- apply方法是没有返回值的
- 当两个editor同时对preferences对象编辑时,也是最后一个调用apply方法的对象编辑数据
- apply的提交操作也是原子性的,但是只提交到内存,速度更快
怎么判断是反射调用的方法
检查调用堆栈,可以看到调用的来源是否来自 MethodAccesor.invoke, Method.invoke 等关键方法,从而可以判断出是否是被反射调用
至于堆栈,new 一个异常就可以拿到了
安卓framework层架构
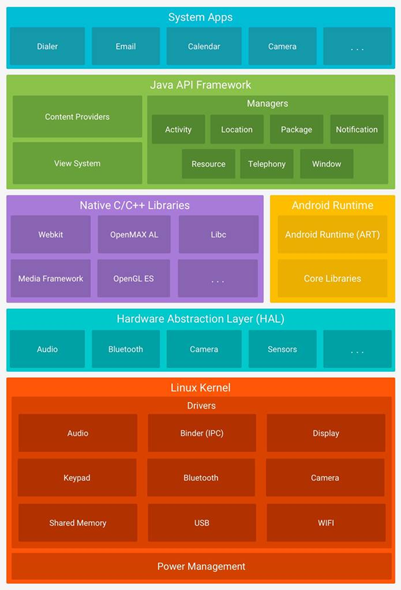
关于Framework层:
Android的Framework是直接应用之下的一层,叫做应用程序框架层。这一层是核心应用程序所使用的API框架,为应用层提供各种API,提供各种组件和服务来支持我们的Android开发,包括ActivityManager,WindowManager,ViewSystem等。
从图中可以看到
- ActivityManagerService(Ams):负责管理所有应用程序中的Activity,它掌握所有Activity的情况,具有所有调度Activity生命周期的能力,简单来说,ActivityManagerService是管理和掌控所有的Activity.
- WindowManagerService(Wms):控制窗口的显示、隐藏以及窗口的层序,简单来说,它就是管理窗口的,大多数和View有关系的都要和它打交道。
- 内容提供器(Content Providers):可以让一个应用访问”另一个应用”的数据(比如联系人数据库),或者共享他们的数据
- 视图系统(View System):丰富且可拓展,包括:列表(lists),网络(grids),文本框(text boxes),按钮(buttons)等等.
- 通知管理器(Notification Manager):可以在”状态栏中”显示自定义的提示信息
- 包管理器(Package Manger):对Android系统内的程序管理
- Telephony Manager主要提供了一系列用于访问与手机通讯相关的状态和信息的方法,查询电信网络状态信息,sim卡的信息等。
- Resource Manager提供非代码资源的访问,如本地字符串,图形,和布局文件(Layout files )。
- Location Manager提供设备的地址位置的获取方式。很显然,GPS导航肯定能用到位置服务。
- XMPP可扩展通讯和表示协议。前身为Jabber,提供即时通信服务。例如推送功能,Google Talk。
Android Framework的三大核心功能:
1、View.java:View工作原理,实现包括绘制view、处理触摸、按键事件等。
2、ActivityManagerService.java:Ams 管理所有应用程序的Activity等。
3、WindowManagerService.java:Wms 为所有应用程序分配窗口,并管理这些窗口。
Framework其实可以简单的理解为一些API的库房,android开发人员将一些基本功能实现,通过接口提供给上层调用,可以重复的调用
我们可以称Framework层才真正是Java语言实现的层,在这层里定义的API都是用Java语言编写。但是又因为它包含了JNI的方法,JNI用C/C++编写接口,根据函数表查询调用核心库层里的底层方法,最终访问到Linux内核。那么Framework层的作用就有2个。
1.用Java语言编写一些规范化的模块封装成框架,供APP层开发者调用开发出具有特殊业务的手机应用。
2.用Java Native Interface调用core lib层的本地方法,JNI的库是在Dalvik虚拟机启动时加载进去的,Dalvik会直接去寻址这个JNI方法,然后去调用。
2种方式的结合达到了Java方法和操作系统的相互通信。Android为什么要用Java编写Framework层呢?直接用C或C++不是更好?有关专家给出了如下解释:
C/C++过于底层,开发者要花很多的经历对C/C++的语言研究清楚,例如C/C++的内存机制,如果稍不注意,就会忘了开启或者释放。而Java的GC会自动处理这些,省去了很多的时间让开发者专注于自己的业务。所以才会从C/C++的底层慢慢向上变成了JAVA的开发语言,该层通过JNI和核心运行库层进行交互。
Activity启动流程分析
参考CSDN
Activity怎么绕过manifest.xml文件注册
参考CSDN
客户端认证服务端证书的过程
数字签名、数字证书、对称加密算法、非对称加密算法、单向加密(散列算法)
消息—>[公钥]—>加密后的信息—>[私钥]—>消息
加密:防窃听(私钥)(对签名加密,形成数字签名)(古典加密主要以保护算法为主,现代加密主要以保护密钥为主)
签名:防篡改(hash签名,并附加上原文一起发送)(权威机构给证书卡的一个章,即签名算法)
我们怎么确认CA的公钥就是对的呢,层层授信背书(CA的公钥也需要更牛的CA给它签名,只要上级证书的公钥,可以解开CA的签名,就可以。层层上去,直到全球皆知的几个著名的大CA)
在web数据传输过程中,由于客户端和服务器端是多对一的关系,因此可以让所有的客户端持有相同的公钥,服务器持有私钥,这样一来就能方便地实现数据的加密传输
浏览器与Web Server之间要经过一个握手的过程来完成身份鉴定与密钥交换,从而建立安全连接。具体过程如下:
用户浏览器将其SSL版本号、加密套件候选列表、压缩算法候选列表等有关的数据以及一个随机数发送到服务器。
服务器将其选择使用的协议版本、加密套件、压缩算法等有关的数据以及一个随机数发送给浏览器,同时发给浏览器的还有服务器的证书。如果配置服务器的SSL需要验证用户身份,还要发出请求要求浏览器提供用户证书。
客户端检查服务器证书,如果检查失败,提示不能建立SSL连接。如果成功,那么继续。客户端浏览器为本次会话生成Pre-Master secret,发送Client Key Exchange,并将其用服务器公钥加密后发送给服务器。如果服务器要求鉴别客户身份,客户端还要再对另外一些数据签名后并将其与客户端证书一起发送给服务器。
到目前为止,无论客户端还是服务器都有了三个随机数,自己的,对端的以及刚生成的Pre-Mastert随机数。通过这三个随机数,可以在客户端和服务器产生相同的对称密钥。这样做的主要原因是对称加密比非对称加密的运算量低一个数量级以上,能够显著提高双方会话时的运算速度。
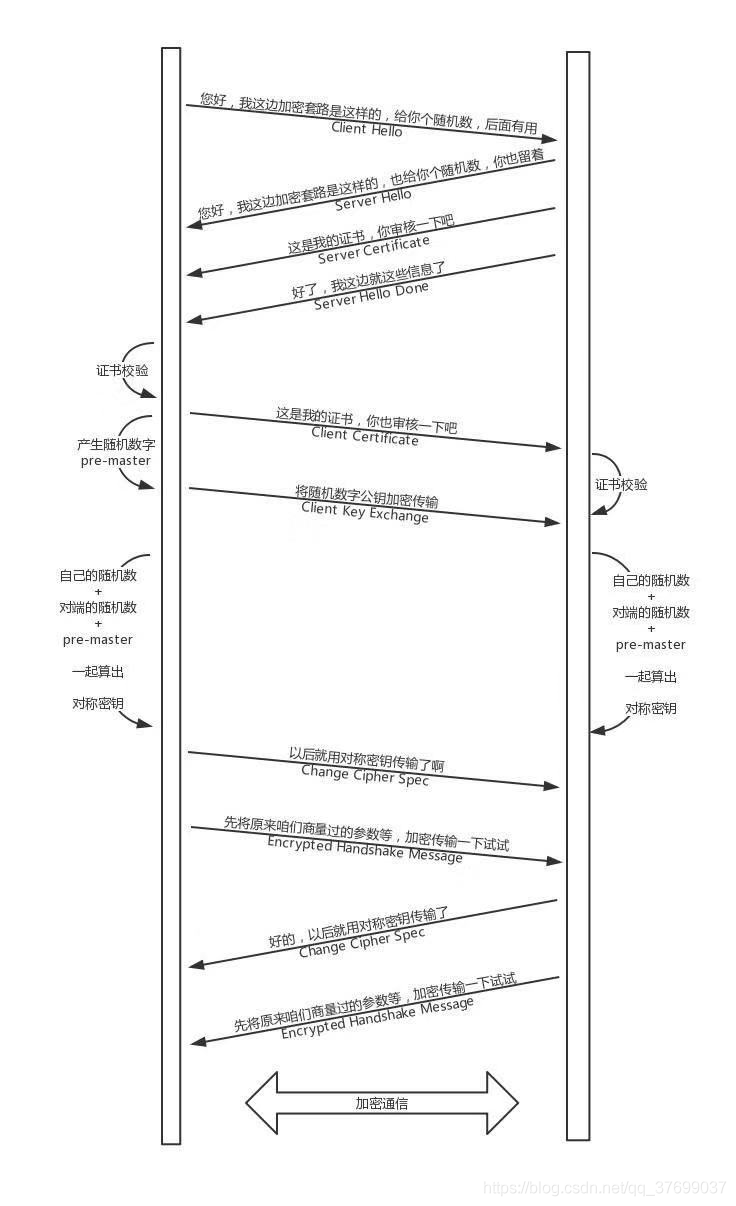
整个过程涉及2对公私密钥对,一对由服务器产生,用于加密,一对由CA产生,用于签名。
整个过程还涉及2个信任:客户端信任CA,CA发布的证书中的公钥就是合法服务器的公钥。客户端信任浏览器内置的CA公钥就是与CA私钥对应的公钥。最后要说明的是,非对称加密在https中只是用来对对称加密密钥进行协商的过程才使用,在两端协商完对称加密的密钥之后,数据的加密传输均采用对称加密的方式。
因为黑客也有服务器的公钥,所以在截取后可以打开服务器的密文,也可以模拟客户端获取一些信息。所以最好是两对公私钥,客户端用服务器的公钥加密传输,服务器用客户端的公钥加密传输
对于重放和篡改,通过timestamp和nonce随机数联合起来,保证唯一,对于同样的请求,只接受一次
android 资源ID生成规则
在Android中资源的使用几乎无处不在,layout、string、drawable、raw、style、theme 等等都是。
这些资源会在编译过程中被打包进 APK 中(res文件夹)或者被打包成独立的资源 APK 包(比如 framework-res.apk )。
但是这些资源都会被赋予独一无二的 ID 即资源索引来方便系统访问。
这些资源索引由 Android 的工具 AAPT(Android Asset Packing Tool)生成的八位十六进制整数型。
在编译的时候,AAPT会扫描你所定义的所有资源(在不同文件中定义的以及单独的资源文件),然后给它们指定不同的资源ID。
资源ID 是一个32bit的数字,格式是PPTTNNNN , PP代表资源所属的包(package) ,TT代表资源的类型(type),NNNN代表这个类型下面的资源的名称。 对于应用程序的资源来说,PP的取值是0×77。
TT 和NNNN 的取值是由AAPT工具随意指定的–基本上每一种新的资源类型的数字都是从上一个数字累加的(从1开始);而每一个新的资源条目也是从数字1开始向上累加的。
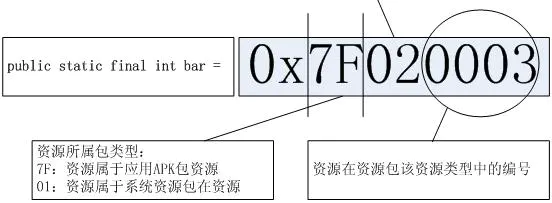
中间 02 所在位置值代表资源ID对应的资源的类型,分别是:
02:drawable
03:layout
04:values
05:xml
06:raw
07:color
08:menu
PS:分配resource id的主要逻辑实现是在framework/base/tools/aapt/Resource.cpp 和 ResourceTable.cpp
Java注解
https://www.runoob.com/w3cnote/java-annotation.html
关于注解首先引入官方文档的一句话:Java 注解用于为 Java 代码提供元数据。作为元数据,注解不直接影响你的代码执行,但也有一些类型的注解实际上可以用于这一目的。Java 注解是从 Java5 开始添加到 Java 的。看完这句话也许你还是一脸懵逼,接下我将从注解的定义、元注解、注解属性、自定义注解、注解解析JDK 提供的注解这几个方面再次了解注解(Annotation)
元注解
- 元注解顾名思义我们可以理解为注解的注解,它是作用在注解中,方便我们使用注解实现想要的功能。元注解分别有@Retention、 @Target、 @Document、 @Inherited和@Repeatable(JDK1.8加入)五种。
@Retention
- Retention英文意思有保留、保持的意思,它表示注解存在阶段是保留在源码(编译期),字节码(类加载)或者运行期(JVM中运行)。在@Retention注解中使用枚举RetentionPolicy来表示注解保留时期
- @Retention(RetentionPolicy.SOURCE),注解仅存在于源码中,在class字节码文件中不包含
- @Retention(RetentionPolicy.CLASS), 默认的保留策略,注解会在class字节码文件中存在,但运行时无法获得
- @Retention(RetentionPolicy.RUNTIME), 注解会在class字节码文件中存在,在运行时可以通过反射获取到
- 如果我们是自定义注解,则通过前面分析,我们自定义注解如果只存着源码中或者字节码文件中就无法发挥作用,而在运行期间能获取到注解才能实现我们目的,所以自定义注解中肯定是使用 @Retention(RetentionPolicy.RUNTIME)
1 | @Retention(RetentionPolicy.RUNTIME) |
@Target
- Target的英文意思是目标,这也很容易理解,使用@Target元注解表示我们的注解作用的范围就比较具体了,可以是类,方法,方法参数变量等,同样也是通过枚举类ElementType表达作用类型
- @Target(ElementType.TYPE) 作用接口、类、枚举、注解
- @Target(ElementType.FIELD) 作用属性字段、枚举的常量
- @Target(ElementType.METHOD) 作用方法
- @Target(ElementType.PARAMETER) 作用方法参数
- @Target(ElementType.CONSTRUCTOR) 作用构造函数
- @Target(ElementType.LOCAL_VARIABLE)作用局部变量
- @Target(ElementType.ANNOTATION_TYPE)作用于注解(@Retention注解中就使用该属性)
- @Target(ElementType.PACKAGE) 作用于包
- @Target(ElementType.TYPE_PARAMETER) 作用于类型泛型,即泛型方法、泛型类、泛型接口 (jdk1.8加入)
- @Target(ElementType.TYPE_USE) 类型使用.可以用于标注任意类型除了 class (jdk1.8加入)
- 一般比较常用的是ElementType.TYPE类型
1 |
|
@Documented
- Document的英文意思是文档。它的作用是能够将注解中的元素包含到 Javadoc 中去。
@Inherited
- Inherited的英文意思是继承,但是这个继承和我们平时理解的继承大同小异,一个被@Inherited注解了的注解修饰了一个父类,如果他的子类没有被其他注解修饰,则它的子类也继承了父类的注解。
- 下面我们来看个@Inherited注解例子
1 | /**自定义注解*/ |
@Repeatable
- Repeatable的英文意思是可重复的。顾名思义说明被这个元注解修饰的注解可以同时作用一个对象多次,但是每次作用注解又可以代表不同的含义。
- 下面我们看一个人玩游戏的例子
1 | /**一个人喜欢玩游戏,他喜欢玩英雄联盟,绝地求生,极品飞车,尘埃4等,则我们需要定义一个人的注解,他属性代表喜欢玩游戏集合,一个游戏注解,游戏属性代表游戏名称*/ |
- 通过上面的例子,你可能会有一个疑问,游戏注解中括号的变量是啥,其实这和游戏注解中定义的属性对应。接下来我们继续学习注解的属性。
注解的属性
- 通过上一小节@Repeatable注解的例子,我们说到注解的属性。注解的属性其实和类中定义的变量有异曲同工之处,只是注解中的变量都是成员变量(属性),并且注解中是没有方法的,只有成员变量,变量名就是使用注解括号中对应的参数名,变量返回值注解括号中对应参数类型。相信这会你应该会对上面的例子有一个更深的认识。而@Repeatable注解中的变量则类型则是对应Annotation(接口)的泛型Class。
1 | /**注解Repeatable源码*/ |
注解的本质
- 注解的本质就是一个Annotation接口
1 | /**Annotation接口源码*/ |
- 通过以上源码,我们知道注解本身就是Annotation接口的子接口,也就是说注解中其实是可以有属性和方法,但是接口中的属性都是static final的,对于注解来说没什么意义,而我们定义接口的方法就相当于注解的属性,也就对应了前面说的为什么注解只有属性成员变量,其实他就是接口的方法,这就是为什么成员变量会有括号,不同于接口我们可以在注解的括号中给成员变量赋值。
注解属性类型
- 注解属性类型可以有以下列出的类型
- 1.基本数据类型
- 2.String
- 3.枚举类型
- 4.注解类型
- 5.Class类型
- 6.以上类型的一维数组类型
注解成员变量赋值
- 如果注解又多个属性,则可以在注解括号中用“,”号隔开分别给对应的属性赋值,如下例子,注解在父类中赋值属性
1 |
|
JVM和DVM的区别,ART与DVM的区别
1、什么是JVM?
