JAVA
堆和栈的区别
栈内存:栈内存首先是一片内存区域,存储的都是局部变量,凡是定义在方法中的都是局部变量(方法外的是全局变量),for循环内部定义的也是局部变量,是先加载函数才能进行局部变量的定义,所以方法先进栈,然后再定义变量,变量有自己的作用域,一旦离开作用域,变量就会被释放。栈内存的更新速度很快,因为局部变量的生命周期都很短。
堆内存:存储的是数组和对象(其实数组就是对象),凡是new建立的都是在堆中,堆中存放的都是实体(对象),实体用于封装数据,而且是封装多个(实体的多个属性),如果一个数据消失,这个实体也没有消失,还可以用,所以堆是不会随时释放的,但是栈不一样,栈里存放的都是单个变量,变量被释放了,那就没有了。堆里的实体虽然不会被释放,但是会被当成垃圾,Java有垃圾回收机制不定时的收取。
当一个实体,没有引用数据类型指向的时候,它在堆内存中不会被释放,而被当做一个垃圾,在不定时的时间内自动回收,因为Java有一个自动回收机制,(而c++没有,需要程序员手动回收,如果不回收就越堆越多,直到撑满内存溢出,所以Java在内存管理上优于c++)。自动回收机制(程序)自动监测堆里是否有垃圾,如果有,就会自动的做垃圾回收的动作,但是什么时候收不一定。
所以堆与栈的区别很明显:
1.栈内存存储的是局部变量而堆内存存储的是实体;
2.栈内存的更新速度要快于堆内存,因为局部变量的生命周期很短;
3.栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。
float中的32bit中哪些代表符号位,小数位,整数位,指数位?
答:float:
1bit(符号位) 8bits(指数位) 23bits(尾数位)
double:
1bit(符号位) 11bits(指数位) 52bits(尾数位)
于是,float的指数范围为-128~+127,而double的指数范围为-1024~+1023,并且指数位是按补码的形式来划分的。float的范围为-2^128 ~ +2^127,也即-3.40E+38 ~ +3.40E+38;double的范围为-2^1024 ~ +2^1023,也即-1.79E+308 ~ +1.79E+308。
多态
答:事物在运行过程中存在不同的状态。多态的存在有三个前提:
1.要有继承关系
2.子类要重写父类的方法
3.父类引用指向子类对
多态成员访问的特点:
成员变量
编译看左边(父类),运行看左边(父类)
成员方法
编译看左边(父类),运行看右边(子类)。动态绑定
静态方法
编译看左边(父类),运行看左边(父类)。
(静态和类相关,算不上重写,所以,访问还是左边的)
只有非静态的成员方法,编译看左边,运行看右边
多态的弊端,就是:不能使用子类特有的成员属性和子类特有的成员方法。
继承方式
答:子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
动态绑定
1.当子类和父类存在同一个方法,子类重写了父类的方法,程序在运行时调用的是父类的方法还是子类的重写方法呢(尤其是存在向上类型转换的情况)?
2.当一个类中存在方法名相同但参数不同(重载)的方法,程序在执行的时候该如何辨别区分使用哪个方法呢?
答:
静态绑定
在程序执行以前已经被绑定(即在编译过程中就已经知道这个方法到底是哪个类中的方法)。
java当中的方法只有final、static、private修饰的方法和构造方法是静态绑定的。
private修饰的方法:private修饰的方法是不能被继承的,因此子类无法访问父类中private修饰的方法。所以只能通过父类对象来调用该方法体。因此可以说private方法和定义这个方法的类绑定在了一起。
final修饰的方法:可以被子类继承,但是不能被子类重写(覆盖),所以在子类中调用的实际是父类中定义的final方法。(使用final修饰方法的两个好处:(1)防止方法被覆盖;(2)关闭java中的动态绑定)。
static修饰的方法:可以被子类继承,但是不能被子类重写(覆盖),但是可以被子类隐藏。(这里意思是说如果父类里有一个static方法,它的子类里如果没有对应的方法,那么当子类对象调用这个方法时就会使用父类中的方法,而如果子类中定义了相同的方法,则会调用子类中定义的方法,唯一的不同就是:当子类对象向上类型转换为父类对象时,不论子类中有没有定义这个静态方法,该对象都会使用父类中的静态方法,因此这里说静态方法可以被隐藏而不能被覆盖。这与子类隐藏父类中的成员变量是一样的。隐藏和覆盖的区别在于,子类对象转换成父类对象后,能够访问父类被隐藏的变量和方法,而不能访问父类被覆盖的方法)。
构造方法:构造方法也是不能被继承的(因为子类是通过super方法调用父类的构造函数,或者是jvm自动调用父类的默认构造方法),因此编译时也可以知道这个构造方法方法到底是属于哪个类的。
因此,一个方法被继承,或者是被继承后不能被覆盖,那么这个方法就采用静态绑定
动态绑定
在运行时期根据具体对象的类型进行绑定。
若一种语言实现了后期绑定,同时必须提供一些机制,可在运行期间判断对象的类型,并分别调用适当的方法。也就是说,编译器此时依然不知道对象的类型,但方法调用机制能自己去调查,找到正确的方法主体。不同的语言对后期绑定的实现方法是有所区别的,但我们至少可以这样认为:它们都要在对象中安插某些特殊类型的信息。
动态绑定的过程:
1.虚拟机提取对象实际类型的方法表
2.虚拟机搜索方法签名
3.调用方法
java中重载的方法使用静态绑定,重写的方法使用动态绑定。
String, stringbuffer, stringbuider区别
String 字符串常量
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用 String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。
而如果是使用 StringBuffer 类则结果就不一样了,每次结果都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用 StringBuffer ,特别是字符串对象经常改变的情况下。而在某些特别情况下, String 对象的字符串拼接其实是被 JVM 解释成了 StringBuffer 对象的拼接,所以这些时候 String 对象的速度并不会比 StringBuffer 对象慢。
StringBuffer
Java.lang.StringBuffer线程安全的可变字符序列。一个类似于 String 的字符串缓冲区,但不能修改。虽然在任意时间点上它都包含某种特定的字符序列,但通过某些方法调用可以改变该序列的长度和内容。
可将字符串缓冲区安全地用于多个线程。可以在必要时对这些方法进行同步,因此任意特定实例上的所有操作就好像是以串行顺序发生的,该顺序与所涉及的每个线程进行的方法调用顺序一致。
StringBuffer 上的主要操作是 append 和 insert 方法,可重载这些方法,以接受任意类型的数据。每个方法都能有效地将给定的数据转换成字符串,然后将该字符串的字符追加或插入到字符串缓冲区中。append 方法始终将这些字符添加到缓冲区的末端;而 insert 方法则在指定的点添加字符。
java.lang.StringBuilder
java.lang.StringBuilder一个可变的字符序列是5.0新增的。此类提供一个与 StringBuffer 兼容的 API,但不保证同步。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比 StringBuffer 要快。两者的方法基本相同。
通过反射是可以修改所谓的“不可变”对象
1 | // 创建字符串"Hello World", 并赋给引用s |
解析:
用反射可以访问私有成员, 然后反射出 String 对象中的 value 属性, 进而改变通过获得的 value 引用改变数组的结构。但是一般我们不会这么做,这里只是简单提一下有这个东西。
重写hashcode()是否需要重写equals(),不重写会有什么后果
我们先来看一下Object.hashCode的通用约定(摘自《Effective Java》第45页)
- 在一个应用程序执行期间,如果一个对象的equals方法做比较所用到的信息没有被修改的话,那么,对该对象调用hashCode方法多次,它必须始终如一地返回 同一个整数。在同一个应用程序的多次执行过程中,这个整数可以不同,即这个应用程序这次执行返回的整数与下一次执行返回的整数可以不一致。
- 如果两个对象根据equals(Object)方法是相等的,那么调用这两个对象中任一个对象的hashCode方法必须产生同样的整数结果。
- 如果两个对象根据equals(Object)方法是不相等的,那么调用这两个对象中任一个对象的hashCode方法,不要求必须产生不同的整数结果。然而,程序员应该意识到这样的事实,对于不相等的对象产生截然不同的整数结果,有可能提高散列表(hash table)的性能。
如果只重写了equals方法而没有重写hashCode方法的话,则会违反约定的第二条:相等的对象必须具有相等的散列码(hashCode)。
同时对于HashSet和HashMap这些基于散列值(hash)实现的类。HashMap的底层处理机制是以数组的方法保存放入的数据的(Node
如果我们将某个自定义对象存到HashMap或者HashSet及其类似实现类中的时候,如果该对象的属性参与了hashCode的计算,那么就不能修改该对象参数hashCode计算的属性了。有可能会移除不了元素,导致内存泄漏。
ArrayList只根据equals()来判断两个对象是否相等,而不管hashCode是否不相等。HashSet判断流程则不一样,①先判断两个对象的hashCode方法是否一样;②如果不一样,立即认为两个对象equals不相等,并不调用equals方法;③当hashCode相等时,再根据equals方法判断两个对象是否相等。
当我们所写的类可能用于存放在Hash相关的集合类中时,在重写equals时,需要重写hashCode,不然会出现与预期不符的结果。
既然有GC 机制,为什么还会有内存泄露的情况
理论上 Java 因为有垃圾回收机制(GC)不会存在内存泄露问题(这也是 Java 被广泛使用于服务器端编程的一个重要原因)。然而在实际开发中,可能会存在无用但可达的对象,这些对象不能被 GC 回收,因此也会导致内存泄露的发生。
例如 hibernate 的 Session(一级缓存)中的对象属于持久态,垃圾回收器是不会回收这些对象的,然而这些对象中可能存在无用的垃圾对象,如果不及时关闭(close)或清空(flush)一级缓存就可能导致内存泄露。
下面例子中的代码也会导致内存泄露。
1 | import java.util.Arrays; |
上面的代码实现了一个栈(先进后出(FILO))结构,乍看之下似乎没有什么明显的问题,它甚至可以通过你编写的各种单元测试。然而其中的 pop 方法却存在内存泄露的问题,当我们用 pop 方法弹出栈中的对象时,该对象不会被当作垃圾回收,即使使用栈的程序不再引用这些对象,因为栈内部维护着对这些对象的过期引用(obsoletereference)。在支持垃圾回收的语言中,内存泄露是很隐蔽的,这种内存泄露其实就是无意识的对象保持。如果一个对象引用被无意识的保留起来了,那么垃圾回收器不会处理这个对象,也不会处理该对象引用的其他对象,即使这样的对象只有少数几个,也可能会导致很多的对象被排除在垃圾回收之外,从而对性能造成重大影响,极端情况下会引发 Disk Paging (物理内存与硬盘的虚拟内存交换数据),甚至造成 OutOfMemoryError。
Java 的GC 什么时候回收垃圾
在面试中经常会碰到这样一个问题:如何判断一个对象已经死去?
很容易想到的一个答案是:对一个对象添加引用计数器。每当有地方引用它时,计数器值加1;当引用失效时,计数器值减1.而当计数器的值为0 时这个对象就不会再被使用,判断为已死。是不是简单又直观。然而,很遗憾。这种做法是错误的!为什么是错的呢?事实上,用引用计数法确实在大部分情况下是一个不错的解决方案,而在实际的应用中也有不少案例,但它却无法解决对象之间的循环引用问题。比如对象A 中有一个字段指向了对象B,而对象B 中也有一个字段指向了对象A,而事实上他们俩都不再使用,但计数器的值永远都不可能为0,也就不会被回收,然后就发生了内存泄露。
所以,正确的做法应该是怎样呢?
在Java,C#等语言中,比较主流的判定一个对象已死的方法是:可达性分析(Reachability Analysis).
所有生成的对象都是一个称为”GC Roots”的根的子树。从GC Roots 开始向下搜索,搜索所经过的路径称为引用链(Reference Chain),当一个对象到GC Roots 没有任何引用链可以到达时,就称这个对象是不可达的(不可引用的),也就是可以被GC 回收了。
无论是引用计数器还是可达性分析,判定对象是否存活都与引用有关!那么,如何定义对象的引用呢?
我们希望给出这样一类描述:当内存空间还够时,能够保存在内存中;如果进行了垃圾回收之后内存空间仍旧非常紧张,则可以抛弃这些对象。所以根据不同的需求,给出如下四种引用,根据引用类型的不同,GC 回收时也会有不同的操作:
1)强引用(Strong Reference):Object obj = new Object();只要强引用还存在,GC 永远不会回收掉被引用的对象。
2)软引用(Soft Reference):描述一些还有用但非必需的对象。在系统将会发生内存溢出之前,会把这些对象列入回收范围进行二次回收(即系统将会发生内存溢出了,才会对他们进行回收。)
弱引用(Weak Reference):程度比软引用还要弱一些。这些对象只能生存到下次GC 之前。当GC 工作时,无论内存是否足够都会将其回收(即只要进行GC,就会对他们进行回收。)
虚引用(Phantom Reference):一个对象是否存在虚引用,完全不会对其生存时间构成影响。
关于方法区中需要回收的是一些废弃的常量和无用的类。
1.废弃的常量的回收。这里看引用计数就可以了。没有对象引用该常量就可以放心的回收了。
2.无用的类的回收。什么是无用的类呢?
A.该类所有的实例都已经被回收。也就是Java 堆中不存在该类的任何实例;
B.加载该类的ClassLoader 已经被回收;
C.该类对应的java.lang.Class 对象没有任何地方被引用,无法在任何地方通过反射访问该类的方法。
总而言之:
对于堆中的对象,主要用可达性分析判断一个对象是否还存在引用,如果该对象没有任何引用就应该被回收。而根据我们实际对引用的不同需求,又分成了4 中引用,每种引用的回收机制也是不同的。
对于方法区中的常量和类,当一个常量没有任何对象引用它,它就可以被回收了。而对于类,如果可以判定它为无用类,就可以被回收了。
新生代与复制算法
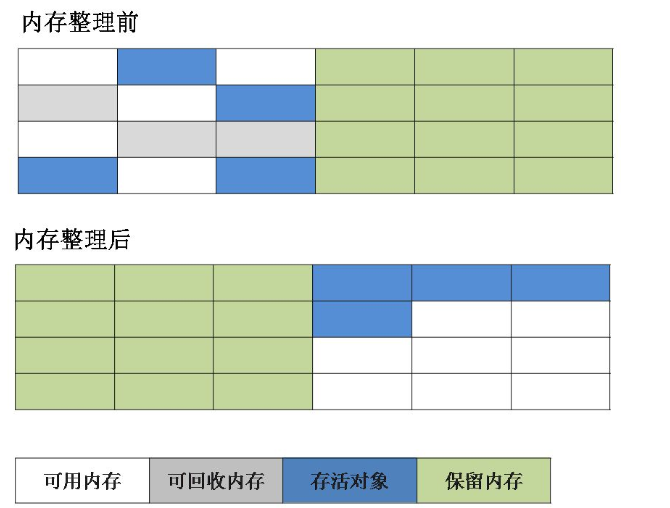
目前大部分JVM的GC对于新生代都采取Copying算法,因为新生代中每次垃圾回收都要回收大部分对象,即要复制的操作比较少,但通常并不是按照1:1来划分新生代。一般将新生代划分为一块较大的Eden空间和两个较小的Survivor空间(From Space, To Space),每次使用Eden空间和其中的一块Survivor空间,当进行回收时,将该两块空间中还存活的对象复制到另一块Survivor空间中。

复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
老年代与标记复制算法
而老年代因为每次只回收少量对象,因而采用Mark-Compact算法。
- JAVA虚拟机提到过的处于方法区的永生代(Permanet Generation),它用来存储class类,常量,方法描述等。对永生代的回收主要包括废弃常量和无用的类。
- 对象的内存分配主要在新生代的Eden Space和Survivor Space的From Space(Survivor目前存放对象的那一块),少数情况会直接分配到老生代。
- 当新生代的Eden Space和From Space空间不足时就会发生一次GC,进行GC后,Eden Space和From Space区的存活对象会被挪到To Space,然后将Eden Space和From Space进行清理。
- 如果To Space无法足够存储某个对象,则将这个对象存储到老生代。
- 在进行GC后,使用的便是Eden Space和To Space了,如此反复循环。
- 当对象在Survivor区躲过一次GC后,其年龄就会+1。默认情况下年龄到达15的对象会被移到老生代中。
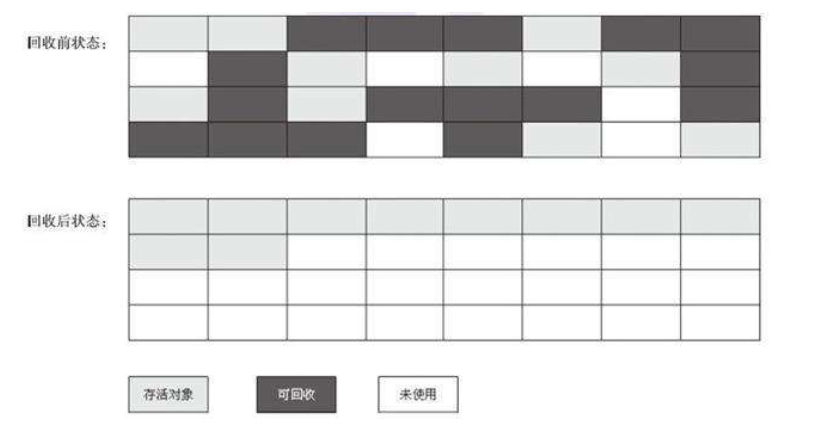
标记-整理算法
根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
HashMap的底层数据结构,局限性与线程安全
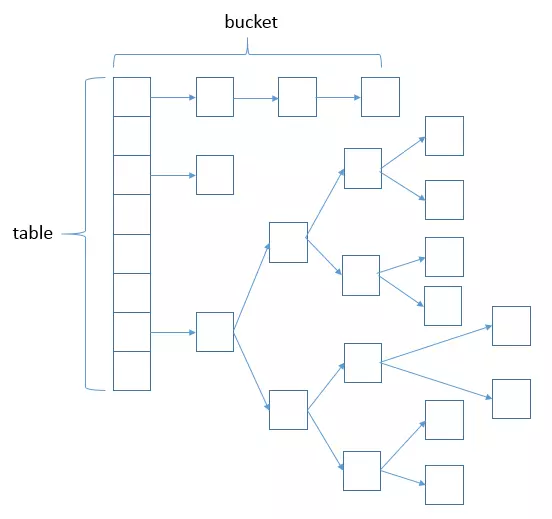
HashMap数据结构
哈希表结构(链表散列:数组+链表)实现,结合数组和链表的优点。当链表长度超过8时,链表转换为红黑树。
transient Node
HashMap的工作原理
A:HashMap底层是hash数组和单向链表实现,数组中的每个元素都是链表,由Node内部类(实现Map.Entry
存储对象时,将K/V键值对传给put()方法;
①、调用hash(K)方法计算K的hash值,然后结合数组长度,计算得数组下标;
②、调整数组大小(当容器中得元素个数大于capacity*loadFactor时,容器会进行resize为2n)
③、
i、如果K的hash值在HashMap不存在,则执行插入;若存在,则发生碰撞;
ii、如果K的hash值在HashMap存在,且它们两者equals返回true,则更新键值对;
iii、如果K的hash值在HashMap存在,且它们两者equals返回false,则插入链表的尾部(尾插法)或者红黑树(树的添加方式)
(JDK1.7 之前使用头插法、JDK 1.8 使用尾插法)
(注意:当碰撞导致链表大于TREEIFY_THRESHOLD = 8时,就把链表转换为红黑树)
(注意:当碰撞导致链表大于TREEIFY_THRESHOLD = 8时,就把链表转换为红黑树)
获取对象时,将K传给get()方法:
①、调用hash(K)方法(计算K的hash值)从而获取该键值对所在链表的数组下标;
②、顺序遍历链表,equals()方法查找相同Node链表K值对应的V值
hashCode是定位的,存储位置;
equals是定性的,比较两者是否相等。
当两个对象的hashCode相同会发生什么?
A:因为hashCode相同,不一定就是相等的(equals方法比较),所以两个对象所在数组下标相同,“碰撞”就此发生。又因为HashMap使用链表存储对象,这个Node会存储到链表下。
你知道hash的实现吗?为什么要这样实现?
A:JDK1.8中,是通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()^(h>>>16))
主要是从速度、功效和质量来考虑的,减少系统的开销,也不会造成因为高位没有参与下标的计算,从而引起的碰撞。
为什么要用异或运算符?
A:保持了对象的hashCode的32位值只要有一位发生改变,整个hash()返回值就会改变。尽可能的减少碰撞。
HashMap的table的容量如何确定?loadFactor是什么?该容量如何变化?这种变化会带来什么问题?
A:
①、table数组大小是由capacity这个参数确定的,默认是16,也可以构造时传入,最大限制为1<<30;
②、loadFactor是负载因子,主要目的是用来确认table数组是否需要动态扩展,默认值是0.75,比如table数组大小为16,装载因子为0.75时,threshold就是12,当table的实际大小超过12时,table就需要动态扩容;
③、扩容时,调用resize()方法,将table长度变为原来的两倍(注意是table长度,而不是threshold)
④、如果数据很大的情况下,扩展时将会带来性能的损失,在性能要求很高的地方,这种损失很可能很致命。
HashMap、LinkedHashMap、TreeMap有什么区别?
A:HashMap参考其他问题;
LinkedHashMap保存了记录得插入顺序,用iterator遍历时,先取到得记录肯定是先插入得;遍历比HashMap慢;
TreeMap实现SortMap接口,能够把它保存的记录根据键排序(默认按键值升序排序,也可以知道排序得比较器)
HashMap和HashTable有什么区别?