JVM本质上就是一个软件,是计算机硬件的一层软件抽象,在这之上才能够运行Java程序,JAVA在编译后会生成类似于汇编语言的JVM字节码,与C语言编译后产生的汇编语言不同的是,C编译成的汇编语言会直接在硬件上跑,但JAVA编译后生成的字节码是在JVM上跑,需要由JVM把字节码翻译成机器指令,才能使JAVA程序跑起来。
JVM运行在操作系统上,屏蔽了底层实现的差异,从而有了JAVA吹嘘的平台独立性和Write Once Run Anywhere。根据JVM规范实现的具体虚拟机有几十种,主流的JVM包括Hotspot、Jikes RVM等,都是用C/C++和汇编编写的,每个JRE编译的时候针对每个平台编译,因此下载JRE(JVM、Java核心类库和支持文件)的时候是分平台的,JVM的作用是把平台无关的.class里面的字节码翻译成平台相关的机器码,来实现跨平台。
2、什么是DVM,和JVM有什么不同?
JVM是Java Virtual Machine,而DVM就是Dalvik Virtual Machine,是安卓中使用的虚拟机,所有安卓程序都运行在安卓系统进程里,每个进程对应着一个Dalvik虚拟机实例。他们都提供了对象生命周期管理、堆栈管理、线程管理、安全和异常管理以及垃圾回收等重要功能,各自拥有一套完整的指令系统,以下简要对比两种虚拟机的不同。
①JAVA虚拟机运行的是JAVA字节码,Dalvik虚拟机运行的是Dalvik字节码
JAVA程序经过编译,生成JAVA字节码保存在class文件中,JVM通过解码class文件中的内容来运行程序。而DVM运行的是Dalvik字节码,所有的Dalvik字节码由JAVA字节码转换而来,并被打包到一个DEX(Dalvik Executable)可执行文件中,DVM通过解释DEX文件来执行这些字节码。
②Dalvik可执行文件体积更小
class文件中包含多个不同的方法签名,如果A类文件引用B类文件中的方法,方法签名也会被复制到A类文件中(在虚拟机加载类的连接阶段将会使用该签名链接到B类的对应方法),也就是说,多个不同的类会同时包含相同的方法签名,同样地,大量的字符串常量在多个类文件中也被重复使用,这些冗余信息会直接增加文件的体积,而JVM在把描述类的数据从class文件加载到内存时,需要对数据进行校验、转换解析和初始化,最终才形成可以被虚拟机直接使用的JAVA类型,因为大量的冗余信息,会严重影响虚拟机解析文件的效率。
为了减小执行文件的体积,安卓使用Dalvik虚拟机,SDK中有个dx工具负责将JAVA字节码转换为Dalvik字节码,dx工具对JAVA类文件重新排列,将所有JAVA类文件中的常量池分解,消除其中的冗余信息,重新组合形成一个常量池,所有的类文件共享同一个常量池,使得相同的字符串、常量在DEX文件中只出现一次,从而减小了文件的体积。
③JVM基于栈,DVM基于寄存器
JAVA虚拟机基于栈结构,程序在运行时虚拟机需要频繁的从栈上读取写入数据,这个过程需要更多的指令分派与内存访问次数,会耗费很多CPU时间。
Dalvik虚拟机基于寄存器架构,数据的访问通过寄存器间直接传递,这样的访问方式比基于栈方式要快很多。
3、什么是ART虚拟机,和JVM/DVM有什么不同?
首先了解JIT(Just In Time,即时编译技术)和AOT(Ahead Of Time,预编译技术)两种编译模式。
JIT以JVM为例,javac把程序源码编译成JAVA字节码,JVM通过逐条解释字节码将其翻译成对应的机器指令,逐条读入,逐条解释翻译,执行速度必然比C/C++编译后的可执行二进制字节码程序慢,为了提高执行速度,就引入了JIT技术,JIT会在运行时分析应用程序的代码,识别哪些方法可以归类为热方法,这些方法会被JIT编译器编译成对应的汇编代码,然后存储到代码缓存中,以后调用这些方法时就不用解释执行了,可以直接使用代码缓存中已编译好的汇编代码。这能显著提升应用程序的执行效率。(安卓Dalvik虚拟机在2.2中增加了JIT)
相对的AOT就是指C/C++这类语言,编译器在编译时直接将程序源码编译成目标机器码,运行时直接运行机器码。
Dalvik虚拟机执行的是dex字节码,ART虚拟机执行的是本地机器码
Dalvik执行的是dex字节码,依靠JIT编译器去解释执行,运行时动态地将执行频率很高的dex字节码翻译成本地机器码,然后在执行,但是将dex字节码翻译成本地机器码是发生在应用程序的运行过程中,并且应用程序每一次重新运行的时候,都要重新做这个翻译工作,因此,即使采用了JIT,Dalvik虚拟机的总体性能还是不能与直接执行本地机器码的ART虚拟机相比。
安卓运行时从Dalvik虚拟机替换成ART虚拟机,并不要求开发者重新将自己的应用直接编译成目标机器码,也就是说,应用程序仍然是一个包含dex字节码的apk文件。所以在安装应用的时候,dex中的字节码将被编译成本地机器码,之后每次打开应用,执行的都是本地机器码。移除了运行时的解释执行,效率更高,启动更快。(安卓在4.4中发布了ART运行时)
ART优点:
①系统性能显著提升
②应用启动更快、运行更快、体验更流畅、触感反馈更及时
③续航能力提升
④支持更低的硬件
ART缺点
①更大的存储空间占用,可能增加10%-20%
②更长的应用安装时间
ANR DEBUG
1,AndroidStudio Logcat查看

通过查看Logcat的方法只能看一个大概,告诉你主线程等待异常;
2,traces.txt
app每次出现anr异常,系统都会记录到手机的traces.txt文件中,所以,出现anr可通过查看traces.txt追踪异常;
对adb不了解的可先看下Android adb shell 常用命令https://www.cnblogs.com/abeam/p/8908225.html
配置好adb以后查找traces.txt文件(声明:不需要root)
window + R ,输入cmd 打开命令窗口:
①adb shell (链接设备)
②cd /data/anr (进入/data/anr目录下)
③ls (查看当前目录下文件)
④ctrl + d 退出
⑤adb pull data/anr/traces.txt c:\anr (可将文件导入到c盘anr文件中,如果出现以下异常,需按照另外一种办法解决)
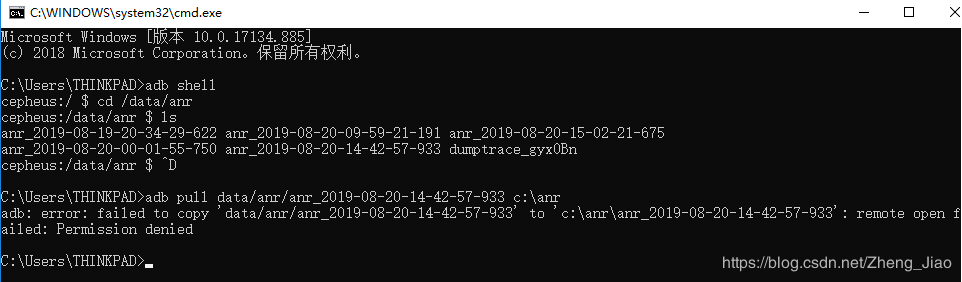
出现这种异常需使用另外一个命令导出
1 | //6.0及以下设备 |
压缩成功,可以先查看以下,然后导出:
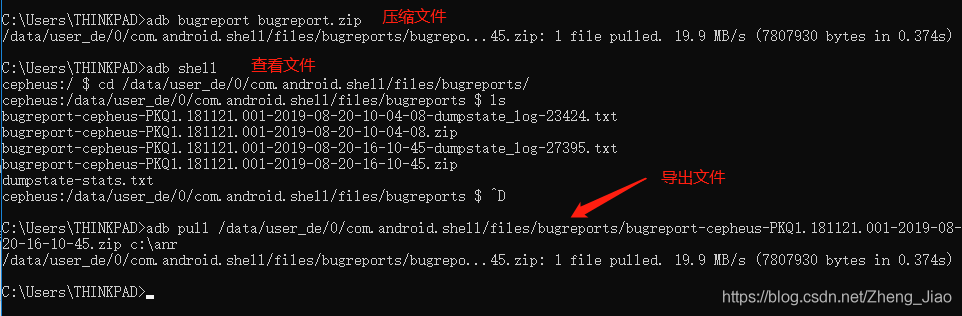
然后到电脑C盘anr文件夹中解压压缩包,找到 FS文件夹 ——> data文件夹 ——> anr文件夹
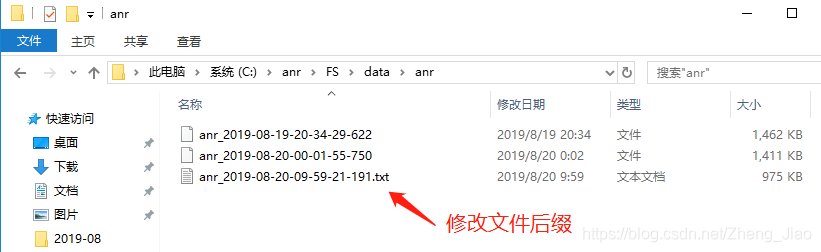
打开查找anr异常
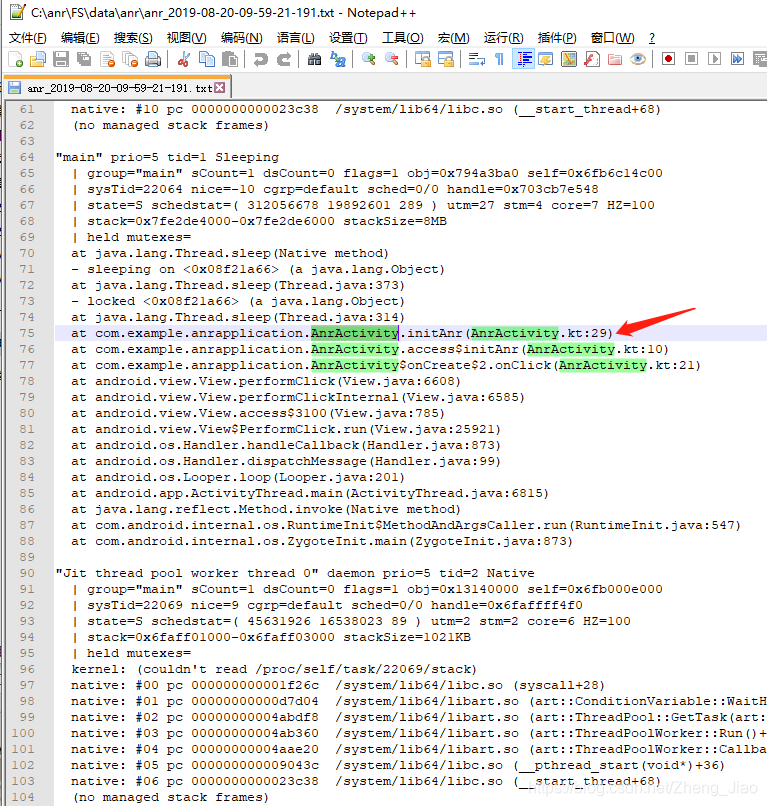
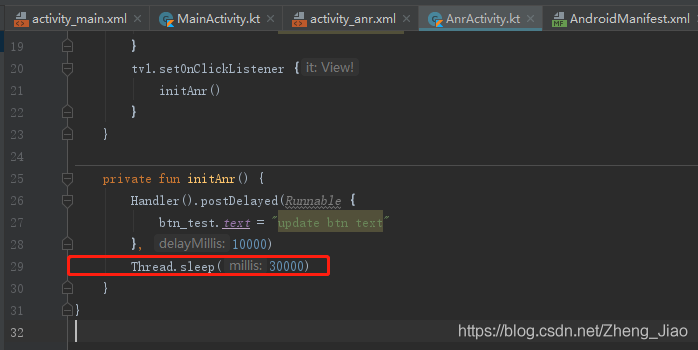
可精准定位到异常;
其实造成ANR异常的原因很多,主线程阻塞,CPU满负荷,内存不足,还有各大组件ANR。
ANR的避免和检测
为了避免在开发中引入可能导致应用发生ANR的问题,除了切记不要在主线程中作耗时操作,我们也可以借助于一些工具来进行检测,从而更有效的避免ANR的引入。
StrictMode
严格模式StrictMode是Android SDK提供的一个用来检测代码中是否存在违规操作的工具类,StrictMode主要检测两大类问题。
- 线程策略 ThreadPolicy
- detectCustomSlowCalls:检测自定义耗时操作
- detectDiskReads:检测是否存在磁盘读取操作
- detectDiskWrites:检测是否存在磁盘写入操作
- detectNetWork:检测是否存在网络操作
- 虚拟机策略VmPolicy
- detectActivityLeaks:检测是否存在Activity泄露
- detectLeakedClosableObjects:检测是否存在未关闭的Closeable对象泄露
- detectLeakedSqlLiteObjects:检测是否存在Sqlite对象泄露
- setClassInstanceLimit:检测类实例个数是否超过限制
可以看到,ThreadPolicy可以用来检测可能催在的主线程耗时操作,需要注意的是我们只能在Debug版本中使用它,发布到市场上的版本要关闭掉。StrictMode的使用很简单,我们只需要在应用初始化的地方例如Application或者MainActivity类的onCreate方法中执行如下代码:
1 |
|
上面的初始化代码调用penaltyLog表示在Logcat中打印日志,调用detectAll方法表示启动所有的检测策略,我们也可以根据应用的具体要求只开启某些策略,语句如下:
1 | StrictMode.setThreadPolicy(new StrictMode.ThreadPolicy.Builder() |
BlockCanary
BlockCanary是一个非侵入式式的性能监控函数库,它的用法和leakCanary类似,只不过后者监控应用的内存泄露,而BlockCanary主要用来监控应用主线程的卡顿。它的基本原理是利用主线程的消息队列处理机制,通过对比消息分发开始和结束的时间点来判断是否超过设定的时间,如果是,则判断为主线程卡顿。它的集成很简单,首先在build.gradle中添加依赖
一般选取以下其中一个 case 引入即可
1 | dependencies { |
然后在Application类中进行配置和初始化即可
1 | public class AnrDemoApplication extends Application { |
实现自己监控的上下文
1 | public class AppBlockCanaryContext extends BlockCanaryContext { |
在AndroidManifest.xml文件中声明Application,一定不要忘记
现在就已经将BlockCanary集成到应用里面了,接下来,编译安装到手机上,点击测试按钮,将产生一个ANR,效果如图:
APK减包
https://blog.csdn.net/whb20081815/article/details/70140063
Android控件为什么不能加锁?
这是因为Android的UI线程是不安全的,如果在多线程中并发访问可能会导致UI控件处于不可预期的状态.
那么为什么不对UI控件的访问加上锁机制呢?缺点有两个:首先加上锁机制会让UI访问逻辑变的复杂,其次锁机制会降低UI的访问效率,因为锁机制会阻塞某些线程的执行(?).