A:
①、HashMap是线程不安全,HashTable是线程安全的;
②、由于线程安全,所以HashTable的效率比不上HashMap;
③、HashMap最多只允许一条记录的键为null,允许多条记录的值为null,而HashTable不允许;
④、HashMao默认初始化数组的大小为16,HashTable为11,前者扩容时,扩大两倍,后者扩大两倍+1;
⑤、HashMap需要重新计算hash值,而HashTable直接使用对象的hashCode。
同样是线程类,ConcurrentHashMap 和 HashTable 在线程同步上有什么不同
A:ConcurrentHashMap类(是Java并发包java.util.concurrent中提供的一个线程安全且高效的Hash Map实现)
HashTable是使用synchronize关键字加锁的原理(就是对对象加锁)
而针对ConcurrentHashMap,在JDK1.7 中采用分段锁的方式,JDK1.8 中直接采用了CAS(无锁算法)+ synchronized。
HashMap & ConcurrentHashMap 的区别?
A:除了加锁,原理上无太大区别。
另外,HashMap的键值对允许有null,但是ConcurrentHashMap 都不允许。
为什么 ConcurrentHashMap 比 HashTable 效率要高?
A:HashTable使用一把锁(锁住整个链表结构)处理并发问题,多个线程竞争一把锁,容易阻塞;
ConcurrentHashMap :
JDK1.7使用分段锁(ReentrantLock + Segment + HashEntry)相当于把一个HashMap分成多个段,每段分配一把锁,这样支持多线程访问。锁粒度:基于Segment,包含多个HashEntry。
JDK1.8使用CAS + synchronized + Node + 红黑树。 锁粒度:Node(首结点)(实现Map.Entry
因为多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
Collections.sychronizedMap与ConcurrentHashMap的区别
Collections.synchronizedMap()与ConcurrentHashMap主要区别是:Collections.synchronizedMap()和Hashtable一样,实现上在调用map所有方法时,都对整个map进行同步,而ConcurrentHashMap的实现却更加精细,它对map中的所有桶加了锁。所以,只要要有一个线程访问map,其他线程就无法进入map,而如果一个线程在访问ConcurrentHashMap某个桶时,其他线程,仍然可以对map执行某些操作。这样,ConcurrentHashMap在性能以及安全性方面,明显比Collections.synchronizedMap()更加有优势。同时,同步操作精确控制到桶,所以,即使在遍历map时,其他线程试图对map进行数据修改,也不会抛出ConcurrentModificationException。
但是,细心的朋友可能发现了,上面的例子,即使map=map3时,最后打印的结果可以并没有100行。由于,不论Collections.synchronizedMap()还是ConcurrentHashMap对map同步的原子操作都是作用的map的方法上,map在读取与清空之间,线程间是不同步的。上面代码的不足在于,我们对这些同步的map过于信任,而忽略了混合操作带来的影响。正确的方法是,把map的读取和清空看成一个原子操作,给整个代码块加锁。
还有一个区别是:ConcurrentHashMap从类的命名就能看出,它必然是个HashMap。而Collections.synchronizedMap()可以接收任意Map实例,实现Map的同步。
ThreadLocal
ThreadLocal顾名思义是线程私有的局部变量存储容器,可以理解成每个线程都有自己专属的存储容器,它用来存储线程私有变量,其实它只是一个外壳,内部真正存取是一个Map,后面会仔细讲解。每个线程可以通过set()和get()存取变量,多线程间无法访问各自的局部变量,相当于在每个线程间建立了一个隔板。只要线程处于活动状态,它所对应的ThreadLocal实例就是可访问的,线程被终止后,它的所有实例将被垃圾收集。总之记住一句话:ThreadLocal存储的变量属于当前线程。
ThreadLocal ,也叫线程本地变量,可能很多朋友都知道ThreadLocal为变量在每个线程中都创建了所使用的的变量副本。使用起来都是在线程的本地工作内存中操作,并且提供了set和get方法来访问拷贝过来的变量副本。底层也是封装了ThreadLocalMap集合类来绑定当前线程和变量副本的关系,各个线程独立并且访问安全。
set方法:
1 | public void set(T value) { |
(1) ThreadLocal仅仅是个变量访问的入口;
(2) 每一个Thread对象都有一个ThreadLocalMap对象,这个ThreadLocalMap持有对象的引用;
(3) ThreadLocalMap以当前的threadLocal对象为key,以真正的存储对象为value。get()方法时通过threadLocal实例就可以找到绑定在当前线程上的副本对象。
ThreadLocal这样设计有两个目的:
第一:可以保证当前线程结束时,相关对象可以立即被回收;第二:ThreadLocalMap元素会大大减少,因为Map过大容易造成哈希冲突而导致性能降低。
get方法:
1 | public T get() { |
ThreadLocal对象通常用于防止对可变的单实例变量或全局变量进行共享。例如:由于JDBC的连接对象不是线程安全的,因此,当多个线程应用程序在没有协同的情况下,使用全局变量时,就是线程不安全的。通过将JDBC的连接对象保存到ThreadLocal中,每个线程都会拥有自己的连接对象副本。
反射
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。
静态编译和动态编译
- 静态编译:在编译时确定类型,绑定对象
动态编译:运行时确定类型,绑定对象
反射机制优缺点
优点: 运行期类型的判断,动态加载类,提高代码灵活度。
- 缺点: 性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的 java 代码要慢很多。
反射的应用场景
反射是框架设计的灵魂。
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
举例:① 我们在使用 JDBC 连接数据库时使用 Class.forName()通过反射加载数据库的驱动程序;②Spring 框架也用到很多反射机制,最经典的就是 xml 的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程:1) 将程序内所有 XML 或 Properties 配置文件加载入内存中; 2)Java 类里面解析 xml 或 properties 里面的内容,得到对应实体类的字节码字符串以及相关的属性信息; 3)使用反射机制,根据这个字符串获得某个类的 Class 实例; 4)动态配置实例的属性
推荐阅读:
IO

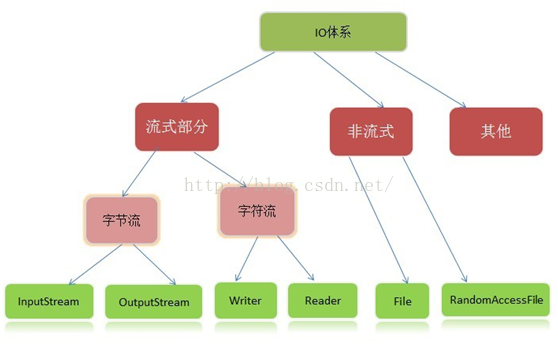
在整个Java.io包中最重要的就是5个类和一个接口。5个类指的是File、OutputStream、InputStream、Writer、Reader;一个接口指的是Serializable.掌握了这些IO的核心操作那么对于Java中的IO体系也就有了一个初步的认识了
Java I/O主要包括如下几个层次,包含三个部分:
1.流式部分――IO的主体部分;
2.非流式部分――主要包含一些辅助流式部分的类,如:File类、RandomAccessFile类和FileDescriptor等类;
3.其他类—文件读取部分的与安全相关的类,如:SerializablePermission类,以及与本地操作系统相关的文件系统的类,如:FileSystem类和Win32FileSystem类和WinNTFileSystem类。
File(文件特征与管理):用于文件或者目录的描述信息,例如生成新目录,修改文件名,删除文件,判断文件所在路径等。
InputStream(二进制格式操作):抽象类,基于字节的输入操作,是所有输入流的父类。定义了所有输入流都具有的共同特征。
OutputStream(二进制格式操作):抽象类。基于字节的输出操作。是所有输出流的父类。定义了所有输出流都具有的共同特征。
Reader(文件格式操作):抽象类,基于字符的输入操作。
Writer(文件格式操作):抽象类,基于字符的输出操作。
RandomAccessFile(随机文件操作):一个独立的类,直接继承至Object.它的功能丰富,可以从文件的任意位置进行存取(输入输出)操作。
流:代表任何有能力产出数据的数据源对象或者是有能力接受数据的接收端对象
流的本质:数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
流的作用:为数据源和目的地建立一个输送通道。
Java中将输入输出抽象称为流,就好像水管,将两个容器连接起来。流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流.
IO流的分类
· 根据处理数据类型的不同分为:字符流和字节流
· 根据数据流向不同分为:输入流和输出流
· 按数据来源(去向)分类:
1、File(文件): FileInputStream, FileOutputStream, FileReader, FileWriter
2、byte[]:ByteArrayInputStream, ByteArrayOutputStream
3、Char[]: CharArrayReader,CharArrayWriter
4、String:StringBufferInputStream, StringReader, StringWriter
5、网络数据流:InputStream,OutputStream, Reader, Writer
字符流和字节流
流序列中的数据既可以是未经加工的原始二进制数据,也可以是经一定编码处理后符合某种格式规定的特定数据。因此Java中的流分为两种:
1) 字节流:数据流中最小的数据单元是字节
2) 字符流:数据流中最小的数据单元是字符, Java中的字符是Unicode编码,一个字符占用两个字节。
字符流的由来: Java中字符是采用Unicode标准,一个字符是16位,即一个字符使用两个字节来表示。为此,JAVA中引入了处理字符的流。因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。
输入流和输出流
根据数据的输入、输出方向的不同对而将流分为输入流和输出流。
1) 输入流
程序从输入流读取数据源。数据源包括外界(键盘、文件、网络…),即是将数据源读入到程序的通信通道
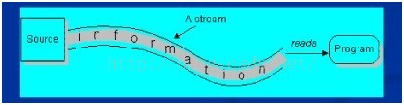
2) 输出流
程序向输出流写入数据。将程序中的数据输出到外界(显示器、打印机、文件、网络…)的通信通道。
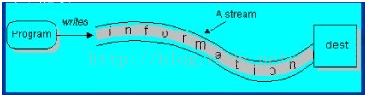
采用数据流的目的就是使得输出输入独立于设备。
输入流( Input Stream )不关心数据源来自何种设备(键盘,文件,网络)。
输出流( Output Stream )不关心数据的目的是何种设备(键盘,文件,网络)。
3)特性
相对于程序来说,输出流是往存储介质或数据通道写入数据,而输入流是从存储介质或数据通道中读取数据,一般来说关于流的特性有下面几点:
1、先进先出,最先写入输出流的数据最先被输入流读取到。
2、顺序存取,可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile可以从文件的任意位置进行存取(输入输出)操作)
3、只读或只写,每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
IO流对象
1.输入字节流InputStream
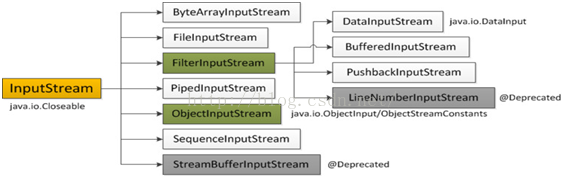
IO 中输入字节流的继承图可见上图,可以看出:
InputStream是所有的输入字节流的父类,它是一个抽象类。
ByteArrayInputStream、StringBufferInputStream(上图的StreamBufferInputStream)、FileInputStream是三种基本的介质流,它们分别从Byte数组、StringBuffer、和本地文件中读取数据。
PipedInputStream是从与其它线程共用的管道中读取数据.
ObjectInputStream和所有FilterInputStream的子类都是装饰流(装饰器模式的主角)。
InputStream中的三个基本的读方法
abstract int read() :读取一个字节数据,并返回读到的数据,如果返回-1,表示读到了输入流的末尾。
intread(byte[]?b) :将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。
intread(byte[]?b, int?off, int?len) :将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。off指定在数组b中存放数据的起始偏移位置;len指定读取的最大字节数。
流结束的判断:方法read()的返回值为-1时;readLine()的返回值为null时。
其它方法
long skip(long?n):在输入流中跳过n个字节,并返回实际跳过的字节数。
int available() :返回在不发生阻塞的情况下,可读取的字节数。
void close() :关闭输入流,释放和这个流相关的系统资源。
voidmark(int?readlimit) :在输入流的当前位置放置一个标记,如果读取的字节数多于readlimit设置的值,则流忽略这个标记。
void reset() :返回到上一个标记。
booleanmarkSupported() :测试当前流是否支持mark和reset方法。如果支持,返回true,否则返回false。
输出字节流OutputStream
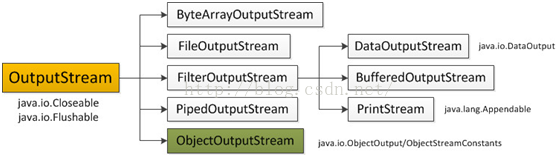
IO 中输出字节流的继承图可见上图,可以看出:
OutputStream是所有的输出字节流的父类,它是一个抽象类。
ByteArrayOutputStream、FileOutputStream是两种基本的介质流,它们分别向Byte数组、和本地文件中写入数据。PipedOutputStream是向与其它线程共用的管道中写入数据。
ObjectOutputStream和所有FilterOutputStream的子类都是装饰流。
outputStream中的三个基本的写方法 abstract void write(int?b):往输出流中写入一个字节。 void write(byte[]?b) :往输出流中写入数组b中的所有字节。 void write(byte[]?b, int?off, int?len) :往输出流中写入数组b中从偏移量off开始的len个字节的数据。
其它方法 void flush() :刷新输出流,强制缓冲区中的输出字节被写出。 void close() :关闭输出流,释放和这个流相关的系统资源。
volatile关键字的含义
volatile关键字是由JVM提供的最轻量级同步机制。与被滥用的synchronized不同,我们并不习惯使用它。
Java内存模型由Java虚拟机规范定义,用来屏蔽各个平台的硬件差异。简单来说:
- 所有变量储存在主内存。
- 每条线程拥有自己的工作内存,其中保存了主内存中线程使用到的变量的副本。
- 线程不能直接读写主内存中的变量,所有操作均在工作内存中完成。
线程,主内存,工作内存的交互关系如图。
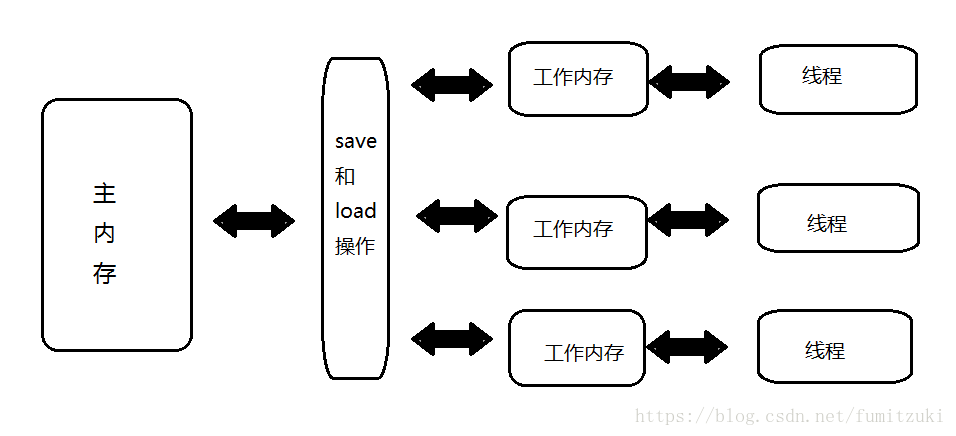
内存间的交互操作有很多,和volatile有关的操作为:
- read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
- write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
对被volatile修饰的变量进行操作时,需要满足以下规则:
- 规则1:线程对变量执行的前一个动作是load时才能执行use,反之只有后一个动作是use时才能执行load。线程对变量的read,load,use动作关联,必须连续一起出现。——-这保证了线程每次使用变量时都需要从主存拿到最新的值,保证了其他线程修改的变量本线程能看到。
- 规则2:线程对变量执行的前一个动作是assign时才能执行store,反之只有后一个动作是store时才能执行assign。线程对变量的assign,store,write动作关联,必须连续一起出现。——-这保证了线程每次修改变量后都会立即同步回主内存,保证了本线程修改的变量其他线程能看到。
- 规则3:有线程T,变量V、变量W。假设动作A是T对V的use或assign动作,P是根据规则2、3与A关联的read或write动作;动作B是T对W的use或assign动作,Q是根据规则2、3与B关联的read或write动作。如果A先与B,那么P先与Q。———这保证了volatile修饰的变量不会被指令重排序优化,代码的执行顺序与程序的顺序相同。
1.被volatile修饰的变量保证对所有线程可见。
由上文的规则1、2可知,volatile变量对所有线程是立即可见的,在各个线程中不存在一致性问题。volatile关键字只保证可见性,所以在以下情况中,需要使用锁来保证原子性:
- 运算结果依赖变量的当前值,并且有不止一个线程在修改变量的值。
- 变量需要与其他状态变量共同参与不变约束
2.禁止指令重排序优化。
jvm会把代码中没有依赖赋值的地方打乱执行顺序,由于一些规则限定,我们在单线程内观察不到打乱的现象(线程内表现为串行的语义),但是在并发程序中,从别的线程看另一个线程,操作是无序的。
总结
并发三特征可见性和有序性和原子性中,volatile通过新值立即同步到主内存和每次使用前从主内存刷新机制保证了可见性。
通过禁止指令重排序保证了有序性。
无法保证原子性。
而我们知道,synchronized关键字通过lock和unlock操作保证了原子性,
通过对一个变量unlock前,把变量同步回主内存中保证了可见性,
通过一个变量在同一时刻只允许一条线程对其进行lock操作保证了有序性。
他的“万能”也间接导致了我们对synchronized关键字的滥用,越泛用的控制,对性能的影响也越大,虽然jvm不断的对synchronized关键字进行各种各样的优化,但是我们还是要在合适的时候想起volatile关键字。
JAVA NIO
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
NIO和传统IO(一下简称IO)之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变得可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
首先说一下Channel,国内大多翻译成“通道”。Channel和IO中的Stream(流)是差不多一个等级的。只不过Stream是单向的,譬如:InputStream, OutputStream.而Channel是双向的,既可以用来进行读操作,又可以用来进行写操作。
NIO中的关键Buffer实现有:ByteBuffer, CharBuffer, DoubleBuffer, FloatBuffer, IntBuffer, LongBuffer, ShortBuffer,分别对应基本数据类型: byte, char, double, float, int, long, short。当然NIO中还有MappedByteBuffer, HeapByteBuffer, DirectByteBuffer等这里先不进行陈述。
Selector运行单线程处理多个Channel,如果你的应用打开了多个通道,但每个连接的流量都很低,使用Selector就会很方便。例如在一个聊天服务器中。要使用Selector, 得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新的连接进来、数据接收等。
String 不可变
String 底层实现:
1 | public final class String |
String 的底层实现是依靠 char[] 数组,既然依靠的是基础类型变量,那么他一定是可变的, String 之所以不可变,是因为 Java 的开发者通过技术实现,隔绝了使用者对 String 的底层数据的操作。但是,我们可以同反射的机制,操作 String 的底层,检验其不可变的猜想。
为什么会将 String 设计为不可变
- 安全
- 引发安全问题,譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,造成安全漏洞
- 保证线程安全,在并发场景下,多个线程同时读写资源时,会引竞态条件,由于 String 是不可变的,不会引发线程的问题而保证了线程
- HashCode,当 String 被创建出来的时候,hashcode也会随之被缓存,hashcode的计算与value有关,若 String 可变,那么 hashcode 也会随之变化,针对于 Map、Set 等容器,他们的键值需要保证唯一性和一致性,因此,String 的不可变性使其比其他对象更适合当容器的键值。
- 性能
- 当字符串是不可变时,字符串常量池才有意义。字符串常量池的出现,可以减少创建相同字面量的字符串,让不同的引用指向池中同一个字符串,为运行时节约很多的堆内存。若字符串可变,字符串常量池失去意义,基于常量池的String.intern()方法也失效,每次创建新的 String 将在堆内开辟出新的空间,占据更多的内存
jre , jdk , jvm 的关系
JVM :英文名称(Java Virtual Machine),就是我们耳熟能详的 Java 虚拟机。它只认识 xxx.class 这种类型的文件,它能够将 class 文件中的字节码指令进行识别并调用操作系统向上的 API 完成动作。所以说,jvm 是 Java 能够跨平台的核心,具体的下文会详细说明。
什么是字节码?采用字节码的好处是什么?
在 Java 中,JVM 可以理解的代码就叫做
字节码(即扩展名为.class的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
Java 程序从源代码到运行一般有下面 3 步:
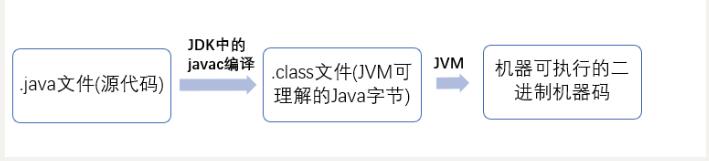
我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。
HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。
总结:
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
JRE :英文名称(Java Runtime Environment),我们叫它:Java 运行时环境。它主要包含两个部分,jvm 的标准实现和 Java 的一些基本类库。它相对于 jvm 来说,多出来的是一部分的 Java 类库。
JDK :英文名称(Java Development Kit),Java 开发工具包。jdk 是整个 Java 开发的核心,它集成了 jre 和一些好用的小工具。例如:javac.exe,java.exe,jar.exe 等。
显然,这三者的关系是:一层层的嵌套关系。JDK>JRE>JVM。
什么是字节码?采用字节码的最大好处是什么?