检测机制:ViewRootImpl的checkThread()检测当前线程是否是UI线程,否则抛异常
1 | void checkThread() { |
子线程更新UI
https://juejin.im/post/6844903968435503112
一般的View有一个Surface,并且对应SurfaceFlinger的一块内存区域。这个本地Surface和View是绑定的,他的绘制操作,最终都会调用到ViewRootImpl,那么这个就会被检查是否主线程了,所以只要在ViewRootImpl启动后,访问UI的所有操作都不可以在子线程中进行。
那SurfaceView为什么可以子线程访问他的画布呢?如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public class MainActivity extends AppCompatActivity implements SurfaceHolder.Callback {
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
SurfaceView surfaceView = findViewById(R.id.sv);
surfaceView.getHolder().addCallback(this);
}
public void surfaceCreated(final SurfaceHolder holder) {
new Thread(new Runnable() {
public void run() {
while (true){
Canvas canvas = holder.lockCanvas();
canvas.drawColor(Color.RED);
holder.unlockCanvasAndPost(canvas);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
}
public void surfaceChanged(SurfaceHolder holder, int format, int width, int height) {
}
public void surfaceDestroyed(SurfaceHolder holder) {
}
}
其实查看SurfaceView的代码,可以发现他自带一个Surface
1 | public class SurfaceView extends View implements ViewRootImpl.WindowStoppedCallback { |
在SurfaceView的updateSurface()中
1 | protected void updateSurface() { |
SurfaceView中的mSurface也有在SurfaceFlinger对应的内存区域,这样就很容易实现子线程访问画布了。
这样设计有什么不好的地方吗?
因为这个 mSurface 不在 View 体系中,它的显示也不受 View 的属性控制,所以不能进行平移,缩放等变换,也不能放在其它 ViewGroup 中,一些 View 中的特性也无法使用。
AsyncTask使用和缺陷
一、AsyncTask的基本用法
由于AsyncTask是一个抽象类,所以如果我们想使用它,就必须要创建一个子类去继承它。在继承时我们可以为AsyncTask类指定三个泛型参数,这三个参数的用途如下:
Params
在执行AsyncTask时需要传入的参数,可用于在后台任务中使用。Progress
后台任务执行时,如果需要在界面上显示当前的进度,则使用这里指定的泛型作为进度单位。Result
当任务执行完毕后,如果需要对结果进行返回,则使用这里指定的泛型作为返回值类型。
因此,一个最简单的自定义AsyncTask就可以写成如下方式:
1 | class DownloadTask extends AsyncTask<Void, Integer, Boolean> { |
这里我们把AsyncTask的第一个泛型参数指定为Void,表示在执行AsyncTask的时候不需要传入参数给后台任务。第二个泛型参数指定为Integer,表示使用整型数据来作为进度显示单位。第三个泛型参数指定为Boolean,则表示使用布尔型数据来反馈执行结果。
当然,目前我们自定义的DownloadTask还是一个空任务,并不能进行任何实际的操作,我们还需要去重写AsyncTask中的几个方法才能完成对任务的定制。经常需要去重写的方法有以下四个:
onPreExecute()
这个方法会在后台任务开始执行之间调用,用于进行一些界面上的初始化操作,比如显示一个进度条对话框等。doInBackground(Params…)
这个方法中的所有代码都会在子线程中运行,我们应该在这里去处理所有的耗时任务。任务一旦完成就可以通过return语句来将任务的执行结果进行返回,如果AsyncTask的第三个泛型参数指定的是Void,就可以不返回任务执行结果。注意,在这个方法中是不可以进行UI操作的,如果需要更新UI元素,比如说反馈当前任务的执行进度,可以调用publishProgress(Progress…)方法来完成。onProgressUpdate(Progress…)
当在后台任务中调用了publishProgress(Progress…)方法后,这个方法就很快会被调用,方法中携带的参数就是在后台任务中传递过来的。在这个方法中可以对UI进行操作,利用参数中的数值就可以对界面元素进行相应的更新。onPostExecute(Result)
当后台任务执行完毕并通过return语句进行返回时,这个方法就很快会被调用。返回的数据会作为参数传递到此方法中,可以利用返回的数据来进行一些UI操作,比如说提醒任务执行的结果,以及关闭掉进度条对话框等。因此,一个比较完整的自定义AsyncTask就可以写成如下方式:
1 | class DownloadTask extends AsyncTask<Void, Integer, Boolean> { |
这里我们模拟了一个下载任务,在doInBackground()方法中去执行具体的下载逻辑,在onProgressUpdate()方法中显示当前的下载进度,在onPostExecute()方法中来提示任务的执行结果。如果想要启动这个任务,只需要简单地调用以下代码即可:
1 | new DownloadTask().execute(); |
以上就是AsyncTask的基本用法,我们并不需求去考虑什么异步消息处理机制,也不需要专门使用一个Handler来发送和接收消息,只需要调用一下publishProgress()方法就可以轻松地从子线程切换到UI线程了。
二、AsyncTask内部线程池
AnsycTask执行任务时,内部会创建一个进程作用域的线程池来管理要运行的任务,也就就是说当你调用了AsyncTask.execute()后,AsyncTask会把任务交给线程池,由线程池来管理创建Thread和运行Therad。对于内部的线程池不同版本的Android的实现方式是不一样的:
3.0之前规定同一时刻能够运行的线程数为5个,线程池总大小为128。也就是说当我们启动了10个任务时,只有5个任务能够立刻执行,另外的5个任务则需要等待,当有一个任务执行完毕后,第6个任务才会启动,以此类推。而线程池中最大能存放的线程数是128个,当我们尝试去添加第129个任务时,程序就会崩溃。
因此在3.0版本中AsyncTask的改动还是挺大的,在3.0之前的AsyncTask可以同时有5个任务在执行,而3.0之后的AsyncTask同时只能有1个任务在执行。为什么升级之后可以同时执行的任务数反而变少了呢?这是因为更新后的AsyncTask已变得更加灵活,如果不想使用默认的线程池,还可以自由地进行配置。比如使用如下的代码来启动任务:
1 | Executor exec = new ThreadPoolExecutor(15, 200, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>()); |
这样就可以使用我们自定义的一个Executor来执行任务,而不是使用SerialExecutor。上述代码的效果允许在同一时刻有15个任务正在执行,并且最多能够存储200个任务。
三、AsyncTask缺陷
1.生命周期
关于AsyncTask存在一个这样广泛的误解,很多人认为一个在Activity中的AsyncTask会随着Activity的销毁而销毁。然后事实并非如此。AsyncTask会一直执行doInBackground()方法直到方法执行结束。一旦上述方法结束,会依据情况进行不同的操作。
•如果cancel(boolean)调用了,则执行onCancelled(Result)方法
•如果cancel(boolean)没有调用,则执行onPostExecute(Result)方法
AsyncTask的cancel方法需要一个布尔值的参数,参数名为mayInterruptIfRunning,意思是如果正在执行是否可以打断,如果这个值设置为true,表示这个任务可以被打断,否则,正在执行的程序会继续执行直到完成。如果在doInBackground()方法中有一个循环操作,我们应该在循环中使用isCancelled()来判断,如果返回为true,我们应该避免执行后续无用的循环操作。
总之,我们使用AsyncTask需要确保AsyncTask正确地取消。
2.不好好工作的cancel()
简而言之的答案,有时候起作用。
如果你调用了AsyncTask的cancel(false),doInBackground()仍然会执行到方法结束,只是不会去调用onPostExecute()方法。但是实际上这是让应用程序执行了没有意义的操作。那么是不是我们调用cancel(true)前面的问题就能解决呢?并非如此。如果mayInterruptIfRunning设置为true,会使任务尽早结束,但是如果的doInBackground()有不可打断的方法会失效,比如这个BitmapFactory.decodeStream() IO操作。但是你可以提前关闭IO流并捕获这样操作抛出的异常。但是这样会使得cancel()方法没有任何意义。
3.内存泄露
还有一种常见的情况就是,在Activity中使用非静态匿名内部AsyncTask类,由于Java内部类的特点,AsyncTask内部类会持有外部类的隐式引用。由于AsyncTask的生命周期可能比Activity的长,当Activity进行销毁AsyncTask还在执行时,由于AsyncTask持有Activity的引用,导致Activity对象无法回收,进而产生内存泄露。
4.结果丢失
另一个问题就是在屏幕旋转等造成Activity重新创建时AsyncTask数据丢失的问题。当Activity销毁并重新创建后,还在运行的AsyncTask会持有一个Activity的非法引用即之前的Activity实例。导致onPostExecute()没有任何作用。
5.串行还是并行
下面的两个任务时同时执行呢,还是AsyncTask1执行结束之后,AsyncTask2才能执行呢?实际上是结果依据API不同而不同。
关于AsyncTask时串行还是并行有很多疑问,这很正常,因为它经过多次的修改。如果你并不明白什么时串行还是并行,可以通过接下来的例子了解,假设我们在一个方法体里面有如下两行代码:
1 | new AsyncTask1.execute(); |
在1.6(Donut)之前:
在第一版的AsyncTask,任务是串行调度。一个任务执行完成另一个才能执行。由于串行执行任务,使用多个AsyncTask可能会带来有些问题。所以这并不是一个很好的处理异步(尤其是需要将结果作用于UI试图)操作的方法。
从1.6到2.3(Gingerbread)
后来Android团队决定让AsyncTask并行来解决1.6之前引起的问题,这个问题是解决了,新的问题又出现了。很多开发者实际上依赖于顺序执行的行为。于是很多并发的问题蜂拥而至。
3.0(Honeycomb)到现在
好吧,开发者可能并不喜欢让AsyncTask并行,于是Android团队又把AsyncTask改成了串行。当然这一次的修改并没有完全禁止AsyncTask并行。你可以通过设置executeOnExecutor(Executor)来实现多个AsyncTask并行。关于API文档的描述如下
If we want to make sure we have control over the execution, whether it will run serially or parallel, we can check at runtime with this code to make sure it runs parallel
6.真的需要AsyncTask么
并非如此,使用AsyncTask虽然可以以简短的代码实现异步操作,但是正如本文提到的,你需要让AsyncTask正常工作的话,需要注意很多条条框框。推荐的一种进行异步操作的技术就是使用Loaders。这个方法从Android 3.0 (Honeycomb)开始引入,在android支持包中也有包含。可以通过查看官方的文档来详细了解Loaders。
HandlerThread
HandlerThread是Thread的一个子类,HandlerThread自带Looper使他可以通过消息队列来重复使用当前线程,节省系统资源开销。这是它的优点也是缺点,每一个任务都将以队列的方式逐个被执行到,一旦队列中有某个任务执行时间过长,那么就会导致后续的任务都会被延迟处理。它的使用也比较简单
1 | HandlerThread thread = new HandlerThread("MyHandlerThread"); |
HandlerThread的源码
1 | public class HandlerThread extends Thread { |
它的代码比较短,我们主要来看一下它的run()方法,我们发现它和普通Thread不同之处在于它在run()方法内创建了一个消息队列(如果不太了解消息机制的同学可以看一下Android中的消息机制来了解一下),然后来通过Handler的消息的方式来通知HandlerThread执行下一个具体的任务。由于HandlerThread的run()方法内Looper是个无限循环,所以当我们不需要使用HandlerThread的时候可以通过qiut()的方法来终止。
1 | public boolean quit() { |
quit()实际上就是让run()内的Looper停止循环。
当我们使用HandlerThread创建一个线程,它statr()之后会在它的线程创建一个Looper对象且初始化了一个MessageQueue(消息队列),通过Looper对象在他的线程构建一个Handler对象,然后我们通过Handler发送消息的形式将任务发送到MessageQueue中,因为Looper是顺序处理消息的,所以当有多个任务存在时就会顺序的排队执行。当我们不使用的时候我们应该调用它的quit()或者quitSafely()来终止它的循环。
https://blog.csdn.net/carson_ho/article/details/79285760
插件化和组件化
https://juejin.im/post/6844903649102004231
https://www.jianshu.com/p/79e4df63f31f
https://www.jianshu.com/p/b42b5ce09e2c
64匹马,8个赛道,找出前4名最少比赛多少场?
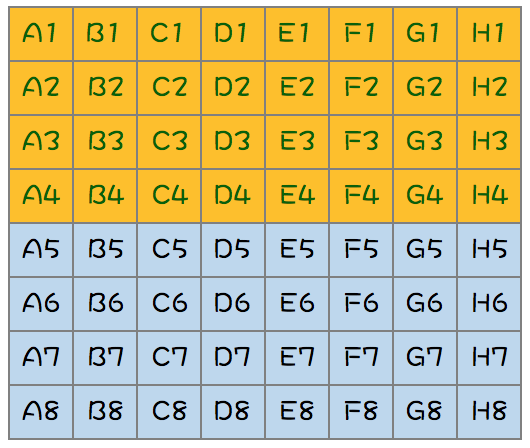
第一步:全部马分8组,各跑一次,然后淘汰掉每组的后四名(8次);
第二步:取每组第一名进行一次比赛,然后淘汰最后四名所在组的所有马(1次):
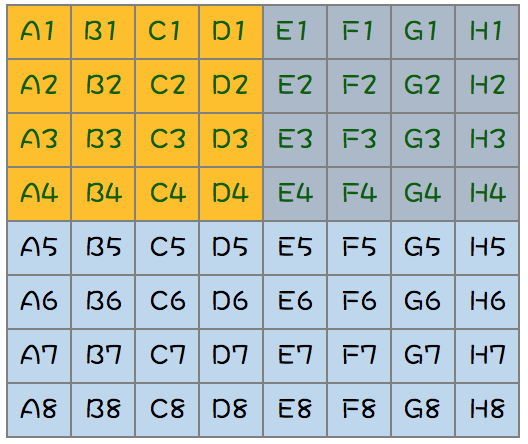
分析:其实这时候红色区域的马也可以淘汰了,A1可以直接晋级;
第三步:A2、A3、A4、B2、B3、C1、C2、D1八匹马跑一次,即:在剩下需要排名的马中,除了B1外,其它8匹马跑一次(1次)
分类讨论:
1、如果这次排名,B2或C1能进前三名,则加上B1后,B1一定能进前三名,因为B1 排名比B2和C1都要靠前;
到此比赛可以结束了;这种情况8+1+1=10次出结果;
2、如果这次排名,B2或C1不能进入前三名,则需要再进行一次比赛,B1、A2、A3、A4进行,取前三名:
这种情况8+1+1+1=11次出结果。
application context不能干嘛
Context到底是什么
Context的中文翻译为:语境; 上下文; 背景; 环境,在开发中我们经常说称之为“上下文”,那么这个“上下文”到底是指什么意思呢?在语文中,我们可以理解为语境,在程序中,我们可以理解为当前对象在程序中所处的一个环境,一个与系统交互的过程。比如微信聊天,此时的“环境”是指聊天的界面以及相关的数据请求与传输,Context在加载资源、启动Activity、获取系统服务、创建View等操作都要参与。
那Context到底是什么呢?一个Activity就是一个Context,一个Service也是一个Context。Android程序员把“场景”抽象为Context类,他们认为用户和操作系统的每一次交互都是一个场景,比如打电话、发短信,这些都是一个有界面的场景,还有一些没有界面的场景,比如后台运行的服务(Service)。一个应用程序可以认为是一个工作环境,用户在这个环境中会切换到不同的场景,这就像一个前台秘书,她可能需要接待客人,可能要打印文件,还可能要接听客户电话,而这些就称之为不同的场景,前台秘书可以称之为一个应用程序。
如何生动形象的理解Context
上面的概念中采用了通俗的理解方式,将Context理解为“上下文”或者“场景”,如果你仍然觉得很抽象,不好理解。在这里我给出一个可能不是很恰当的比喻,希望有助于大家的理解:一个Android应用程序,可以理解为一部电影或者一部电视剧,Activity,Service,Broadcast Receiver,Content Provider这四大组件就好比是这部戏里的四个主角:胡歌,霍建华,诗诗,Baby。他们是由剧组(系统)一开始就定好了的,整部戏就是由这四位主演领衔担纲的,所以这四位主角并不是大街上随随便便拉个人(new 一个对象)都能演的。有了演员当然也得有摄像机拍摄啊,他们必须通过镜头(Context)才能将戏传递给观众,这也就正对应说四大组件(四位主角)必须工作在Context环境下(摄像机镜头)。那Button,TextView,LinearLayout这些控件呢,就好比是这部戏里的配角或者说群众演员,他们显然没有这么重用,随便一个路人甲路人乙都能演(可以new一个对象),但是他们也必须要面对镜头(工作在Context环境下),所以Button mButton=new Button(Context)是可以的。虽然不很恰当,但还是很容易理解的,希望有帮助。