先看下 java 中的编译器和解释器:
Java 中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在 Java 中,这种供虚拟机理解的代码叫做字节码(即扩展名为.class的文件),它不面向任何特定的处理器,只面向虚拟机。每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java 源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。这也就是解释了 Java 的编译与解释并存的特点。
Java 源代码——>编译器——>jvm 可执行的 Java 字节码(即虚拟指令)——>jvm——>jvm 中解释器——->机器可执行的二进制机器码——>程序运行。
采用字节码的好处:
Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同的计算机上运行。
接口和抽象类的区别是什么?
- 接口的方法默认是 public,所有方法在接口中不能有实现,抽象类可以有非抽象的方法
- 接口中的实例变量默认是 final 类型的,而抽象类中则不一定
- 一个类可以实现多个接口,但最多只能实现一个抽象类
- 一个类实现接口的话要实现接口的所有方法,而抽象类不一定
- 接口不能用 new 实例化,但可以声明,但是必须引用一个实现该接口的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
注意:Java8 后接口可以有默认实现( default )。
重载和重写的区别
重载
发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
重写
重写是子类对父类的允许访问的方法的实现过程进行重新编写,发生在子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。另外,如果父类方法访问修饰符为 private 则子类就不能重写该方法。也就是说方法提供的行为改变,而方法的外貌并没有改变。
Java 面向对象编程三大特性: 封装 继承 多态
封装
封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
继承
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。
关于继承如下 3 点请记住:
- 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。(以后介绍)。
多态
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
在 Java 中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
什么是线程和进程?
何为进程?
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。
在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
何为线程?
线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
一个 Java 程序的运行是 main 线程和多个其他线程同时运行。
请简要描述线程与进程的关系,区别及优缺点?
从 JVM 角度说进程和线程之间的关系
图解进程和线程的关系
下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下这篇文章:《可能是把 Java 内存区域讲的最清楚的一篇文章》
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)资源,但是每个线程有自己的程序计数器、虚拟机栈 和 本地方法栈。
总结: 线程 是 进程 划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反
下面是该知识点的扩展内容!
下面来思考这样一个问题:为什么程序计数器、虚拟机栈和本地方法栈是线程私有的呢?为什么堆和方法区是线程共享的呢?
程序计数器为什么是私有的?
程序计数器主要有下面两个作用:
- 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
需要注意的是,如果执行的是 native 方法,那么程序计数器记录的是 undefined 地址,只有执行的是 Java 代码时程序计数器记录的才是下一条指令的地址。
所以,程序计数器私有主要是为了线程切换后能恢复到正确的执行位置。
虚拟机栈和本地方法栈为什么是私有的?
- 虚拟机栈: 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
- 本地方法栈: 和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
所以,为了保证线程中的局部变量不被别的线程访问到,虚拟机栈和本地方法栈是线程私有的。
一句话简单了解堆和方法区
堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
什么是上下文切换?
多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。
概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。任务从保存到再加载的过程就是一次上下文切换。
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
什么是线程死锁?如何避免死锁?
认识线程死锁
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
如何避免线程死锁?
我们只要破坏产生死锁的四个条件中的其中一个就可以了。
破坏互斥条件
这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
破坏请求与保持条件
一次性申请所有的资源。
破坏不剥夺条件
占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
破坏循环等待条件
靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
Object 类有哪些方法?
这个问题,面试中经常出现。我觉得不论是出于应付面试还是说更好地掌握 Java 这门编程语言,大家都要掌握!
Object 类的常见方法总结
Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
1 | public final native Class<?> getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。 |
问完上面这个问题之后,面试官很可能紧接着就会问你“hashCode 与 equals”相关的问题。
hashCode 与 equals
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode 方法?”
hashCode()介绍
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object.java 中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
1 | public native int hashCode(); |
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode
我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
hashCode()与 equals()的相关规定
- 如果两个对象相等,则 hashcode 一定也是相同的
- 两个对象相等,对两个对象分别调用 equals 方法都返回 true
- 两个对象有相同的 hashcode 值,它们也不一定是相等的
- 因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
- hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?
在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
因为 hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode)。
我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
synchronized 和 ReentrantLock 的区别
① 两者都是可重入锁
两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
② synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReentrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
③ ReentrantLock 比 synchronized 增加了一些高级功能
相比 synchronized,ReentrantLock 增加了一些高级功能。主要来说主要有三点:① 等待可中断;② 可实现公平锁;③ 可实现选择性通知(锁可以绑定多个条件)
- ReentrantLock 提供了一种能够中断等待锁的线程的机制,通过 lock.lockInterruptibly() 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
- ReentrantLock 可以指定是公平锁还是非公平锁。而 synchronized 只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。 ReentrantLock 默认情况是非公平的,可以通过 ReentrantLock 类的
ReentrantLock(boolean fair)构造方法来制定是否是公平的。 - synchronized 关键字与 wait()和 notify/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock 类当然也可以实现,但是需要借助于 Condition 接口与 newCondition() 方法。Condition 是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个 Lock 对象中可以创建多个 Condition 实例(即对象监视器),线程对象可以注册在指定的 Condition 中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用 notify/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用 ReentrantLock 类结合 Condition 实例可以实现“选择性通知” ,这个功能非常重要,而且是 Condition 接口默认提供的。而 synchronized 关键字就相当于整个 Lock 对象中只有一个 Condition 实例,所有的线程都注册在它一个身上。如果执行 notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而 Condition 实例的 signalAll()方法 只会唤醒注册在该 Condition 实例中的所有等待线程。
如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。
④ 两者的性能已经相差无几
在 JDK1.6 之前,synchronized 的性能是比 ReentrantLock 差很多。具体表示为:synchronized 关键字吞吐量随线程数的增加,下降得非常严重。而 ReentrantLock 基本保持一个比较稳定的水平。我觉得这也侧面反映了, synchronized 关键字还有非常大的优化余地。后续的技术发展也证明了这一点,我们上面也讲了在 JDK1.6 之后 JVM 团队对 synchronized 关键字做了很多优化。JDK1.6 之后,synchronized 和 ReentrantLock 的性能基本是持平了。所以网上那些说因为性能才选择 ReentrantLock 的文章都是错的!JDK1.6 之后,性能已经不是选择 synchronized 和 ReentrantLock 的影响因素了!而且虚拟机在未来的性能改进中会更偏向于原生的 synchronized,所以还是提倡在 synchronized 能满足你的需求的情况下,优先考虑使用 synchronized 关键字来进行同步!优化后的 synchronized 和 ReentrantLock 一样,在很多地方都是用到了 CAS 操作。
volatile
volatile 是一个类型修饰符。volatile 的作用是作为指令关键字,确保本条指令不会因编译器的优化而省略。
volatile 的特性
- 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。(实现可见性)
- 禁止进行指令重排序。(实现有序性)
- volatile 只能保证对单次读/写的原子性。i++ 这种操作不能保证原子性。
volatile 可见性实现
- volatile 变量的内存可见性是基于内存屏障(Memory Barrier)实现。
- 内存屏障,又称内存栅栏,是一个 CPU 指令。
- 在程序运行时,为了提高执行性能,编译器和处理器会对指令进行重排序,JMM 为了保证在不同的编译器和 CPU 上有相同的结果,通过插入特定类型的内存屏障来禁止特定类型的编译器重排序和处理器重排序,插入一条内存屏障会告诉编译器和 CPU:不管什么指令都不能和这条 Memory Barrier 指令重排序。
- 写一段简单的 Java 代码,声明一个 volatile 变量,并赋值。
1 | public class Test { |
- 通过 hsdis 和 jitwatch 工具可以得到编译后的汇编代码。
1 | ...... |
- lock 前缀的指令在多核处理器下会引发两件事情。
- 1)将当前处理器缓存行的数据写回到系统内存。
- 2)写回内存的操作会使在其他 CPU 里缓存了该内存地址的额数据无效。
- 为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2 或其他)后再进行操作,但操作完不知道何时会写到内存。
- 如果对声明了 volatile 的变量进行写操作,JVM 就会向处理器发送一条 lock 前缀的指令,将这个变量所在缓存行的数据写回到系统内存。
- 为了保证各个处理器的缓存是一致的,实现了缓存一致性协议(MESI),每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
- 所有多核处理器下还会完成:3)当处理器发现本地缓存失效后,就会从内存中重读该变量数据,即可以获取当前最新值。
- volatile 变量通过这样的机制就使得每个线程都能获得该变量的最新值。
lock 指令
- 在 Pentium 和早期的 IA-32 处理器中,lock 前缀会使处理器执行当前指令时产生一个 LOCK# 信号,会对总线进行锁定,其它 CPU 对内存的读写请求都会被阻塞,直到锁释放。
- 后来的处理器,加锁操作是由高速缓存锁代替总线锁来处理。
- 因为锁总线的开销比较大,锁总线期间其他 CPU 没法访问内存。
- 这种场景多缓存的数据一致通过缓存一致性协议(MESI)来保证。
缓存一致性
- 缓存是分段(line)的,一个段对应一块存储空间,称之为缓存行,它是 CPU 缓存中可分配的最小存储单元,大小 32 字节、64 字节、128 字节不等,这与 CPU 架构有关,通常来说是 64 字节。
- LOCK# 因为锁总线效率太低,因此使用了多组缓存。
- 为了使其行为看起来如同一组缓存那样。因而设计了 缓存一致性协议。
- 缓存一致性协议有多种,但是日常处理的大多数计算机设备都属于 “ 嗅探(snooping)” 协议。
- 所有内存的传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线。
- 缓存本身是独立的,但是内存是共享资源,所有的内存访问都要经过仲裁(同一个指令周期中,只有一个 CPU 缓存可以读写内存)。
- CPU 缓存不仅仅在做内存传输的时候才与总线打交道,而是不停在嗅探总线上发生的数据交换,跟踪其他缓存在做什么。
- 当一个缓存代表它所属的处理器去读写内存时,其它处理器都会得到通知,它们以此来使自己的缓存保持同步。
- 只要某个处理器写内存,其它处理器马上知道这块内存在它们的缓存段中已经失效。
volatile 禁止重排序
- 为了性能优化,JMM 在不改变正确语义的前提下,会允许编译器和处理器对指令序列进行重排序。JMM 提供了内存屏障阻止这种重排序。
- Java 编译器会在生成指令系列时在适当的位置会插入内存屏障指令来禁止特定类型的处理器重排序。
- JMM 会针对编译器制定 volatile 重排序规则表。

volatile 重排序规则表
- “ NO “ 表示禁止重排序。
- 为了实现 volatile 内存语义时,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
- 对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎是不可能的,为此,JMM 采取了保守的策略。
- 在每个 volatile 写操作的前面插入一个 StoreStore 屏障。
- 在每个 volatile 写操作的后面插入一个 StoreLoad 屏障。
- 在每个 volatile 读操作的后面插入一个 LoadLoad 屏障。
- 在每个 volatile 读操作的后面插入一个 LoadStore 屏障。
- volatile 写是在前面和后面分别插入内存屏障,而 volatile 读操作是在后面插入两个内存屏障。
| 内存屏障 | 说明 |
|---|---|
| StoreStore 屏障 | 禁止上面的普通写和下面的 volatile 写重排序。 |
| StoreLoad 屏障 | 防止上面的 volatile 写与下面可能有的 volatile 读/写重排序。 |
| LoadLoad 屏障 | 禁止下面所有的普通读操作和上面的 volatile 读重排序。 |
| LoadStore 屏障 | 禁止下面所有的普通写操作和上面的 volatile 读重排序。 |
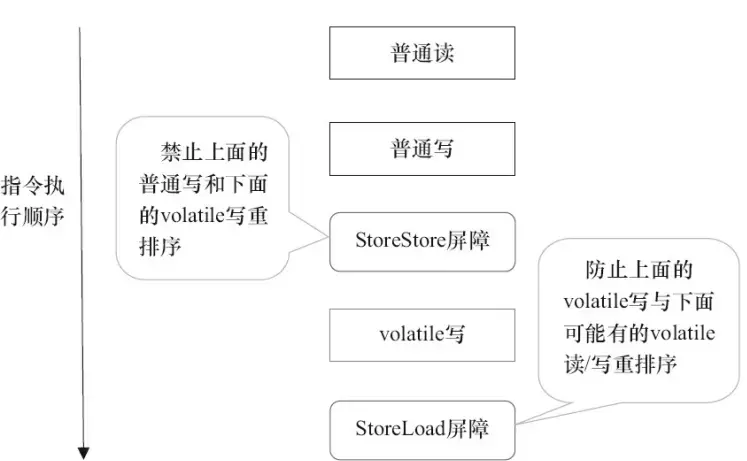
volatile 写插入内存屏障
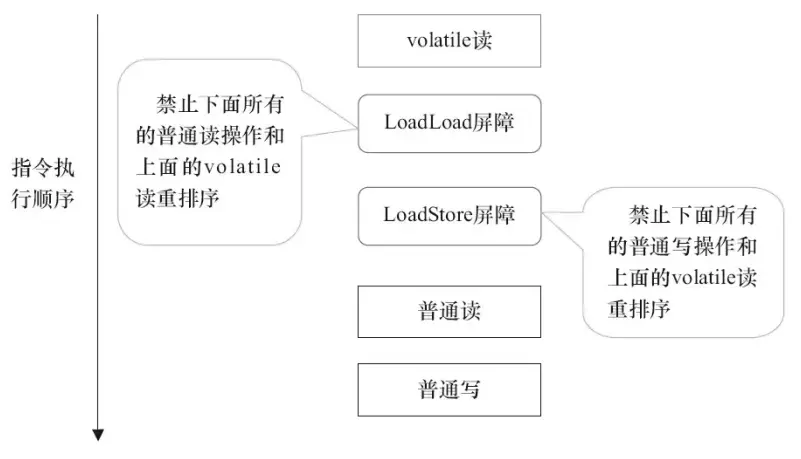
volatile 读插入内存屏障
为什么num++多线程不安全?
原因如图
一个num++操作java来写是一句,但执行时候汇编成字节码是4句:从主内存取到工作内存、压栈、加操作、放回主内存。
线程池
为什么要用线程池?
线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
这里借用《Java 并发编程的艺术》提到的来说一下使用线程池的好处:
- 降低资源消耗。 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
Java 提供了哪几种线程池?他们各自的使用场景是什么?
Java 主要提供了下面 4 种线程池
- FixedThreadPool: 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
- SingleThreadExecutor: 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
- CachedThreadPool: 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
- ScheduledThreadPoolExecutor: 主要用来在给定的延迟后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor 又分为:ScheduledThreadPoolExecutor(包含多个线程)和 SingleThreadScheduledExecutor (只包含一个线程)两种。
各种线程池的适用场景介绍
- FixedThreadPool: 适用于为了满足资源管理需求,而需要限制当前线程数量的应用场景。它适用于负载比较重的服务器;
- SingleThreadExecutor: 适用于需要保证顺序地执行各个任务并且在任意时间点,不会有多个线程是活动的应用场景;
- CachedThreadPool: 适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器;
- ScheduledThreadPoolExecutor: 适用于需要多个后台执行周期任务,同时为了满足资源管理需求而需要限制后台线程的数量的应用场景;
- SingleThreadScheduledExecutor: 适用于需要单个后台线程执行周期任务,同时保证顺序地执行各个任务的应用场景。
创建的线程池的方式
(1) 使用 Executors 创建
我们上面刚刚提到了 Java 提供的几种线程池,通过 Executors 工具类我们可以很轻松的创建我们上面说的几种线程池。但是实际上我们一般都不是直接使用 Java 提供好的线程池,另外在《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 构造函数 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
1 | Executors 返回线程池对象的弊端如下: |
(2) ThreadPoolExecutor 的构造函数创建
我们可以自己直接调用 ThreadPoolExecutor 的构造函数来自己创建线程池。在创建的同时,给 BlockQueue 指定容量就可以了。示例如下:
1 | private static ExecutorService executor = new ThreadPoolExecutor(13, 13, |
1 | public ThreadPoolExecutor(int corePoolSize, // 1 |
| 序号 | 名称 | 类型 | 含义 |
|---|---|---|---|
| 1 | corePoolSize | int | 核心线程池大小 |
| 2 | maximumPoolSize | int | 最大线程池大小 |
| 3 | keepAliveTime | long | 线程最大空闲时间 |
| 4 | unit | TimeUnit | 时间单位 |
| 5 | workQueue | BlockingQueue |
线程等待队列 |
| 6 | threadFactory | ThreadFactory | 线程创建工厂 |
| 7 | handler | RejectedExecutionHandler | 拒绝策略 |
这种情况下,一旦提交的线程数超过当前可用线程数时,就会抛出 java.util.concurrent.RejectedExecutionException,这是因为当前线程池使用的队列是有边界队列,队列已经满了便无法继续处理新的请求。但是异常(Exception)总比发生错误(Error)要好。
(3) 使用开源类库
Hollis 大佬之前在他的文章中也提到了:“除了自己定义 ThreadPoolExecutor 外。还有其他方法。这个时候第一时间就应该想到开源类库,如 apache 和 guava 等。”他推荐使用 guava 提供的 ThreadFactoryBuilder 来创建线程池。下面是参考他的代码示例:
1 | public class ExecutorsDemo { |
通过上述方式创建线程时,不仅可以避免 OOM 的问题,还可以自定义线程名称,更加方便的出错的时候溯源。
workQueue任务队列
它一般分为直接提交队列、有界任务队列、无界任务队列、优先任务队列;
1、直接提交队列:设置为SynchronousQueue队列,SynchronousQueue是一个特殊的BlockingQueue,它没有容量,没执行一个插入操作就会阻塞,需要再执行一个删除操作才会被唤醒,反之每一个删除操作也都要等待对应的插入操作。
1 | public class ThreadPool { |
可以看到,当任务队列为SynchronousQueue,创建的线程数大于maximumPoolSize时,直接执行了拒绝策略抛出异常。
使用SynchronousQueue队列,提交的任务不会被保存,总是会马上提交执行。如果用于执行任务的线程数量小于maximumPoolSize,则尝试创建新的进程,如果达到maximumPoolSize设置的最大值,则根据你设置的handler执行拒绝策略。因此这种方式你提交的任务不会被缓存起来,而是会被马上执行,在这种情况下,你需要对你程序的并发量有个准确的评估,才能设置合适的maximumPoolSize数量,否则很容易就会执行拒绝策略;
2、有界的任务队列:有界的任务队列可以使用ArrayBlockingQueue实现,如下所示
1 | pool = new ThreadPoolExecutor(1, 2, 1000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(10),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy()); |
使用ArrayBlockingQueue有界任务队列,若有新的任务需要执行时,线程池会创建新的线程,直到创建的线程数量达到corePoolSize时,则会将新的任务加入到等待队列中。若等待队列已满,即超过ArrayBlockingQueue初始化的容量,则继续创建线程,直到线程数量达到maximumPoolSize设置的最大线程数量,若大于maximumPoolSize,则执行拒绝策略。在这种情况下,线程数量的上限与有界任务队列的状态有直接关系,如果有界队列初始容量较大或者没有达到超负荷的状态,线程数将一直维持在corePoolSize以下,反之当任务队列已满时,则会以maximumPoolSize为最大线程数上限。
3、无界的任务队列:有界任务队列可以使用LinkedBlockingQueue实现
1 | pool = new ThreadPoolExecutor(1, 2, 1000, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy()); |
使用无界任务队列,线程池的任务队列可以无限制的添加新的任务,而线程池创建的最大线程数量就是你corePoolSize设置的数量,也就是说在这种情况下maximumPoolSize这个参数是无效的,哪怕你的任务队列中缓存了很多未执行的任务,当线程池的线程数达到corePoolSize后,就不会再增加了;若后续有新的任务加入,则直接进入队列等待,当使用这种任务队列模式时,一定要注意你任务提交与处理之间的协调与控制,不然会出现队列中的任务由于无法及时处理导致一直增长,直到最后资源耗尽的问题。
4、优先任务队列:优先任务队列通过PriorityBlockingQueue实现,下面我们通过一个例子演示下
1 | public class ThreadPool { |
可以看到除了第一个任务直接创建线程执行外,其他的任务都被放入了优先任务队列,按优先级进行了重新排列执行,且线程池的线程数一直为corePoolSize,也就是只有一个。
通过运行的代码我们可以看出PriorityBlockingQueue它其实是一个特殊的无界队列,它其中无论添加了多少个任务,线程池创建的线程数也不会超过corePoolSize的数量,只不过其他队列一般是按照先进先出的规则处理任务,而PriorityBlockingQueue队列可以自定义规则根据任务的优先级顺序先后执行。
拒绝策略
一般我们创建线程池时,为防止资源被耗尽,任务队列都会选择创建有界任务队列,但种模式下如果出现任务队列已满且线程池创建的线程数达到你设置的最大线程数时,这时就需要你指定ThreadPoolExecutor的RejectedExecutionHandler参数即合理的拒绝策略,来处理线程池”超载”的情况。ThreadPoolExecutor自带的拒绝策略如下:
1、AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作;
2、CallerRunsPolicy策略:如果线程池的线程数量达到上限,该策略会把任务队列中的任务放在调用者线程当中运行;
3、DiscardOledestPolicy策略:该策略会丢弃任务队列中最老的一个任务,也就是当前任务队列中最先被添加进去的,马上要被执行的那个任务,并尝试再次提交;
4、DiscardPolicy策略:该策略会默默丢弃无法处理的任务,不予任何处理。当然使用此策略,业务场景中需允许任务的丢失;
以上内置的策略均实现了RejectedExecutionHandler接口,当然你也可以自己扩展RejectedExecutionHandler接口,定义自己的拒绝策略,我们看下示例代码:
1 | public class ThreadPool { |
可以看到由于任务加了休眠阻塞,执行需要花费一定时间,导致会有一定的任务被丢弃,从而执行自定义的拒绝策略;
ThreadFactory自定义线程创建
线程池中线程就是通过ThreadPoolExecutor中的ThreadFactory,线程工厂创建的。那么通过自定义ThreadFactory,可以按需要对线程池中创建的线程进行一些特殊的设置,如命名、优先级等,下面代码我们通过ThreadFactory对线程池中创建的线程进行记录与命名
1 | public class ThreadPool { |
ThreadPoolExecutor扩展
ThreadPoolExecutor扩展主要是围绕beforeExecute()、afterExecute()和terminated()三个接口实现的,
1、beforeExecute:线程池中任务运行前执行
2、afterExecute:线程池中任务运行完毕后执行
3、terminated:线程池退出后执行
通过这三个接口我们可以监控每个任务的开始和结束时间,或者其他一些功能。
1 | public class ThreadPool { |
可以看到通过对beforeExecute()、afterExecute()和terminated()的实现,我们对线程池中线程的运行状态进行了监控,在其执行前后输出了相关打印信息。另外使用shutdown方法可以比较安全的关闭线程池, 当线程池调用该方法后,线程池中不再接受后续添加的任务。但是,此时线程池不会立刻退出,直到添加到线程池中的任务都已经处理完成,才会退出。
抽象类(abstract class)和接口(interface)有什么异同?