源码中的Context
1 | /** |
源码中的注释是这么来解释Context的:Context提供了关于应用环境全局信息的接口。它是一个抽象类,它的执行被Android系统所提供。它允许获取以应用为特征的资源和类型,是一个统领一些资源(应用程序环境变量等)的上下文。就是说,它描述一个应用程序环境的信息(即上下文);是一个抽象类,Android提供了该抽象类的具体实现类;通过它我们可以获取应用程序的资源和类(包括应用级别操作,如启动Activity,发广播,接受Intent等)。既然上面Context是一个抽象类,那么肯定有他的实现类咯,我们在Context的源码中通过IDE可以查看到他的子类最终可以得到如下关系图:
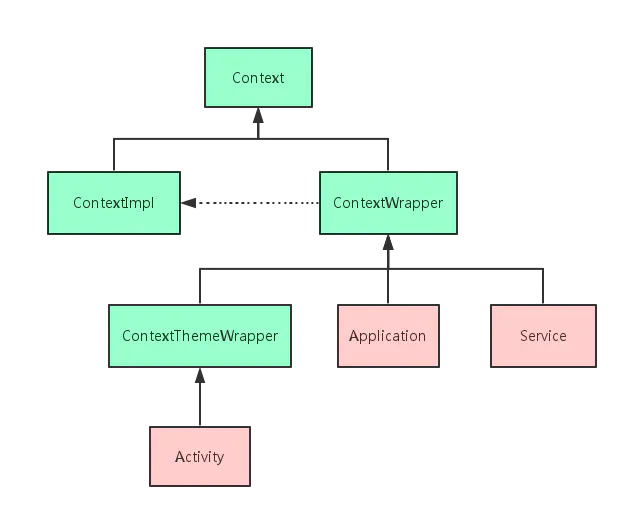
Context类本身是一个纯abstract类,它有两个具体的实现子类:ContextImpl和ContextWrapper。其中ContextWrapper类,如其名所言,这只是一个包装而已,ContextWrapper构造函数中必须包含一个真正的Context引用,同时ContextWrapper中提供了attachBaseContext()用于给ContextWrapper对象中指定真正的Context对象,调用ContextWrapper的方法都会被转向其所包含的真正的Context对象。ContextThemeWrapper类,如其名所言,其内部包含了与主题(Theme)相关的接口,这里所说的主题就是指在AndroidManifest.xml中通过android:theme为Application元素或者Activity元素指定的主题。当然,只有Activity才需要主题,Service是不需要主题的,因为Service是没有界面的后台场景,所以Service直接继承于ContextWrapper,Application同理。而ContextImpl类则真正实现了Context中的所以函数,应用程序中所调用的各种Context类的方法,其实现均来自于该类。一句话总结:Context的两个子类分工明确,其中ContextImpl是Context的具体实现类,ContextWrapper是Context的包装类。Activity,Application,Service虽都继承自ContextWrapper(Activity继承自ContextWrapper的子类ContextThemeWrapper),但它们初始化的过程中都会创建ContextImpl对象,由ContextImpl实现Context中的方法。
一个应用程序有几个Context
其实这个问题本身并没有什么意义,关键还是在于对Context的理解,从上面的关系图我们已经可以得出答案了,在应用程序中Context的具体实现子类就是:Activity,Service,Application。那么Context数量=Activity数量+Service数量+1。当然如果你足够细心,可能会有疑问:我们常说四大组件,这里怎么只有Activity,Service持有Context,那Broadcast Receiver,Content Provider呢?Broadcast Receiver,Content Provider并不是Context的子类,他们所持有的Context都是其他地方传过去的,所以并不计入Context总数。上面的关系图也从另外一个侧面告诉我们Context类在整个Android系统中的地位是多么的崇高,因为很显然Activity,Service,Application都是其子类,其地位和作用不言而喻。
Context作用域
虽然Context神通广大,但并不是随便拿到一个Context实例就可以为所欲为,它的使用还是有一些规则限制的。由于Context的具体实例是由ContextImpl类去实现的,因此在绝大多数场景下,Activity、Service和Application这三种类型的Context都是可以通用的。不过有几种场景比较特殊,比如启动Activity,还有弹出Dialog。出于安全原因的考虑,Android是不允许Activity或Dialog凭空出现的,一个Activity的启动必须要建立在另一个Activity的基础之上,也就是以此形成的返回栈。而Dialog则必须在一个Activity上面弹出(除非是System Alert类型的Dialog),因此在这种场景下,我们只能使用Activity类型的Context,否则将会出错。
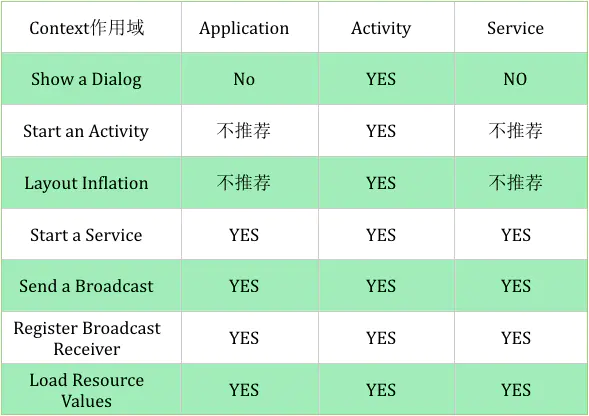
从上图我们可以发现Activity所持有的Context的作用域最广,无所不能。因为Activity继承自ContextThemeWrapper,而Application和Service继承自ContextWrapper,很显然ContextThemeWrapper在ContextWrapper的基础上又做了一些操作使得Activity变得更强大,这里我就不再贴源码给大家分析了,有兴趣的童鞋可以自己查查源码。上图中的YES和NO我也不再做过多的解释了,这里我说一下上图中Application和Service所不推荐的两种使用情况。
1:如果我们用ApplicationContext去启动一个LaunchMode为standard的Activity的时候会报错android.util.AndroidRuntimeException: Calling startActivity from outside of an Activity context requires the FLAG_ACTIVITY_NEW_TASK flag. Is this really what you want?这是因为非Activity类型的Context并没有所谓的任务栈,所以待启动的Activity就找不到栈了。解决这个问题的方法就是为待启动的Activity指定FLAG_ACTIVITY_NEW_TASK标记位,这样启动的时候就为它创建一个新的任务栈,而此时Activity是以singleTask模式启动的。所有这种用Application启动Activity的方式不推荐使用,Service同Application。
2:在Application和Service中去layout inflate也是合法的,但是会使用系统默认的主题样式,如果你自定义了某些样式可能不会被使用。所以这种方式也不推荐使用。
一句话总结:凡是跟UI相关的,都应该使用Activity做为Context来处理;其他的一些操作,Service,Activity,Application等实例都可以,当然了,注意Context引用的持有,防止内存泄漏。
如何获取Context
通常我们想要获取Context对象,主要有以下四种方法
1:View.getContext,返回当前View对象的Context对象,通常是当前正在展示的Activity对象。
2:Activity.getApplicationContext,获取当前Activity所在的(应用)进程的Context对象,通常我们使用Context对象时,要优先考虑这个全局的进程Context。
3:ContextWrapper.getBaseContext():用来获取一个ContextWrapper进行装饰之前的Context,可以使用这个方法,这个方法在实际开发中使用并不多,也不建议使用。
4:Activity.this 返回当前的Activity实例,如果是UI控件需要使用Activity作为Context对象,但是默认的Toast实际上使用ApplicationContext也可以。
Application中的Context和Activity中的Context的区别
在需要传递Context参数的时候,如果是在Activity中,我们可以传递this(这里的this指的是Activity.this,是当前Activity的上下文)或者Activity.this。这个时候如果我们传入getApplicationContext(),我们会发现这样也是可以用的。可是大家有没有想过传入Activity.this和传入getApplicationContext()的区别呢?首先Activity.this和getApplicationContext()返回的不是同一个对象,一个是当前Activity的实例,一个是项目的Application的实例,这两者的生命周期是不同的,它们各自的使用场景不同,this.getApplicationContext()取的是这个应用程序的Context,它的生命周期伴随应用程序的存在而存在;而Activity.this取的是当前Activity的Context,它的生命周期则只能存活于当前Activity,这两者的生命周期是不同的。getApplicationContext() 生命周期是整个应用,当应用程序摧毁的时候,它才会摧毁;Activity.this的context是属于当前Activity的,当前Activity摧毁的时候,它就摧毁。
getApplication()和getApplicationContext()
上面说到获取当前Application对象用getApplicationContext,不知道你有没有联想到getApplication(),这两个方法有什么区别?相信这个问题会难倒不少开发者。
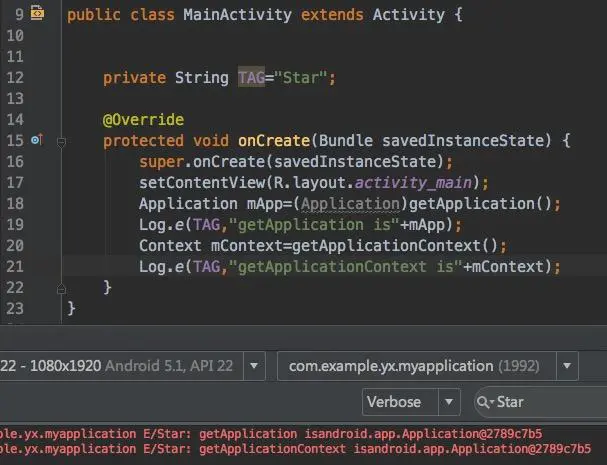
getApplication()&getApplicationContext().png
程序是不会骗人的,我们通过上面的代码,打印得出两者的内存地址都是相同的,看来它们是同一个对象。其实这个结果也很好理解,因为前面已经说过了,Application本身就是一个Context,所以这里获取getApplicationContext()得到的结果就是Application本身的实例。那么问题来了,既然这两个方法得到的结果都是相同的,那么Android为什么要提供两个功能重复的方法呢?实际上这两个方法在作用域上有比较大的区别。getApplication()方法的语义性非常强,一看就知道是用来获取Application实例的,但是这个方法只有在Activity和Service中才能调用的到。那么也许在绝大多数情况下我们都是在Activity或者Service中使用Application的,但是如果在一些其它的场景,比如BroadcastReceiver中也想获得Application的实例,这时就可以借助getApplicationContext()方法了。
正确使用Context
一般Context造成的内存泄漏,几乎都是当Context销毁的时候,却因为被引用导致销毁失败,而Application的Context对象可以理解为随着进程存在的,所以我们总结出使用Context的正确姿势:
1:当Application的Context能搞定的情况下,并且生命周期长的对象,优先使用Application的Context。
2:不要让生命周期长于Activity的对象持有到Activity的引用。
3:尽量不要在Activity中使用非静态内部类,因为非静态内部类会隐式持有外部类实例的引用,如果使用静态内部类,将外部实例引用作为弱引用持有。
为什么 Dialog不能使用Application的Context
参考简书
图片三级缓存加载
参考简书
AtomicInteger如何保证线程安全
1 | public class AtomicInteger extends Number implements java.io.Serializable { |
- 用volatile关键字修饰value字段
AtomicInteger用value字段来存储数据值,volatile关键字保证了value字段对各个线程的可见性。各线程读取value字段时,会先从主内存把数据同步到工作内存,这样保证可见性。 - Unsafe实现操作原子性,用户在使用时无需额外的同步操作。
如AtomicInteger提供了自增方法getAndIncrement,其内部实现是由Unsafe类的compareAndSetInt方法来保证的。
1 | // jdk.internal.misc.Unsafe |
compareAndSetInt方法是一个CAS操作,用native关键字修饰。
原理:先比较内存中的值与expected是否一致,一致的前提下才赋予新的值x,此时返回true,否则返回false。
锁升级机制
参考CSDN
为什么内部类会默认持有外部类的引用?
Java中,非静态的内部类和匿名内部类都会隐式地持有其外部类的引用。静态的内部类不会持有外部类的引用。
关于内部类如何访问外部类的成员, 分析之后其实也很简单, 主要是通过以下几步做到的:
1 编译器自动为内部类添加一个成员变量, 这个成员变量的类型和外部类的类型相同, 这个成员变量就是指向外部类对象的引用;
2 编译器自动为内部类的构造方法添加一个参数, 参数的类型是外部类的类型, 在构造方法内部使用这个参数为1中添加的成员变量赋值;
3 在调用内部类的构造函数初始化内部类对象时, 会默认传入外部类的引用。
View中的post和handler的post有什么区别?
参考掘金
Handler的工作机制,网上介绍的文章太多了,这里我就不赘述了,想继续了解的同学可以参考下这篇文章:Handler源码分析。一句话总结就是通过Handler对象,不论是post Msg还是Runnable,最终都是构造了一个Msg对象,插入到与之对应的Looper的MessageQueue中,不同的是Running时msg对象的callback字段设成了Runnable的值。稍后这条msg会从队列中取出来并且得到执行,UI线程就是这么一个基于事件的循环。所以可以看出Handler.post相关的代码在onCreate里那一刻时就已经开始了执行(加入到了队列,下次循环到来时就会被真正执行了)。
View.post
要解释它的行为,我们就必须深入代码中去找答案了,其代码如下:
1 | public boolean post(Runnable action) { |
从上面的源码,我们大概可以看出mAttachInfo字段在这里比较关键,当其有值时,其实和普通的Handler.post就没区别了,但有时它是没值的,比如我们上面示例代码里的onCreate阶段,那么这时执行到了getRunQueue().post(action);这行代码,从这段注释也大概可以看出来真正的执行会被延迟(这里的Postpone注释);我们接着往下看看getRunQueue相关的代码,如下:
1 | /** 其实这段注释已经说的很清楚明了了!!! |
从上面我们可以看出,mRunQueue就是View用来处理它还没attach到window(还没对应的handler)时,客户代码发起的post调用的,起了一个临时缓存的作用。不然总不能丢弃吧,这样开发体验就太差了!!!
紧接着,我们继续看下HandlerActionQueue类型的定义,代码如下:
1 | public class HandlerActionQueue { |
注意:这里的源码部分,我们只摘录了部分关键代码,其余不太相关的直接略去了。
从这里可以看出,我们前面的View.post调用里的Runnable最终会被存储在这里的mActions数组里,这里最关键的一点就是其executeActions方法,因为这个方法里我们之前post的Runnable才真正通过handler.postDelayed方式使其进入handler对应的消息队列里等待执行;
到此为止,我们还差知道View里的mAttachInfo字段何时被赋值以及这里的executeActions方法是什么时候被触发的,答案就是在View的dispatchAttachedToWindow方法,其关键源码如下:
1 | void dispatchAttachedToWindow(AttachInfo info, int visibility) { |
而通过之前的文章,我们已经知道了此方法是当Act Resume之后,在ViewRootImpl.performTraversals()中触发的,参考View.onAttachedToWindow调用时机分析。
总结
- Handler.post,它的执行时间基本是等同于onCreate里那行代码触达的时间;
- View.post,则不同,它说白了执行时间一定是在
Act#onResume发生后才开始算的;或者换句话说它的效果相当于你上面的View.post方法是写在Act#onResume里面的(但只执行一次,因为onCreate不像onResume会被多次触发); - 当然,虽然这里说的是
post方法,但对应的postDelayed方法区别也是类似的。
平时当你项目很小,MainActivity的逻辑也很简单时是看不出啥区别的,但当act的onCreate到onResume之间耗时比较久时(比如2s以上),就能明显感受到这2者的区别了,而且本身它们的实际含义也是很不同的,前者的Runnable真正执行时,可能act的整个view层次都还没完整的measure、layout完成,但后者的Runnable执行时,则一定能保证act的view层次结构已经measure、layout并且至少绘制完成了一次。
margin,padding,align
android : layout_marginxxx的用法是指当前组件距离其父组件在xxx方向上的边距
android : padding(xxx) —- padding是相对于当前组件而言的,就是指组件内的文本距离当前组件xxx位置的边距
align就是各种对齐的意思
与指定的组件某位置的边缘进行对其
比如说 : android: layout_alignxxx = “yyy” —- 其中xxx代表方位,yyy代表想要和哪个组件对齐,相应组件的id
与父组件的某位置的边缘(上下左右)对其.
android : layout_alignParentXxx —- 当前组件和其父组件的Xxx位置对齐
Android 自定义属性
https://blog.csdn.net/lmj623565791/article/details/45022631
https://blog.csdn.net/wzy_1988/article/details/49619773
Android app的打包流程,各种文件分别如何处理
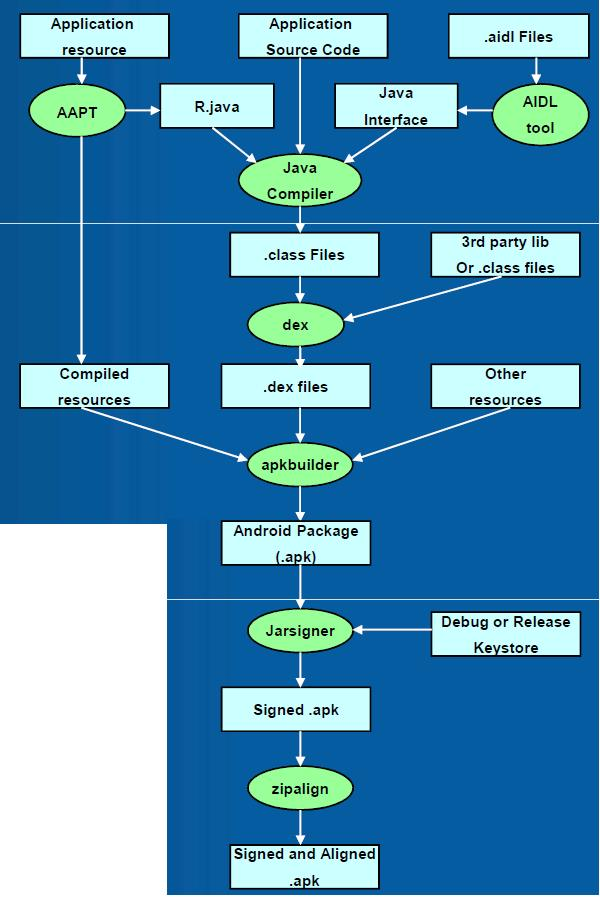
aapt->
aidl -> javac-> dx(dex)-> apkbuilder-> jarsigner-> zipalign
步骤中提到的工具如下表:
| 名称 | 功能介绍 | 在操作系统中的路径 |
|---|---|---|
| aapt | Android资源打包工具 | ${ANDROID_SDK_HOME}/platform-tools/appt |
| aidl | Android接口描述语言转化为.java文件的工具 | ${ANDROID_SDK_HOME}/platform-tools/aidl |
| javac | Java Compiler | ${JDK_HOME}/javac或/usr/bin/javac |
| dex | 转化.class文件为Davik VM能识别的.dex文件 | ${ANDROID_SDK_HOME}/platform-tools/dx |
| apkbuilder | 生成apk包 | ${ANDROID_SDK_HOME}/tools/opkbuilder |
| jarsigner | .jar文件的签名工具 | ${JDK_HOME}/jarsigner或/usr/bin/jarsigner |
| zipalign | 字节码对齐工具 | ${ANDROID_SDK_HOME}/tools/zipalign |
第一步:打包资源文件,生成R.java文件
编译R.java类需要用到AndroidSDK提供的aapt工具,aapt参数众多,以下是主要参数:
- -d one or more device assets to include, separated by commas
- -f force overwrite of existing files
- -g specify a pixel tolerance to force images to grayscale, default 0
- -j specify a jar or zip file containing classes to include
- -k junk path of file(s) added
- -m make package directories under location specified by -J
- -u update existing packages (add new, replace older, remove deleted files)
- -v verbose output
- -x create extending (non-application) resource IDs
- -z require localization of resource attributes marked with
- localization=”suggested”
- -A additional directory in which to find raw asset files
- -G A file to output proguard options into.
- -F specify the apk file to output
- -I add an existing package to base include set
- -J specify where to output R.java resource constant definitions
- -M specify full path to AndroidManifest.xml to include in zip
- -P specify where to output public resource definitions
- -S directory in which to find resources. Multiple directories will be scann
aapt编译R.java文件具体如下:
需要进入应用程序目录,新建一个gen目录,没有gen目录,命令将会出现找不到文件的错误!
命令成功执行后将会在gen目录下生成成包结构的目录树,及R.java文件!

第二步:处理AIDL文件,生成对应的.java文件(当然,有很多工程没有用到AIDL,那这个过程就可以省了)
将.aidl文件生成.java文件需要用到AndroidSDK自带的aidl工具,此工具具体参数如下:
- -I
search path for import statements. - -d
generate dependency file. - -p
file created by —preprocess to import. - -o
base output folder for generated files. - -b fail when trying to compile a parcelable.
- 值得注意的是:这个工具的参数与参数值之间不能有空格,Google也有对工资不满意的工程师!

第三步:编译Java文件,生成对应的.class文件
javac命令用法如下:
- 其中,可能的选项包括:
- -g 生成所有调试信息
- -g:none 不生成任何调试信息
- -g:{lines,vars,source} 只生成某些调试信息
- -nowarn 不生成任何警告
- -verbose 输出有关编译器正在执行的操作的消息
- -deprecation 输出使用已过时的 API 的源位置
- -classpath <路径> 指定查找用户类文件和注释处理程序的位置
- -cp <路径> 指定查找用户类文件和注释处理程序的位置
- -sourcepath <路径> 指定查找输入源文件的位置
- -bootclasspath <路径> 覆盖引导类文件的位置
- -extdirs <目录> 覆盖安装的扩展目录的位置
- -endorseddirs <目录> 覆盖签名的标准路径的位置
- -proc:{none,only} 控制是否执行注释处理和/或编译。
- -processor
[, , …]要运行的注释处理程序的名称;绕过默认的搜索进程 - -processorpath <路径> 指定查找注释处理程序的位置
- -d <目录> 指定存放生成的类文件的位置
- -s <目录> 指定存放生成的源文件的位置
- -implicit:{none,class} 指定是否为隐式引用文件生成类文件
- -encoding <编码> 指定源文件使用的字符编码
- -source <版本> 提供与指定版本的源兼容性
- -target <版本> 生成特定 VM 版本的类文件
- -version 版本信息
- -help 输出标准选项的提要
- -Akey[=value] 传递给注释处理程序的选项
- -X 输出非标准选项的提要
-J<标志> 直接将 <标志> 传递给运行时系统
javac -encoding utf-8 -target 1.5 -bootclasspath E:\Androiddev\android-sdk-windows2.2\platforms\android-3\android.jar -d bin src\com\byread\reader*.java gen\com\byread\reader\R.java
第四步:把.class文件转化成Davik VM支持的.dex文件
将工程bin目录下的class文件编译成classes.dex,Android虚拟机只能执行dex文件!

第五步:打包生成未签名的.apk文件
【输入】打包后的资源文件、打包后类文件(.dex文件)、libs文件(包括.so文件,当然很多工程都没有这样的文件,如果你不使用C/C++开发的话)
【输出】未签名的.apk文件
【工具】apkbuilder工具
apkbuilder工具用法如下:
- -v Verbose.
- -d Debug Mode: Includes debug files in the APK file.
- -u Creates an unsigned package.
- -storetype Forces the KeyStore type. If ommited the default is used.
- -z Followed by the path to a zip archive.
- Adds the content of the application package.
- -f Followed by the path to a file.
- Adds the file to the application package.
- -rf Followed by the path to a source folder.
- Adds the java resources found in that folder to the application
- package, while keeping their path relative to the source folder.
- -rj Followed by the path to a jar file or a folder containing
- jar files.
- Adds the java resources found in the jar file(s) to the application
- package.
- -nf Followed by the root folder containing native libraries to
include in the application package.I:最后一步,通过jarsigner命令用证书文件对未签名的APK文件进行签名
apkbuilder ${output.apk.file} -u -z ${packagedresource.file} -f ${dex.file} -rf ${source.dir} -rj ${libraries.dir}
第六步:对未签名.apk文件进行签名
【输入】未签名的.apk文件
【输出】签名的.apk文件
【工具】jarsigner
第七步:对签名后的.apk文件进行对齐处理(不进行对齐处理是不能发布到Google Market的)
【输入】签名后的.apk文件
【输出】对齐后的.apk文件
【工具】zipalign工具
数据库sqlite 索引
索引(Index)是一种特殊的查找表,数据库搜索引擎用来加快数据检索。简单地说,索引是一个指向表中数据的指针。一个数据库中的索引与一本书的索引目录是非常相似的。
拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。
索引有助于加快 SELECT 查询和 WHERE 子句,但它会减慢使用 UPDATE 和 INSERT 语句时的数据输入。索引可以创建或删除,但不会影响数据。
B-树与索引
大多数的数据库都是以B-树或者B+树作为存储结构的,B树索引也是最常见的索引。先简单介绍下B-树,可以增强对索引的理解。
B-树是为磁盘设计的一种多叉平衡树,B树的真正最准确的定义为:一棵含有t(t>=2)个关键字的平衡多路查找树。一棵M阶的B树满足以下条件:
- 每个结点至多有M个孩子
- 除根结点和叶结点外,其它每个结点至少有M/2个孩子
- 根结点至少有两个孩子(除非该树仅包含一个结点)
- 所有叶结点在同一层,叶结点不包含任何关键字信息,可以看作一种外部节点
- 有K个关键字的非叶结点恰好包含K+1个孩子
B树中的每个结点根据实际情况可以包含大量的关键字信息和分支(当然是不能超过磁盘块的大小,根据磁盘驱动(disk drives)的不同,一般块的大小在1k~4k左右);这样树的深度降低了,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存,很快访问到要查找的数据。B-树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成。而相对于磁盘的io速度,cpu的计算时间可以忽略不计,所以B树的意义就显现出来了,树的深度降低,而深度决定了io的读写次数。
B树索引是一个典型的树结构,其包含的组件主要是:
- 叶子节点(Leaf node):包含条目直接指向表里的数据行。
- 分支节点(Branch node):包含的条目指向索引里其他的分支节点或者是叶子节点。
- 根节点(Root node):一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
如下图所示:
每个索引都包含两部分内容,一部分是索引本身的值,第二部分即指向数据页或者另一个索引也的指针。每个节点即为一个索引页,包含了多个索引。
当你为一个空表建立一个索引,数据库会分配一个空的索引页,这个索引页即代表根节点,在你插入数据之前,这个索引页都是空的。每当你插入数据,数据库就会在根节点创建索引条目。当根节点插满的时候,再插入数据时,根节点就会分裂。举个例子,根节点插入了如图所示的数据。(超过4个就分裂),这时候插入H,就会分裂成2个节点,移动G到新的根节点,把H和N放在新的右孩子节点中。如图所示:
根节点插满4个节点
插入H,进行分裂。
大致的分裂步骤如下:
- 创建两个子节点
- 将原节点中的数据近似分为两半,写入两个新的孩子节点中。
- 在根节点中放置指向页节点的指针
- 将原节点中的数据近似分为两半,写入两个新的孩子节点中。
当你不断向表中插入数据,根节点中指向叶节点的指针也被插满,当叶子还需要分裂的时候,根节点没有空间再创建指向新的叶节点的指针。那么数据库就会创建分支节点。随着叶子节点的分裂,根节点中的指针都指向了这些分支节点。随着数据的不断插入,索引会增加更多的分支节点,使树结构变成这样的一个多级结构。
索引的种类
- 聚集索引
表中行的物理顺序与键值的逻辑(索引)顺序相同。因为数据的物理顺序只能有一种,所以一张表只能有一个聚集索引。如果一张表没有聚集索引,那么这张表就没有顺序的概念,所有的新行都会插入到表的末尾。对于聚集索引,叶节点即存储了数据行,不再有单独的数据页。就比如说我小时候查字典从来不看目录,我觉得字典本身就是一个目录,比如查裴字,只需要翻到p字母开头的,再按顺序找到e。通过这个方法我每次都能最快的查到老师说的那个字,得到老师的表扬。 - 非聚集索引
表中行的物理顺序与索引顺序无关。对于非聚集索引,叶节点存储了索引字段值以及指向相应数据页的指针。叶节点紧邻在数据之上,对数据页的每一行都有相应的索引行与之对应。有时候查字典,我并不知道这个字读什么,那我就不得不通过字典目录的“部首”来查找了。这时候我会发现,目录中的排序和实际正文的排序是不一样的,这对我来说很苦恼,因为我不能比别人快了,我需要先再目录中找到这个字,再根据页数去找到正文中的字。
索引与数据的查询,插入与删除
- 查询
查询操作就和查字典是一样的。当我们去查找指定记录时,数据库会先查找根节点,将待查数据与根节点的数据进行比较,再通过根节点的指针查询下一个记录,直到找到这个记录。这是一个简单的平衡树的二分搜索的过程,我就不赘述了。在聚集索引中,找到页节点即找到了数据行,而在非聚集索引中,我们还需要再去读取数据页。 - 插入
聚集索引的插入操作比较复杂,最简单的情况,插入操作会找到对于的数据页,然后为新数据腾出空间,执行插入操作。如果该数据页已经没有空间,那就需要拆分数据页,这是一个非常耗费资源的操作。对于仅有非聚集索引的表,插入只需在表的末尾插入即可。如果也包含了聚集索引,那么也会执行聚集索引需要的插入操作。 - 删除
删除行后下方的数据会向上移动以填补空缺。如果删除的数据是该数据页的最后一行,那么这个数据页会被回收,它的前后一页的指针会被改变,被回收的数据页也会在特定的情况被重新使用。与此同时,对于聚集索引,如果索引页只剩一条记录,那么该记录可能会移动到邻近的索引表中,原来的索引页也会被回收。而非聚集索引没办法做到这一点,这就会导致出现多个数据页都只有少量数据的情况。
索引的优缺点
其实通过前面的介绍,索引的优缺点已经一目了然。
先说优点:
- 大大加快数据的检索速度,这也是创建索引的最主要的原因
- 加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
再说缺点:
- 创建索引需要耗费一定的时间,但是问题不大,一般索引只要build一次
- 索引需要占用物理空间,特别是聚集索引,需要较大的空间
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度,这个是比较大的问题。
索引的使用
根据上文的分析,我们大致对什么时候使用索引有了自己的想法。一般我们需要在这些列上建立索引:
- 在经常需要搜索的列上,这是毋庸置疑的
- 经常同时对多列进行查询,且每列都含有重复值可以建立组合索引,组合索引尽量要使常用查询形成索引覆盖(查询中包含的所需字段皆包含于一个索引中,我们只需要搜索索引页即可完成查询)。同时,该组合索引的前导列一定要是使用最频繁的列。对于前导列的问题,在后面SQLite的索引使用介绍中还会做讨论。
- 在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度,连接条件要充分考虑带有索引的表。
- 在经常需要对范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的,同样,在经常需要排序的列上最好也创建索引。
- 在经常放到where子句中的列上面创建索引,加快条件的判断速度。要注意的是where字句中对列的任何操作(如计算表达式,函数)都需要对表进行整表搜索,而没有使用该列的索引。所以查询时尽量把操作移到等号右边。
使用 CREATE INDEX 语句创建索引,它允许命名索引,指定表及要索引的一列或多列,并指示索引是升序排列还是降序排列。
索引也可以是唯一的,与 UNIQUE 约束类似,在列上或列组合上防止重复条目。
CREATE INDEX 的基本语法如下:
1 | CREATE INDEX index_name ON table_name; |
单列索引是一个只基于表的一个列上创建的索引。基本语法如下:
1 | CREATE INDEX index_name |
使用唯一索引不仅是为了性能,同时也为了数据的完整性。唯一索引不允许任何重复的值插入到表中。基本语法如下:
1 | CREATE UNIQUE INDEX index_name |
组合索引是基于一个表的两个或多个列上创建的索引。基本语法如下:
1 | CREATE INDEX index_name |
是否要创建一个单列索引还是组合索引,要考虑到您在作为查询过滤条件的 WHERE 子句中使用非常频繁的列。
如果值使用到一个列,则选择使用单列索引。如果在作为过滤的 WHERE 子句中有两个或多个列经常使用,则选择使用组合索引。
什么情况下要避免使用索引?