不同:
抽象类:
1.抽象类中可以定义构造器
2.可以有抽象方法和具体方法
3.接口中的成员全都是public 的
4.抽象类中可以定义成员变量
5.有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法
6.抽象类中可以包含静态方法
7.一个类只能继承一个抽象类
接口:
1.接口中不能定义构造器
2.方法全部都是抽象方法
3.抽象类中的成员可以是 private、默认、protected、public
4.接口中定义的成员变量实际上都是常量
5.接口中不能有静态方法
6.一个类可以实现多个接口
相同:
1.不能够实例化
2.可以将抽象类和接口类型作为引用类型
3.一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍然需要
被声明为抽象类
sleep() 方法和 wait() 方法区别和共同点
- 两者最主要的区别在于:sleep 方法没有释放锁,而 wait 方法释放了锁 。
- 两者都可以暂停线程的执行。
- Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
- wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。或者可以使用 wait(long timeout)超时后线程会自动苏醒。
为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
这是另一个非常经典的 java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结: 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。
Java 为什么能跨平台,实现一次编写,多处运行?
Java 能够跨平台运行的核心在于 JVM 。不是 Java 能够跨平台,而是它的 jvm 能够跨平台。我们知道,不同的操作系统向上的 API 肯定是不同的,那么如果我们想要写一段代码调用系统的声音设备,就需要针对不同系统的 API 写出不同的代码来完成动作。
而 Java 引入了字节码的概念,jvm 只能认识字节码,并将它们解释到系统的 API 调用。针对不同的系统有不同的 jvm 实现,有 Linux 版本的 jvm 实现,也有 Windows 版本的 jvm 实现,但是同一段代码在编译后的字节码是一样的。引用上面的例子,在 Java API 层面,我们调用系统声音设备的代码是唯一的,和系统无关,编译生成的字节码也是唯一的。但是同一段字节码,在不同的 jvm 实现上会映射到不同系统的 API 调用,从而实现代码的不加修改即可跨平台运行。
jvm 的内容模型
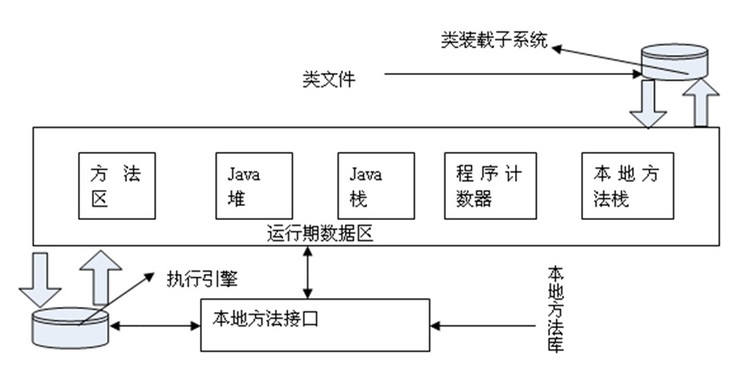
其实JVM内部不仅仅只有栈和堆
包括 程序计数器 、 Java 虚拟机栈 、本地方法栈、Java 堆、方法区等
1. 程序计数器
线程私有,较小的内存空间,如果线程正在执行的是一个Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Natvie 方法,这个计数器值则为空(Undefined)。此内存区域是唯一一个在Java 虚拟机规范中没有规定任何OutOfMemoryError 情况的区域。
2. Java 虚拟机栈(栈区)
线程私有,每个方法被执行的时候都会同时创建一个栈帧用于存储局部变量表、操作栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
3.本地方法栈
与虚拟机栈所发挥的作用是非常相似的,区别不过是虚拟机栈为虚拟机执行Java 方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native 方法服务,有的虚拟机(譬如Sun HotSpot 虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError 和OutOfMemoryError。
4.Java 堆(堆区)
线程共享,此内存区域的唯一目的就是创建并存放对象实例,也是GC区。分代收集算法:内存区大概分为新生代,老年代,永久代。
新生代从Eden区创建,复制到Survivor区(2个 from 和 to)。 GC分为minor GC 和 Full GC 。
minor GC: Eden满了就触发minor GC,minorGC会将Eden区仍然存活的会复制到ToSurvivor,FromSurvivor一部分复制到老年代,一部分复制ToSurvivor,此时原Eden和From的数据清空,from和to互换,这样的过程直到To被填满,复制到老年代。
FullGC:(1)年老代内存不足;(2)持久代内存不足;(3)统计得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间(4)调用System.gc()方法的时候,
5. 方法区(类级/静态)
线程共享,存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它别名叫做Non-Heap(非堆)即“永久代”,不进行GC,只是针对常量池的回收和对类型的卸载 。
运行时常量池:是方法区的一部分,Class常量池存放编译期生成的各种字面量和符号引用,运行时常量池相对于Class 文件常量池的另外一个重要特征是具备动态性,运行期间也可能将新的常量放入池中,这种特性被开发人员利用得比较多的便是String 类的intern() 方法(这个方法会首先检查字符串池中是有”ab”这个字符串,如果存在则返回这个字符串的引用,否则就将这个字符串添加到字符串常量池中,然会返回这个字符串的引用,这可以实现字符串的”= =”比较。new String 不进入常量池,直接赋值会进入常量池)。
new 一个对象的过程和 clone 一个对象的过程区别
new 操作符的本意是分配内存。程序执行到 new 操作符时,首先去看 new 操作符后面的类型,因为知道了类型, 才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完毕,可以把他的引用(地址)发布到外部,在外部就可以使用这个引用操纵这个对 象。 clone 在第一步是和 new 相似的,都是分配内存,调用 clone 方法时,分配的内存和原对象(即调用 clone 方法 的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域,填充完成之后,clone 方法返回,一个新的相同 的对象被创建,同样可以把这个新对象的引用发布到外部。
为什么 Java 中只有值传递
首先回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。按值调用(call by value)表示方法接收的是调用者提供的值,而按引用调用(call by reference)表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。 它用来描述各种程序设计语言(不只是 Java)中方法参数传递方式。
Java 程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。
Java 程序设计语言对对象采用的不是引用调用,实际上,对象引用是按 值传递的。
下面再总结一下 Java 中方法参数的使用情况:
- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)。
- 一个方法可以改变一个对象参数的状态。
- 一个方法不能让对象参数引用一个新的对象。
==与 equals
== : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况 1:类没有覆盖 equals()方法。则通过 equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况 2:类覆盖了 equals()方法。一般,我们都覆盖 equals()方法来两个对象的内容相等;若它们的内容相等,则返回 true(即,认为这两个对象相等)。
说明:
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
hashCode 与 equals
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object.java 中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
hashCode()与 equals()的相关规定
- 如果两个对象相等,则 hashcode 一定也是相同的
- 两个对象相等,对两个对象分别调用 equals 方法都返回 true
- 两个对象有相同的 hashcode 值,它们也不一定是相等的
- 因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
- hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
双亲委托模型
当Java程序需要使用某个类时,如果该类还未被加载到内存中,JVM会通过加载、连接(验证、准备和解析)、初始化三个步骤来对该类进行初始化。
类的加载是指把类的.class文件中的数据读入到内存中,通常是创建一个字节数组读入.class文件,然后产生与所加载类对应的Class对象。加载完成后,Class对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。最后JVM对类进行初始化,包括:
1)如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类;
2)如果类中存在初始化语句,就依次执行这些初始化语句。
类加载器就是寻找类或接口字节码文件进行解析并构造JVM内部对象表示的组件,在java中类装载器把一个类装入JVM,经过以下步骤:
1、加载:查找和导入Class文件
2、链接:其中解析步骤是可以选择的 (a)检查:检查载入的class文件数据的正确性 (b)准备:给类的静态变量分配存储空间 (c)解析:将符号引用转成直接引用
3、初始化:对静态变量,静态代码块执行初始化工作
双亲委派模式要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器,请注意双亲委派模式中的父子关系并非通常所说的类继承关系,而是采用组合关系来复用父类加载器的相关代码,类加载器间的关系如下:
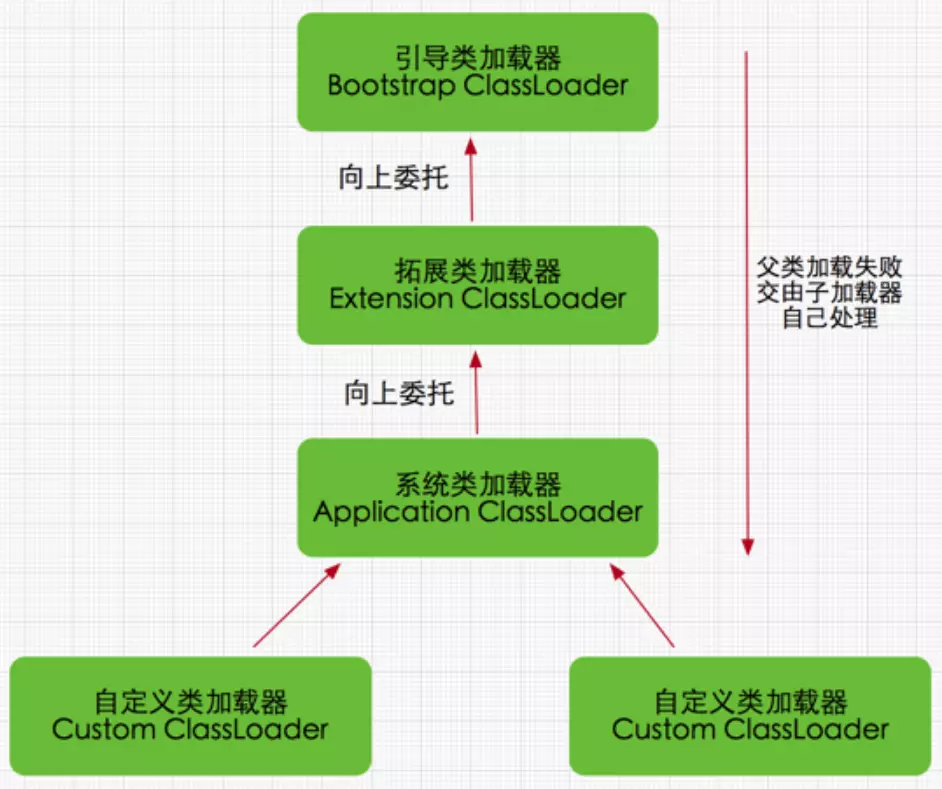
双亲委派模式是在Java 1.2后引入的,其工作原理的是,如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式
双亲委派模式优势
- 采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。
- 其次是考虑到安全因素,java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?