虽然索引的目的在于提高数据库的性能,但这里有几个情况需要避免使用索引。使用索引时,应重新考虑下列准则:
- 索引不应该使用在较小的表上。
- 索引不应该使用在有频繁的大批量的更新或插入操作的表上。
- 索引不应该使用在含有大量的 NULL 值的列上。
- 索引不应该使用在频繁操作的列上。
- 含有很少非重复数据值的列,比如只有0,1,这时候扫描整表通常会更有效
- 对于定义为
TEXT,IMAGE的数据不应该创建索引。这些字段长度不固定,或许很长,或许为空。
abc三个线程循环顺序打印26个字母
使用Semaphore
Semaphore又称信号量,是操作系统中的一个概念,在Java并发编程中,信号量控制的是线程并发的数量。
public Semaphore(int permits)
其中参数permits就是允许同时运行的线程数目;
Semaphore是用来保护一个或者多个共享资源的访问,Semaphore内部维护了一个计数器,其值为可以访问的共享资源的个数。一个线程要访问共享资源,先获得信号量,如果信号量的计数器值大于1,意味着有共享资源可以访问,则使其计数器值减去1,再访问共享资源。如果计数器值为0,线程进入休眠。当某个线程使用完共享资源后,释放信号量,并将信号量内部的计数器加1,之前进入休眠的线程将被唤醒并再次试图获得信号量。
Semaphore使用时需要先构建一个参数来指定共享资源的数量,Semaphore构造完成后即是获取Semaphore、共享资源使用完毕后释放Semaphore。
1 | private static volatile char a = 'A'; |
使用lock
通过ReentrantLock我们可以很方便的进行显式的锁操作,即获取锁和释放锁,对于同一个对象锁而言,统一时刻只可能有一个线程拿到了这个锁,此时其他线程通过lock.lock()来获取对象锁时都会被阻塞,直到这个线程通过lock.unlock()操作释放这个锁后,其他线程才能拿到这个锁。
1 | private static volatile char a = 'A'; |
ReentrantLock结合Condition
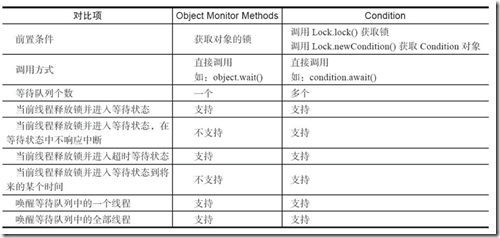
首先我们需要明白condition对象是依赖于lock对象的,意思就是说condition对象需要通过lock对象进行创建出来(调用Lock对象的newCondition()方法)。consition的使用方式非常的简单。但是需要注意在调用方法前获取锁。
condition可以通俗的理解为条件队列。当一个线程在调用了await方法以后,直到线程等待的某个条件为真的时候才会被唤醒。这种方式为线程提供了更加简单的等待/通知模式。Condition必须要配合锁一起使用,因为对共享状态变量的访问发生在多线程环境下。一个Condition的实例必须与一个Lock绑定,因此Condition一般都是作为Lock的内部实现。
- await() :造成当前线程在接到信号或被中断之前一直处于等待状态。
- await(long time, TimeUnit unit) :造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。
- awaitNanos(long nanosTimeout) :造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。返回值表示剩余时间,如果在nanosTimesout之前唤醒,那么返回值 = nanosTimeout - 消耗时间,如果返回值 <= 0 ,则可以认定它已经超时了。
- awaitUninterruptibly() :造成当前线程在接到信号之前一直处于等待状态。【注意:该方法对中断不敏感】。
- awaitUntil(Date deadline) :造成当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态。如果没有到指定时间就被通知,则返回true,否则表示到了指定时间,返回返回false。
- signal() :唤醒一个等待线程。该线程从等待方法返回前必须获得与Condition相关的锁。
signal()All :唤醒所有等待线程。能够从等待方法返回的线程必须获得与Condition相关的锁。
Condition是AQS的内部类。每个Condition对象都包含一个队列(等待队列)。等待队列是一个FIFO的队列,在队列中的每个节点都包含了一个线程引用,该线程就是在Condition对象上等待的线程,如果一个线程调用了Condition.await()方法,那么该线程将会释放锁、构造成节点加入等待队列并进入等待状态。等待队列的基本结构如下所示。
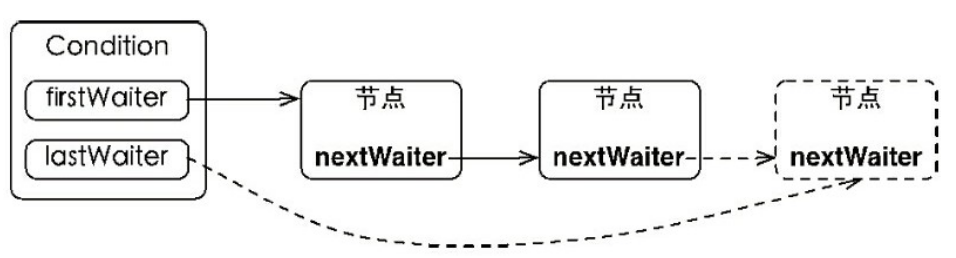
等待分为首节点和尾节点。当一个线程调用Condition.await()方法,将会以当前线程构造节点,并将节点从尾部加入等待队列。新增节点就是将尾部节点指向新增的节点。节点引用更新本来就是在获取锁以后的操作,所以不需要CAS保证。同时也是线程安全的操作。
当线程调用了await方法以后。线程就作为队列中的一个节点被加入到等待队列中去了。同时会释放锁的拥有。当从await方法返回的时候。一定会获取condition相关联的锁。当等待队列中的节点被唤醒的时候,则唤醒节点的线程开始尝试获取同步状态。如果不是通过 其他线程调用Condition.signal()方法唤醒,而是对等待线程进行中断,则会抛出InterruptedException异常信息。
调用Condition的signal()方法,将会唤醒在等待队列中等待最长时间的节点(条件队列里的首节点),在唤醒节点前,会将节点移到同步队列中。当前线程加入到等待队列中如图所示:
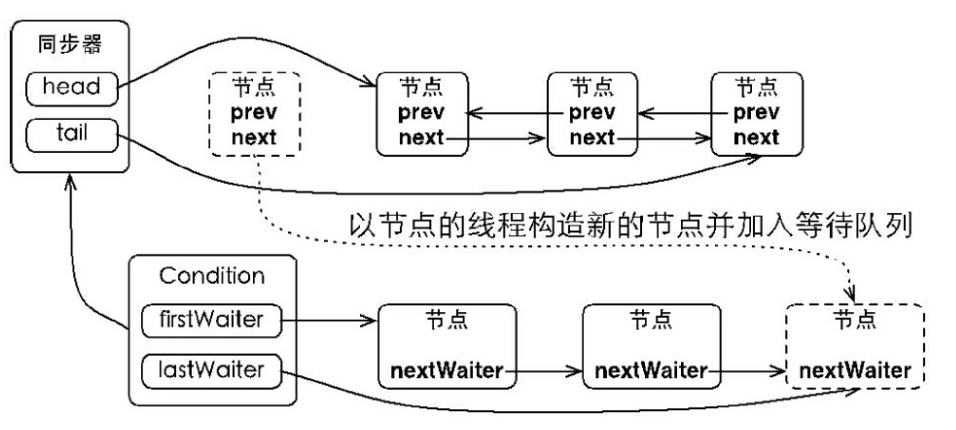
在调用signal()方法之前必须先判断是否获取到了锁。接着获取等待队列的首节点,将其移动到同步队列并且利用LockSupport唤醒节点中的线程。节点从等待队列移动到同步队列如下图所示:

被唤醒的线程将从await方法中的while循环中退出。随后加入到同步状态的竞争当中去。成功获取到竞争的线程则会返回到await方法之前的状态。
调用await方法后,将当前线程加入Condition等待队列中。当前线程释放锁。否则别的线程就无法拿到锁而发生死锁。自旋(while)挂起,不断检测节点是否在同步队列中了,如果是则尝试获取锁,否则挂起。当线程被signal方法唤醒,被唤醒的线程将从await()方法中的while循环中退出来,然后调用acquireQueued()方法竞争同步状态。
1 | private static volatile char a = 'A'; |
环形链表
判断是否有环
1 | ListNode fast = head, slow = head; |
寻找环的起点
1 | //这时候已经相遇 |
具体可参考[环形链表II]
求环上的结点数
1 | int count = 1; |
求链表长度
1 | ListNode p = head; |
求出环上距离任意一个节点最远的点(对面节点)
1 | //找到count / 2的点即可 |
WebSocket心跳及重连机制
在使用websocket的过程中,有时候会遇到网络断开的情况,但是在网络断开的时候服务器端并没有触发onclose的事件。这样会有:服务器会继续向客户端发送多余的链接,并且这些数据还会丢失。所以就需要一种机制来检测客户端和服务端是否处于正常的链接状态。因此就有了websocket的心跳了。还有心跳,说明还活着,没有心跳说明已经挂掉了。
1. 为什么叫心跳包呢?
它就像心跳一样每隔固定的时间发一次,来告诉服务器,我还活着。
2. 心跳机制是?
心跳机制是每隔一段时间会向服务器发送一个数据包,告诉服务器自己还活着,同时客户端会确认服务器端是否还活着,如果还活着的话,就会回传一个数据包给客户端来确定服务器端也还活着,否则的话,有可能是网络断开连接了。需要重连~
内存隔离
进程隔离是为保护操作系统中进程互不干扰而设计的一组不同硬件和软件的技术。这个技术是为了避免进程A写入进程B的情况发生。 进程的隔离实现,使用了虚拟地址空间。进程A的虚拟地址和进程B的虚拟地址不同,这样就防止进程A将数据信息写入进程B。
进程隔离的安全性通过禁止进程间内存的访问可以方便实现。相比之下,一些不安全的操作系统(例如DOS[2])能够允许任何进程对其他进程的内存进行写操作。
- 进程隔离的硬件要求
进程隔离对硬件有一些基本的要求,其中最主要的硬件是MMU (Memory Management Unit 内存管理单元),有时候ARM Cortex M之上的MPU也能达到类似的功能,但是其功能很弱,无法做到地之间的翻译,而只能在物理内存地址之上划定线性的范围。
下面重点介绍一下MMU的功能, 对于X86处理器来说其32位兼容模式运行还会有分段式内存访问的模式(其也可以达到隔离内存和翻译的作用),本文不会介绍,本文主要介绍内存分页访问的相关内容。
MMU的作用简单用一句话概括就是将线性地址翻译为物理地址, 对于理解操作系统内核来说我们并不需要了解太多MMU的细节,但是如果我们要实现一个内核,这部分知识是根据处理器体系结构的不同而不同的。
- 为什么需要线性地址(虚拟地址) 到 物理地址的翻译
我们先看如果没有线性地址的概念只有物理地址会出现的问题:
a. 整个操作系统能够访问的地址空间和实际插入的物理内存大小相关。
b. 每个进程能够访问的地址空间是从物理内存空间上的一部分。
c. 编译生成的程序需要事先知道运行在物理地址空间的范围,才能够生成相应的执行代码。
而对于上面的三个问题是一般的操作系统都无法忍受的,对于通用的操作系统来说,其能访问的内存空间是根据地址线的范围来决定的,例如32位系统就是2^32, 而对于64位操作系统是2^48 不会因为实际插入的物理内存大小的变化而变化, 而同样的为操作系统编译生成的可执行程序需要具有通用性,而不能针对不同的硬件都重新生成可执行程序来适配不同的物理内存大小和范围。
引入了线性地址到物理地址的翻译就能够解决以上的问题, 例如对于32位处理器上运行的Linux操作系统,其每个进程的内存空间都如下图所示
从上图我们可以看到对于其上运行的每一个进程,它的内存线性地址空间地址都是从0 — > 4GB的范围,其中Linux内核的地址空间为 3—>4GB的线性地址高位空间(同一个内核的地址空间映射在每个进程的3—>4GB的内存范围内), 而对于0 — > 3GB来说为每个进程自己的用户态地址空间范围。 所以每个不同的应用程序在运行时其进程的0 — > 3GB为它们的可访问地址范围,虽然它们的代码逻辑完全不同,但是内存的可访问范围却完全相同。
- 分页内存访问的操作系统如何做到进程的线性地址空间隔离
操作系统内核上电之后会初始化MMU并将自己映射到3— > 4GB的线性地址空间, 而当我们通过系统调用如fork创建进程时,其会在进程描述结构体内集成内存虚拟地址空间的结构体,其内容包含的是当前进程的地址空间页表,当操作系统进行任务切换时会改写CPU的页表基地址寄存器为当前被运行进程的页表基地址,从而达成切换地址空间范围到相应的进程内存范围的目的。
- 地址翻译的过程
MMU将一个线性地址翻译为一个物理地址的过程如下图所示
对于32位处理器,其按照10, 10, 12的规则,头10位线性地址对应页目录的index, 通过此10位的值在页目录中查询到一个页表项的地址,然后再根据中间10位定位实际对应的页的物理地址, 最后根据最后12位4KB的偏移范围在一个物理页中寻址出实际需要访问的内存位置。
所以一个线性地址分为3部分,头10位是页目录中的索引值,中间10位是页表中的索引值,最后12位是页内便宜地址。
而不同的线性地址可以映射到相同的物理地址,此处可以极大的节省实际的内存开销,例如同一个共享库如glibc.so其实例在物理内存中只存在一份,而被不同的进程映射到了自己的线性地址空间中,它们共享的访问glibc的代码段,而其数据段则每个进程有不同的glibc数据段副本。
线程启动的方式
一、继承Thread类创建线程类
(1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
(2)创建Thread子类的实例,即创建了线程对象。
(3)调用线程对象的start()方法来启动该线程。
二、通过Runnable接口创建线程类
(1)定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
(2)创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
(3)调用线程对象的start()方法来启动该线程。
三、通过Callable和Future创建线程
(1)创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
(2)创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
(3)使用FutureTask对象作为Thread对象的target创建并启动新线程。
(4)调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
1 | package com.thread; |
创建线程的三种方式的对比
采用实现Runnable、Callable接口的方式创见多线程时,优势是:
线程类只是实现了Runnable接口或Callable接口,还可以继承其他类。
在这种方式下,多个线程可以共享同一个target对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
劣势是:
编程稍微复杂,如果要访问当前线程,则必须使用Thread.currentThread()方法。
使用继承Thread类的方式创建多线程时优势是:
编写简单,如果需要访问当前线程,则无需使用Thread.currentThread()方法,直接使用this即可获得当前线程。
劣势是:
线程类已经继承了Thread类,所以不能再继承其他父类。
线程中start和run的区别
start() :
它的作用是启动一个新线程。
通过start()方法来启动的新线程,处于就绪(可运行)状态,并没有运行,一旦得到cpu时间片,就开始执行相应线程的run()方法,这里方法run()称为线程体,它包含了要执行的这个线程的内容,run方法运行结束,此线程随即终止。start()不能被重复调用。用start方法来启动线程,真正实现了多线程运行,即无需等待某个线程的run方法体代码执行完毕就直接继续执行下面的代码。这里无需等待run方法执行完毕,即可继续执行下面的代码,即进行了线程切换。
run() :
run()就和普通的成员方法一样,可以被重复调用。
如果直接调用run方法,并不会启动新线程!程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码,这样就没有达到多线程的目的。
总结:调用start方法方可启动线程,而run方法只是thread的一个普通方法调用,还是在主线程里执行。
1 | public class Test { |
总结一下:
- start() 可以启动一个新线程,run()不能
- start()不能被重复调用,run()可以
- start()中的run代码可以不执行完就继续执行下面的代码,即进行了线程切换。直接调用run方法必须等待其代码全部执行完才能继续执行下面的代码。
- start() 实现了多线程,run()没有实现多线程。
SpannableStringBuilder
This is the class for text whose content and markup can both be changed.
(这是一个内容和标记都可以更改的文本类)
不同于我们平时赋值使用的String、StringBuffer等,只能给TextView设置文本内容,而文本的样式只能用TextView来控制,而且该样式的可定制性还不大好。
SpannableStringBuilder有个亲兄弟——SpannableString。是不是觉得有点熟悉?似乎看到了StringBuilder、String的影子…
是的,SpannableStringBuilder和SpannableString的区别类似与StringBuilder、String,就是SpannableStringBuilder可以拼接,而SpannableString不可拼接。
主要的方法
SpannableStringBuilder和SpannableString主要通过使用setSpan(Object what, int start, int end, int flags)改变文本样式。
对应的参数:
- start: 指定Span的开始位置
- end: 指定Span的结束位置,并不包括这个位置。
- flags:取值有如下四个
Spannable. SPAN_INCLUSIVE_EXCLUSIVE:前面包括,后面不包括,即在文本前插入新的文本会应用该样式,而在文本后插入新文本不会应用该样式Spannable. SPAN_INCLUSIVE_INCLUSIVE:前面包括,后面包括,即在文本前插入新的文本会应用该样式,而在文本后插入新文本也会应用该样式Spannable. SPAN_EXCLUSIVE_EXCLUSIVE:前面不包括,后面不包括Spannable. SPAN_EXCLUSIVE_INCLUSIVE:前面不包括,后面包括- what: 对应的各种Span,不同的Span对应不同的样式。已知的可用类有:
BackgroundColorSpan: 文本背景色ForegroundColorSpan: 文本颜色MaskFilterSpan: 修饰效果,如模糊(BlurMaskFilter)浮雕RasterizerSpan: 光栅效果StrikethroughSpan: 删除线SuggestionSpan: 相当于占位符UnderlineSpan: 下划线AbsoluteSizeSpan: 文本字体(绝对大小)DynamicDrawableSpan: 设置图片,基于文本基线或底部对齐。ImageSpan: 图片RelativeSizeSpan: 相对大小(文本字体)ScaleXSpan: 基于x轴缩放StyleSpan: 字体样式:粗体、斜体等SubscriptSpan: 下标(数学公式会用到)SuperscriptSpan: 上标(数学公式会用到)TextAppearanceSpan: 文本外貌(包括字体、大小、样式和颜色)TypefaceSpan: 文本字体URLSpan: 文本超链接ClickableSpan: 点击事件
参考简书
CompletableFuture
1 | public class Main { |
ForkJoin
Java 7开始引入了一种新的Fork/Join线程池,它可以执行一种特殊的任务:把一个大任务拆成多个小任务并行执行。
我们举个例子:如果要计算一个超大数组的和,最简单的做法是用一个循环在一个线程内完成:
1 | ┌─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┐ |
还有一种方法,可以把数组拆成两部分,分别计算,最后加起来就是最终结果,这样可以用两个线程并行执行:
1 | ┌─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┐ |
如果拆成两部分还是很大,我们还可以继续拆,用4个线程并行执行:
1 | ┌─┬─┬─┬─┬─┬─┐ |
这就是Fork/Join任务的原理:判断一个任务是否足够小,如果是,直接计算,否则,就分拆成几个小任务分别计算。这个过程可以反复“裂变”成一系列小任务。
1 | public class Main { |
下图展示了以上代码的工作过程概要,但实际上Fork/Join框架的内部工作过程要比这张图复杂得多,例如如何决定某一个recursive task是使用哪条线程进行运行;再例如如何决定当一个任务/子任务提交到Fork/Join框架内部后,是创建一个新的线程去运行还是让它进行队列等待。
所以如果不深入理解Fork/Join框架的运行原理,只是根据之上最简单的使用例子观察运行效果,那么我们只能知道子任务在Fork/Join框架中被拆分得足够小后,并且其内部使用多线程并行完成这些小任务的计算后再进行结果向上的合并动作,最终形成顶层结果。不急,一步一步来,我们先从这张概要的过程图开始讨论。
图中最顶层的任务使用submit方式被提交到Fork/Join框架中,后者将前者放入到某个线程中运行,工作任务中的compute方法的代码开始对这个任务T1进行分析。如果当前任务需要累加的数字范围过大(代码中设定的是大于200),则将这个计算任务拆分成两个子任务(T1.1和T1.2),每个子任务各自负责计算一半的数据累加,请参见代码中的fork方法。如果当前子任务中需要累加的数字范围足够小(小于等于200),就进行累加然后返回到上层任务中。
ForkJoinPool有四个构造函数,其中参数最全的那个构造函数如下所示:
1 | public ForkJoinPool(int parallelism, |
- parallelism:可并行级别,Fork/Join框架将依据这个并行级别的设定,决定框架内并行执行的线程数量。并行的每一个任务都会有一个线程进行处理,但是千万不要将这个属性理解成Fork/Join框架中最多存在的线程数量,也不要将这个属性和ThreadPoolExecutor线程池中的corePoolSize、maximumPoolSize属性进行比较,因为ForkJoinPool的组织结构和工作方式与后者完全不一样。而后续的讨论中,读者还可以发现Fork/Join框架中可存在的线程数量和这个参数值的关系并不是绝对的关联(有依据但并不全由它决定)。
- factory:当Fork/Join框架创建一个新的线程时,同样会用到线程创建工厂。只不过这个线程工厂不再需要实现ThreadFactory接口,而是需要实现ForkJoinWorkerThreadFactory接口。后者是一个函数式接口,只需要实现一个名叫newThread的方法。在Fork/Join框架中有一个默认的ForkJoinWorkerThreadFactory接口实现:DefaultForkJoinWorkerThreadFactory。
- handler:异常捕获处理器。当执行的任务中出现异常,并从任务中被抛出时,就会被handler捕获。
- asyncMode:这个参数也非常重要,从字面意思来看是指的异步模式,它并不是说Fork/Join框架是采用同步模式还是采用异步模式工作。Fork/Join框架中为每一个独立工作的线程准备了对应的待执行任务队列,这个任务队列是使用数组进行组合的双向队列。即是说存在于队列中的待执行任务,即可以使用先进先出的工作模式,也可以使用后进先出的工作模式。
当asyncMode设置为ture的时候,队列采用先进先出方式工作;反之则是采用后进先出的方式工作,该值默认为false
ForkJoinPool还有另外两个构造函数,一个构造函数只带有parallelism参数,既是可以设定Fork/Join框架的最大并行任务数量;另一个构造函数则不带有任何参数,对于最大并行任务数量也只是一个默认值——当前操作系统可以使用的CPU内核数量(Runtime.getRuntime().availableProcessors())。实际上ForkJoinPool还有一个私有的、原生构造函数,之上提到的三个构造函数都是对这个私有的、原生构造函数的调用。
1 | ...... |
如果你对Fork/Join框架没有特定的执行要求,可以直接使用不带有任何参数的构造函数。也就是说推荐基于当前操作系统可以使用的CPU内核数作为Fork/Join框架内最大并行任务数量,这样可以保证CPU在处理并行任务时,尽量少发生任务线程间的运行状态切换(实际上单个CPU内核上的线程间状态切换基本上无法避免,因为操作系统同时运行多个线程和多个进程)。
Fork/Join框架中提供的fork方法和join方法,可以说是该框架中提供的最重要的两个方法,它们和parallelism“可并行任务数量”配合工作,可以导致拆分的子任务T1.1、T1.2甚至TX在Fork/Join框架中不同的运行效果。例如TX子任务或等待其它已存在的线程运行关联的子任务,或在运行TX的线程中“递归”执行其它任务,又或者启动一个新的线程运行子任务……
fork方法用于将新创建的子任务放入当前线程的work queue队列中,Fork/Join框架将根据当前正在并发执行ForkJoinTask任务的ForkJoinWorkerThread线程状态,决定是让这个任务在队列中等待,还是创建一个新的ForkJoinWorkerThread线程运行它,又或者是唤起其它正在等待任务的ForkJoinWorkerThread线程运行它。
这里面有几个元素概念需要注意,ForkJoinTask任务是一种能在Fork/Join框架中运行的特定任务,也只有这种类型的任务可以在Fork/Join框架中被拆分运行和合并运行。ForkJoinWorkerThread线程是一种在Fork/Join框架中运行的特性线程,它除了具有普通线程的特性外,最主要的特点是每一个ForkJoinWorkerThread线程都具有一个独立的任务等待队列(work queue),这个任务队列用于存储在本线程中被拆分的若干子任务。
join方法用于让当前线程阻塞,直到对应的子任务完成运行并返回执行结果。或者,如果这个子任务存在于当前线程的任务等待队列(work queue)中,则取出这个子任务进行“递归”执行。其目的是尽快得到当前子任务的运行结果,然后继续执行。
1 | package com.Leetcode.coding; |
ArrayMap和SparseArray
https://blog.csdn.net/qq_37704124/article/details/89715604
- ArrayMap
- ArraySet
- SparseArray
- SparseIntArray
- SparseBooleanArray
- SparseLongArray
SparseArray
SparseArray比HashMap更省内存,在某些条件下性能更好,主要是因为它避免了对key的自动装箱(int转为Integer类型),它内部则是通过两个数组来进行数据存储的,一个存储key,另外一个存储value,为了优化性能,它内部对数据还采取了压缩的方式来表示稀疏数组的数据,从而节约内存空间,我们从源码中可以看到key和value分别是用数组表示:
1 | private int[] mKeys; |
我们可以看到,SparseArray只能存储key为int类型的数据,同时,SparseArray在存储和读取数据时候,使用的是二分查找法,我们可以看看:
1 | public void put(int key, E value) { |
也就是在put添加数据的时候,会使用二分查找法和之前的key比较当前我们添加的元素的key的大小,然后按照从小到大的顺序排列好,所以,SparseArray存储的元素都是按元素的key值从小到大排列好的。
而在获取数据的时候,也是使用二分查找法判断元素的位置,所以,在获取数据的时候非常快,比HashMap快的多,因为HashMap获取数据是通过遍历Entry[]数组来得到对应的元素。
在此之外,SparseArray还提供了两个特有方法,更方便数据的查询:
获取对应的key:
1 | public int keyAt(int index) |
获取对应的value:
1 | public E valueAt(int index) |
虽说SparseArray性能比较好,但是由于其添加、查找、删除数据都需要先进行一次二分查找,所以在数据量大的情况下性能并不明显,将降低至少50%。
满足下面两个条件我们可以使用SparseArray代替HashMap:
- 数据量不大,最好在千级以内
- key必须为int类型,这中情况下的HashMap可以用SparseArray代替:
ArrayMap
ArrayMap是一个<key,value>映射的数据结构,它设计上更多的是考虑内存的优化,内部是使用两个数组进行数据存储,一个数组记录key的hash值,另外一个数组记录Value值,它和SparseArray一样,也会对key使用二分法进行从小到大排序,在添加、删除、查找数据的时候都是先使用二分查找法得到相应的index,然后通过index来进行添加、查找、删除等操作,所以,应用场景和SparseArray的一样,如果在数据量比较大的情况下,那么它的性能将退化至少50%。
1 | public final class ArrayMap<K, V> implements Map<K, V> { |
ArrayMap对象的数据储存格式如图所示:
- mHashes是一个记录所有key的hashcode值组成的数组,是从小到大的排序方式;
- mArray是一个记录着key-value键值对所组成的数组,是mHashes大小的2倍;
其中mSize记录着该ArrayMap对象中有多少对数据,执行put()或者append()操作,则mSize会加1,执行remove(),则mSize会减1。mSize往往小于mHashes.length,如果mSize大于或等于mHashes.length,则说明mHashes和mArray需要扩容。
ArrayMap类有两个非常重要的静态成员变量mBaseCache和mTwiceBaseCacheSize,用于ArrayMap所在进程的全局缓存功能:
- mBaseCache:用于缓存大小为4的ArrayMap,mBaseCacheSize记录着当前已缓存的数量,超过10个则不再缓存;
- mTwiceBaseCacheSize:用于缓存大小为8的ArrayMap,mTwiceBaseCacheSize记录着当前已缓存的数量,超过10个则不再缓存。
为了减少频繁地创建和回收Map对象,ArrayMap采用了两个大小为10的缓存队列来分别保存大小为4和8的Map对象。为了节省内存有更加保守的内存扩张以及内存收缩策略。 接下来分别说说缓存机制和扩容机制。
参考Gityuan
api与implementation的区别
implementation可以让module在编译时隐藏自己使用的依赖,但是在运行时这个依赖对所有模块是可见的。而api与compile一样,无法隐藏自己使用的依赖。
在多module中,implementation确实可以起到隐藏依赖的作用,网上很多的文章都只讲到了这点,那么这样做的目的是什么呢?其实这并不是Google设计implemention与api的目的,因为官方文档中说这样计的目的在于减少build的时间,那么implemention是如何减少build time的呢?
如果app本地implementation mylibrary1,mylibrary1远程implemention mylibrary2,这时候app则不能获取到mylibrary2中的myClass2类,依然起到了依赖隔离的作用。
由以上可以看到在全部远程依赖模式下,无论是api还是implemention都起不到依赖隔离的作用。不过,在远程依赖模式下,依赖的一个模块如果版本发生变化,implemention与api的构建速度谁快谁慢还需要进一步研究。
综上,在多层次模块化(大于等于三层module)开发时,如果都是本地依赖,implementation相比api,主要优势在于减少build time。如果只有两层module,api与implemention在build time上并无太大的差别。
怎么保证service不被杀死/进程保活?
(1)Service设置成START_STICKY(onStartCommand方法中),kill 后会被重启(等待5秒左右),重传Intent,保持与重启前一样
(2)通过 startForeground将进程设置为前台进程,做前台服务,优先级和前台应用一个级别,除非在系统内存非常缺,否则此进程不会被 kill.具体实现方式为在service中创建一个notification,再调用void android.app.Service.startForeground(int id,Notificationnotification)方法运行在前台即可。
(3)双进程Service:让2个进程互相保护,其中一个Service被清理后,另外没被清理的进程可以立即重启进程。
(4)AlarmManager不断启动service。该方式原理是通过定时警报来不断启动service,这样就算service被杀死,也能再启动。同时也可以监听网络切换、开锁屏等广播来启动service。
Binder
https://blog.csdn.net/carson_ho/article/details/73560642
启动优化
https://juejin.im/post/6844903958113157128
https://juejin.im/post/6867744083809419277#heading-7
GIT底层数据结构
https://www.cnblogs.com/cczlovexw/p/12964086.html
断点续传
断点续传其实正如字面意思,就是在下载的断开点继续开始传输,不用再从头开始。所以理解断点续传的核心后,发现其实和很简单,关键就在于对传输中断点的把握,我就自己的理解画了一个简单的示意图:
JAVA异常
Java 在代码中通过使用 try{}catch(){}finally{} 块来对异常进行捕获或者处理。但是对于 JVM 来说,是如何处理 try/catch 代码块与异常的呢。
实际上 Java 编译后,会在代码后附加异常表的形式来实现 Java 的异常处理及 finally 机制(在 JDK1.4.2之前,javac 编译器使用 jsr 和 ret 指令来实现 finally 语句,但是1.4.2之后自动在每段可能的分支路径后将 finally 语句块内容冗余生成一遍来实现。JDK1.7及之后版本,则完全禁止在 Class 文件中使用 jsr 和 ret 指令)。
异常表
属性表(attribute_info)可以存在于 Class 文件、字段表、方法表中,用于描述某些场景的专有信息。属性表中有个 Code 属性,该属性在方法表中使用,Java 程序方法体中的代码被编译成的字节码指令存储在 Code 属性中。而异常表(exception_table)则是存储在 Code 属性表中的一个结构,这个结构是可选的。
异常表结构
异常表结构如下表所示。它包含四个字段:如果当字节码在第 start_pc 行到 end_pc 行之间(即[start_pc, end_pc))出现了类型为 catch_type 或者其子类的异常(catch_type 为指向一个 CONSTANT_Class_info 型常量的索引),则跳转到第 handler_pc 行执行。如果 catch_type 为0,表示任意异常情况都需要转到 handler_pc 处进行处理。
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | start_pc | 1 |
| u2 | end_pc | 1 |
| u2 | handler_pc | 1 |
| u2 | catch_type | 1 |
处理异常机制
如上面所说,每个类编译后,都会跟随一个异常表,如果发生异常,首先在异常表中查找对应的行(即代码中相应的 try{}catch(){} 代码块),如果找到,则跳转到异常处理代码执行,如果没有找到,则返回(执行 finally 之后),并 copy 异常的应用给父调用者,接着查询父调用的异常表,以此类推。
异常处理实例
对于 Java 源码:
1 | public int inc() { |
将其编译为 ByteCode 字节码:
1 | public int inc(); |
首先可以看到,对于 finally,编译器将每个可能出现的分支后都放置了冗余。并且编译器生成了三个异常表记录,从 Java 代码的语义上讲,执行路径分别为:
- 如果 try 语句块中出现了属于 Exception 及其子类的异常,则跳转到 catch 处理;
- 如果 try 语句块中出现了不属于 Exception 及其子类的异常,则跳转到 finally 处理;
- 如果 catch 语句块中出现了任何异常,则跳转到 finally 处理。
由此可以分析此段代码可能的返回结果:
- 如果没有出现异常,返回1;
- 如果出现 Exception 异常,返回2;
- 如果出现了 Exception 意外的异常,非正常退出,没有返回;
我们来分析字节码:
首先,0-4行,就是把整数1赋值给 x,并且将此时 x 的值复制一个副本到本地变量表的 Slot 中(即 returnValue),这个 Slot 里面的值在 ireturn 指令执行前会被重新读到栈顶,作为返回值。这是如果没有异常,则执行5-9行,把 x 赋值为3,然后返回 returnValue 中保存的1,方法结束。如果出现异常,读取异常表发现应该执行第10行,pc 寄存器指针转向10行,10-20行就是把2赋值给 x,然后把 x 赋值给 returnValue,再将 x 赋值为3,然后将 returnValue 中的2读到操作栈顶返回。第21行开始是把 x 赋值为3并且将栈顶的异常抛出,方法结束。
单测
相册图片加载
https://blog.csdn.net/hanhailong726188/article/details/51923265
安卓的activity和application有什么区别
生命周期跟UI相关的,使用Activity的Context处理,如:对话框,各种View,需要startActivity的等。
生命周期跟UI无关的,使用Application的Context,如:AsyncTask,Thread,第三方库初始化等等。
在Activity中,Activity.this和getApplicationContext()返回的不是同一个对象,一个是当前Activity的实例,一个是项目的Application的实例,这两者的生命周期是不同的,它们各自的使用场景不同,getApplicationContext() 生命周期是整个应用,当应用程序摧毁的时候,它才会摧毁;Activity.this的context是属于当前Activity的,当前Activity摧毁的时候,它就摧毁。
相同:
Activity 和 Application 都是 Context 的子类
Context 从字面上理解就是上下文的意思, 在实际应用中它也确实是起到了管理上下文环境中各个参数和变量的作用, 方便我们可以简单的访问到各种资源.
不同:
维护的生命周期不同.
- Activity 维护的是当前的 Activity 的生命周期. 所以其对应的Context也只能访问该 Activity 内的各种资源
- Application 维护的是整个项目的生命周期.
使用 context 的时候, 小心内存泄露, 防止内存泄露, 注意一下几个方面:
- 不要让生命周期长的对象引用 activity context, 即保证引用 activity 的对象要与 activity 本身生命周期是一样的.
- 对于生命周期长的对象,可以使用 application context。
- 避免非静态的内部类, 尽量使用静态类, 避免生命周期问题, 注意内部类对外部对象引用导致的生命周期变化.
https://blog.csdn.net/LVXIANGAN/article/details/83345061
android fragment和activity的区别
https://blog.csdn.net/u012974916/article/details/24563371
布局优化
https://juejin.im/post/6844903657310257159
Android SharedPreferences 实现原理分析
https://www.jianshu.com/p/f7289e801a7f
https://www.jianshu.com/p/ff8c256df6d2
为什么 Android 要采用 Binder 作为 IPC 机制?
在开始回答 前,先简单概括性地说说Linux现有的所有进程间IPC方式:
\1. 管道:在创建时分配一个page大小的内存,缓存区大小比较有限;
\2. 消息队列:信息复制两次,额外的CPU消耗;不合适频繁或信息量大的通信;
\3. 共享内存:无须复制,共享缓冲区直接付附加到进程虚拟地址空间,速度快;但进程间的同步问题操作系统无法实现,必须各进程利用同步工具解决;
\4. 套接字:作为更通用的接口,传输效率低,主要用于不通机器或跨网络的通信;
\5. 信号量:常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
\6. 信号: 不适用于信息交换,更适用于进程中断控制,比如非法内存访问,杀死某个进程等;
Android的内核也是基于Linux内核,为何不直接采用Linux现有的进程IPC方案呢,难道Linux社区那么多优秀人员都没有考虑到有Binder这样一个更优秀的方案,是google太过于牛B吗?事实是真相并非如此,请细细往下看,您就明白了。
原文作者:Gityuan
链接:https://www.zhihu.com/question/39440766/answer/89210950
接下来正面回答这个问题,从5个角度来展开对Binder的分析:
(1)从性能的角度 数据拷贝次数:Binder数据拷贝只需要一次,而管道、消息队列、Socket都需要2次,但共享内存方式一次内存拷贝都不需要;从性能角度看,Binder性能仅次于共享内存。
(2)从稳定性的角度
Binder是基于C/S架构的,简单解释下C/S架构,是指客户端(Client)和服务端(Server)组成的架构,Client端有什么需求,直接发送给Server端去完成,架构清晰明朗,Server端与Client端相对独立,稳定性较好;而共享内存实现方式复杂,没有客户与服务端之别, 需要充分考虑到访问临界资源的并发同步问题,否则可能会出现死锁等问题;从这稳定性角度看,Binder架构优越于共享内存。
仅仅从以上两点,各有优劣,还不足以支撑google去采用binder的IPC机制,那么更重要的原因是:
(3)从安全的角度
传统Linux IPC的接收方无法获得对方进程可靠的UID/PID,从而无法鉴别对方身份;而Android作为一个开放的开源体系,拥有非常多的开发平台,App来源甚广,因此手机的安全显得额外重要;对于普通用户,绝不希望从App商店下载偷窥隐射数据、后台造成手机耗电等等问题,传统Linux IPC无任何保护措施,完全由上层协议来确保。
Android为每个安装好的应用程序分配了自己的UID,故进程的UID是鉴别进程身份的重要标志,前面提到C/S架构,Android系统中对外只暴露Client端,Client端将任务发送给Server端,Server端会根据权限控制策略,判断UID/PID是否满足访问权限,目前权限控制很多时候是通过弹出权限询问对话框,让用户选择是否运行。Android 6.0,也称为Android M,在6.0之前的系统是在App第一次安装时,会将整个App所涉及的所有权限一次询问,只要留意看会发现很多App根本用不上通信录和短信,但在这一次性权限权限时会包含进去,让用户拒绝不得,因为拒绝后App无法正常使用,而一旦授权后,应用便可以胡作非为。
针对这个问题,google在Android M做了调整,不再是安装时一并询问所有权限,而是在App运行过程中,需要哪个权限再弹框询问用户是否给相应的权限,对权限做了更细地控制,让用户有了更多的可控性,但同时也带来了另一个用户诟病的地方,那也就是权限询问的弹框的次数大幅度增多。对于Android M平台上,有些App开发者可能会写出让手机异常频繁弹框的App,企图直到用户授权为止,这对用户来说是不能忍的,用户最后吐槽的可不光是App,还有Android系统以及手机厂商,有些用户可能就跳果粉了,这还需要广大Android开发者以及手机厂商共同努力,共同打造安全与体验俱佳的Android手机。
Android中权限控制策略有SELinux等多方面手段,下面列举从Binder的一个角度的权限控制:
Android源码的Binder权限是如何控制? -Gityuan的回答
传统IPC只能由用户在数据包里填入UID/PID;另外,可靠的身份标记只有由IPC机制本身在内核中添加。其次传统IPC访问接入点是开放的,无法建立私有通道。从安全角度,Binder的安全性更高。
说到这,可能有人要反驳,Android就算用了Binder架构,而现如今Android手机的各种流氓软件,不就是干着这种偷窥隐射,后台偷偷跑流量的事吗?没错,确实存在,但这不能说Binder的安全性不好,因为Android系统仍然是掌握主控权,可以控制这类App的流氓行为,只是对于该采用何种策略来控制,在这方面android的确存在很多有待进步的空间,这也是google以及各大手机厂商一直努力改善的地方之一。在Android 6.0,google对于app的权限问题作为较多的努力,大大收紧的应用权限;另外,在Google举办的Android Bootcamp 2016大会中,google也表示在Android 7.0 (也叫Android N)的权限隐私方面会进一步加强加固,比如SELinux,Memory safe language(还在research中)等等,在今年的5月18日至5月20日,google将推出Android N。
话题扯远了,继续说Binder。
(4)从语言层面的角度
大家多知道Linux是基于C语言(面向过程的语言),而Android是基于Java语言(面向对象的语句),而对于Binder恰恰也符合面向对象的思想,将进程间通信转化为通过对某个Binder对象的引用调用该对象的方法,而其独特之处在于Binder对象是一个可以跨进程引用的对象,它的实体位于一个进程中,而它的引用却遍布于系统的各个进程之中。可以从一个进程传给其它进程,让大家都能访问同一Server,就像将一个对象或引用赋值给另一个引用一样。Binder模糊了进程边界,淡化了进程间通信过程,整个系统仿佛运行于同一个面向对象的程序之中。从语言层面,Binder更适合基于面向对象语言的Android系统,对于Linux系统可能会有点“水土不服”。
另外,Binder是为Android这类系统而生,而并非Linux社区没有想到Binder IPC机制的存在,对于Linux社区的广大开发人员,我还是表示深深佩服,让世界有了如此精湛而美妙的开源系统。也并非Linux现有的IPC机制不够好,相反地,经过这么多优秀工程师的不断打磨,依然非常优秀,每种Linux的IPC机制都有存在的价值,同时在Android系统中也依然采用了大量Linux现有的IPC机制,根据每类IPC的原理特性,因时制宜,不同场景特性往往会采用其下最适宜的。比如在Android OS中的Zygote进程的IPC采用的是Socket(套接字)机制,Android中的Kill Process采用的signal(信号)机制等等。而Binder更多则用在system_server进程与上层App层的IPC交互。
(5) 从公司战略的角度
总所周知,Linux内核是开源的系统,所开放源代码许可协议GPL保护,该协议具有“病毒式感染”的能力,怎么理解这句话呢?受GPL保护的Linux Kernel是运行在内核空间,对于上层的任何类库、服务、应用等运行在用户空间,一旦进行SysCall(系统调用),调用到底层Kernel,那么也必须遵循GPL协议。
而Android 之父 Andy Rubin对于GPL显然是不能接受的,为此,Google巧妙地将GPL协议控制在内核空间,将用户空间的协议采用Apache-2.0协议(允许基于Android的开发商不向社区反馈源码),同时在GPL协议与Apache-2.0之间的Lib库中采用BSD证授权方法,有效隔断了GPL的传染性,仍有较大争议,但至少目前缓解Android,让GPL止步于内核空间,这是Google在GPL Linux下 开源与商业化共存的一个成功典范。
有了这些铺垫,我们再说说Binder的今世前缘
Binder是基于开源的 OpenBinder实现的,OpenBinder是一个开源的系统IPC机制,最初是由 Be Inc. 开发,接着由Palm, Inc.公司负责开发,现在OpenBinder的作者在Google工作,既然作者在Google公司,在用户空间采用Binder 作为核心的IPC机制,再用Apache-2.0协议保护,自然而然是没什么问题,减少法律风险,以及对开发成本也大有裨益的,那么从公司战略角度,Binder也是不错的选择。
另外,再说一点关于OpenBinder,在2015年OpenBinder以及合入到Linux Kernel主线 3.19版本,这也算是Google对Linux的一点回馈吧。
综合上述5点,可知Binder是Android系统上层进程间通信的不二选择。
接着,回答楼主提到的D-Bus
也采用C/S架构的IPC机制,D-Bus是在用户空间实现的方法,效率低,消息拷贝次数和上下文切换次数都明显多过于Binder。针对D-Bus这些缺陷,于是就产生了kdbus,这是D-Bus在内核实现版,效率得到提升,与Binder一样在内核作为字符设计,通过open()打开设备,mmap()映射内存。
(1)kdbus在进程间通信过程,Client端将消息在内存的消息队列,可以存储大量的消息,Server端不断从消息队里中取消息,大小只受限内存;
(2)Binder的机制是每次通信,会通信的进程或线程中的todo队里中增加binder事务,并且每个进程所允许Binder线程数,google提供的默认最大线程数为16个,受限于CPU,由于线程数太多,增加系统负载,并且每个进程默认分配的(1M-8K)大小的内存。
而kdbus对于内存消耗较大,同时也适合传输大量数据和大量消息的系统。Binder对CPU和内存的需求比较低,效率比较高,从而进一步说明Binder适合于移动系统Android,但是,也有一定缺点,就是不同利用Binder输出大数据,比如利用Binder传输几M大小的图片,便会出现异常,虽然有厂商会增加Binder内存,但是也不可能比系统默认内存大很多,否则整个系统的可用内存大幅度降低。
最后,简单讲讲Android Binder架构
Binder在Android系统中江湖地位非常之高。在Zygote孵化出system_server进程后,在system_server进程中出初始化支持整个Android framework的各种各样的Service,而这些Service从大的方向来划分,分为Java层Framework和Native Framework层(C++)的Service,几乎都是基于BInder IPC机制。
- Java framework:作为Server端继承(或间接继承)于Binder类,Client端继承(或间接继承)于BinderProxy类。例如 ActivityManagerService(用于控制Activity、Service、进程等) 这个服务作为Server端,间接继承Binder类,而相应的ActivityManager作为Client端,间接继承于BinderProxy类。 当然还有PackageManagerService、WindowManagerService等等很多系统服务都是采用C/S架构;
- Native Framework层:这是C++层,作为Server端继承(或间接继承)于BBinder类,Client端继承(或间接继承)于BpBinder。例如MediaPlayService(用于多媒体相关)作为Server端,继承于BBinder类,而相应的MediaPlay作为Client端,间接继承于BpBinder类。
总之,一句话”无Binder不Android”。
滑动冲突
https://www.jianshu.com/p/982a83271327
Okhttp原理
https://juejin.im/post/6844903903033557005
冷启动,热启动
https://www.jianshu.com/p/eb3b410cce49
https://blog.csdn.net/fafaws3000/article/details/103928571
ART虚拟机
https://source.android.com/devices/tech/dalvik
Android Runtime (ART) 是 Android 上的应用和部分系统服务使用的托管式运行时。ART 及其前身 Dalvik 最初是专为 Android 项目打造的。作为运行时的 ART 可执行 Dalvik 可执行文件并遵循 Dex 字节码规范。
ART 和 Dalvik 是运行 Dex 字节码的兼容运行时,因此针对 Dalvik 开发的应用也能在 ART 环境中运作。不过,Dalvik 采用的一些技术并不适用于 ART。有关最重要问题的信息,请参阅在 Android Runtime (ART) 上验证应用行为。
ART 功能
以下是 ART 实现的一些主要功能。
预先 (AOT) 编译
ART 引入了预先编译机制,可提高应用的性能。ART 还具有比 Dalvik 更严格的安装时验证。
在安装时,ART 使用设备自带的 dex2oat 工具来编译应用。此实用工具接受 DEX 文件作为输入,并为目标设备生成经过编译的应用可执行文件。该工具应能够顺利编译所有有效的 DEX 文件。但是,一些后处理工具会生成无效文件,Dalvik 可以接受这些文件,但 ART 无法编译这些文件。如需了解详情,请参阅处理垃圾回收问题。
垃圾回收方面的优化
垃圾回收 (GC) 可能有损于应用性能,从而导致显示不稳定、界面响应速度缓慢以及其他问题。ART 通过以下几种方式对垃圾回收做了优化:
- 只有一次(而非两次)GC 暂停
- 在 GC 保持暂停状态期间并行处理
- 在清理最近分配的短时对象这种特殊情况中,回收器的总 GC 时间更短
- 优化了垃圾回收的工效,能够更加及时地进行并行垃圾回收,这使得
GC_FOR_ALLOC事件在典型用例中极为罕见 - 压缩 GC 以减少后台内存使用和碎片
开发和调试方面的优化
ART 提供了大量功能来优化应用开发和调试。
支持采样分析器
一直以来,开发者都使用 Traceview 工具(用于跟踪应用执行情况)作为分析器。虽然 Traceview 可提供有用的信息,但每次方法调用产生的开销会导致 Dalvik 分析结果出现偏差,而且使用该工具明显会影响运行时性能。
ART 添加了对没有这些限制的专用采样分析器的支持,因而可更准确地了解应用执行情况,而不会明显减慢速度。KitKat 版本为 Dalvik 的 Traceview 添加了采样支持。
支持更多调试功能
ART 支持许多新的调试选项,特别是与监控和垃圾回收相关的功能。例如,您可以:
- 查看堆栈跟踪中保留了哪些锁,然后跳转到持有锁的线程。
- 询问指定类的当前活动的实例数、请求查看实例,以及查看使对象保持有效状态的参考。
- 过滤特定实例的事件(如断点)。
- 查看方法退出(使用“method-exit”事件)时返回的值。
- 设置字段观察点,以在访问和/或修改特定字段时暂停程序执行。
优化了异常和崩溃报告中的诊断详细信息
当发生运行时异常时,ART 会为您提供尽可能多的上下文和详细信息。ART 会提供 java.lang.ClassCastException、java.lang.ClassNotFoundException 和 java.lang.NullPointerException 的更多异常详细信息。(较高版本的 Dalvik 会提供 java.lang.ArrayIndexOutOfBoundsException 和 java.lang.ArrayStoreException 的更多异常详细信息,这些信息现在包括数组大小和越界偏移量;ART 也提供这类信息。)
例如,java.lang.NullPointerException 现在会显示有关应用尝试处理 null 指针时所执行操作的信息,例如应用尝试写入的字段或尝试调用的方法。一些典型示例如下:
1 | java.lang.NullPointerException: Attempt to write to field 'int |
ART 还通过纳入 Java 和原生堆栈信息,在应用原生代码崩溃报告中提供更实用的上下文信息。