因为 hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode)。
我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
闭包和回调区别
- 闭包是指可以包含自由(未绑定到特定对象)变量的代码块;这些变量不是在这个代码块内或者任何全局上下文中定义的,而是在定义代码块的环境中定义(局部变量)。 —《百度百科》
- 是引用了自由变量的函数。这个函数通常被定义在另一个外部函数中,并且引用了外部函数中的变量。 – <>
- 是一个可调用的对象,它记录了一些信息,这些信息来自于创建它的作用域。– <
闭包能够将一个方法作为一个变量去存储,这个方法有能力去访问所在类的自由变量。
闭包的价值在于可以作为函数对象或者匿名函数,持有上下文数据,作为第一级对象进行传递和保存。闭包广泛用于回调函数、函数式编程中。
在Java中,闭包是 通过“接口与内部类实现的”
通过这种仿闭包的非静态内部类,可以很方便地实现回调功能,回调就是某个方法一旦获得了内部类对象的引用后,就可以在合适时候反过来调用外部类的方法。所谓回调,就是允许客户类通过内部类引用来调用其外部类的方法,这是一种非常灵活的功能。
回调和观察者的区别
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。观察者模式完美的将观察者和被观察的对象分离开,一个对象的状态发生变化时,所有依赖于它的对象都得到通知并自动刷新。
回调函数其实也算是一种观察者模式的实现方式,回调函数实现的观察者和被观察者往往是一对一的依赖关系。
所以最明显的区别是观察者模式是一种设计思路,而回调函数式一种具体的实现方式;另一明显区别是一对多还是多对多的依赖关系方面。
MVP和MVC模式差别
MVC
View:布局的xml文件,或者纯Java写的布局,可以把页面显示的逻辑直接放在View中。
Model:数据处理层,可以直接和View进行交互。
Controller:把特定的功能逻辑抽离出来,作为控制层,保证View层和Model层的功能单一性,便于维护。
MVP
View:Activity作为显示层。
Presenter:逻辑层,从Activity中抽离出功能逻辑,简化Activity的代码。
Model:数据处理层,主要负责网络请求,本地数据加载等操作,进一步简化Activity的代码
1、Presenter与Controller都扮演了逻辑层的角色,但是Presenter层的功能相对更复杂,因为他负责和View的双向交互,Controller只是单向的中介。因为Presenter是从View层抽离出来的,通常和View是一对一的关系,而Controller是面向业务的,往往是单例模式或者提供静态方法。
2、MVP中View和Model是不能进行通信的,虽然加重了P层的负担,但是有利于维护View层和Model层,如果条件允许,我们还可以对Presenter进一步拆分,来弥补Presenter负担过重的问题。
MVC中View和Model层可以直接交互,虽然方便了两者之间的交互,但是耦合性相对较高。
Activity职责不同,Activity在MVP中是View层,在MVC中是Controller层,这是MVC和MVP很主要的一个区别,可以说Android从MVC转向MVP开发也主要是优化Activity的代码,避免Activity的代码臃肿庞大。
- View层不同,MVC的View层指的是XML布局文件或者是用Java自定义的View,MVP的View层是Activity或者Fragment。使用传统的MVC,其中的View,对应的是各种Layout布局文件,但是这些布局文件中并不像Web端那样强大,能做的事情非常有限。MVP的View层Activity在实际项目中,随着逻辑的复杂度越来越大,Activity臃肿的缺点仍然体现出来了,因为Activity中还是充满了大量与View层无关的代码,比如各种事件的处理派发,就如MVC中的那样View层和Controller代码耦合在一起无法自拔。
- 控制层不同,MVC的控制层是Activity,或者是Fragment,Controller对应的是Activity,而Activity中却又具有操作UI的功能,我们在实际的项目中也会有很多UI操作在这一层,也做了很多View中应该做的事情,当然Controller层Activity中也包含Controller应该做的事情,比如各种事件的派发回调,而且在一层中我们会根据事件再去调用Model层操作数据,所以这种MVC的方式在实际项目中,Activity所在的Controller是非常重的,各层次之间的耦合情况也比较严重,不方便单元测试。MVP的控制层是Presenter,里面没有很多的实际东西,主要是做Model和View层的交互。
- 关系链不同,MVP中Model层与View是没有关系的,彼此不会通讯和操作,Model与View的通讯都是Presenter层来传达的。但是在MVC中,Model层和View是曾在交互的。比如我们自定义的View控件里面肯定是要使用Model的数据的,View也要根据不同的Model数据做出不同的展现!这点尤其是体现在自定义的View中,自定义View需要设置数据,用户操作了自定义控件需要改变数据,View要操作Model怎么办?有人说把Controller传到自定义的View啊,现实是不可能没一个自定义View都去持有Controller的引用,其实在MVP中就不会这么尴尬,接口就可以完成。
- 适用范围不同,在Android中,MVP和MVC都用自己的适用情况,使用MVP可以更好的解耦三大模块,模块之间比较清晰,也很方便使用MVP来组件化架构整体项目。但是MVC也是有用武之地的,在组件化的Module或者中间件我们可以使用MVC来做,Module或者中间件不会存在很复杂的View层,使用MVC可以更加方便我们实现功能。
- 交互方式不同,MVP中通讯交互基本都是通过接口的,MVC中的通讯交互很多时候都是实打实的调用对象的方法,简单粗暴!
- 实现方法不同 ,MVC和MVP的Model几乎一样的,都是处理数据,只要不在Activity或者Fragment中请求数据,其他的所有控制都放在Activity或者Fragment中,这样写就基本是MVC的模式,这样写不麻烦,但是很容易把Activity写出上万行代码。用MVP的时候我们需要写很多View和Presenter接口来实现模块之间的通讯,会增加很多类。
(1)相同点:
优点:
1.降低耦合度
2.模块职责划分明显
3.利于测试驱动开发
4.代码复用
5.隐藏数据
6.代码灵活性
缺点:
额外的代码复杂度及学习成本。
(2)不同点:
MVP模式:
1.View不直接与Model交互,而是通过与Presenter交互来与Model间接交互
2.Presenter与View的交互是通过接口来进行的,更有利于添加单元测试
3.通常View与Presenter是一对一的,但复杂的View可能绑定多个Presenter来处理逻辑,业务相似的时候也可以多同个View共享一个Presenter。
MVC模式:
1.View可以与Model直接交互
2.Controller是基于行为的,并且可以被多个View共享
3.Controller可以负责决定显示哪个View
4种引用
https://www.jianshu.com/p/825cca41d962
线程同步方法
volatile、synchronized、Concurrent包中的BlockingQueue、Semaphore。
然后展开讲了一下volatile的原理、底层实现内存屏障、应用、synchronized底层的WaitSet、onDeck、Owner、BlockingQueue。
然后讲了一下BlockingQueue的两种常用形式利用信号量帮助编程人员更轻松使用BlockingQueue。
序列化与反序列化
- 序列化:将对象写入到IO流中
- 反序列化:从IO流中恢复对象
- 意义:序列化机制允许将实现序列化的Java对象转换位字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
- 使用场景:所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method invoke,即远程方法调用),传入的参数或返回的对象都是可序列化的,否则会出错;所有需要保存到磁盘的java对象都必须是可序列化的。通常建议:程序创建的每个JavaBean类都实现Serializeable接口。
如果需要将某个对象保存到磁盘上或者通过网络传输,那么这个类应该实现Serializable接口或者Externalizable接口之一。
Serializable
Serializable接口是一个标记接口,不用实现任何方法。一旦实现了此接口,该类的对象就是可序列化的。
- 序列化步骤:
- 步骤一:创建一个ObjectOutputStream输出流;
- 步骤二:调用ObjectOutputStream对象的writeObject输出可序列化对象。
1 | /** |
- 反序列化步骤:
- 步骤一:创建一个ObjectInputStream输入流;
- 步骤二:调用ObjectInputStream对象的readObject()得到序列化的对象。
1 | /** |
Java序列化同一对象,并不会将此对象序列化多次得到多个对象。
- Java序列化算法
- 所有保存到磁盘的对象都有一个序列化编码号
- 当程序试图序列化一个对象时,会先检查此对象是否已经序列化过,只有此对象从未(在此虚拟机)被序列化过,才会将此对象序列化为字节序列输出。
- 如果此对象已经序列化过,则直接输出编号即可。
由于java序利化算法不会重复序列化同一个对象,只会记录已序列化对象的编号。如果序列化一个可变对象(对象内的内容可更改)后,更改了对象内容,再次序列化,并不会再次将此对象转换为字节序列,而只是保存序列化编号。
有些时候,我们有这样的需求,某些属性不需要序列化。使用transient关键字选择不需要序列化的字段。
使用transient修饰的属性,java序列化时,会忽略掉此字段,所以反序列化出的对象,被transient修饰的属性是默认值。对于引用类型,值是null;基本类型,值是0;boolean类型,值是false。
使用transient虽然简单,但将此属性完全隔离在了序列化之外。java提供了可选的自定义序列化。可以进行控制序列化的方式,或者对序列化数据进行编码加密等。通过重写writeObject与readObject方法,可以自己选择哪些属性需要序列化, 哪些属性不需要。如果writeObject使用某种规则序列化,则相应的readObject需要相反的规则反序列化,以便能正确反序列化出对象。
Externalizable:强制自定义序列化
通过实现Externalizable接口,必须实现writeExternal、readExternal方法。
1 | public interface Externalizable extends java.io.Serializable { |
注意:Externalizable接口不同于Serializable接口,实现此接口必须实现接口中的两个方法实现自定义序列化,这是强制性的;特别之处是必须提供pulic的无参构造器,因为在反序列化的时候需要反射创建对象。
| 实现Serializable接口 | 实现Externalizable接口 |
|---|---|
| 系统自动存储必要的信息 | 程序员决定存储哪些信息 |
| Java内建支持,易于实现,只需要实现该接口即可,无需任何代码支持 | 必须实现接口内的两个方法 |
| 性能略差 | 性能略好 |
虽然Externalizable接口带来了一定的性能提升,但变成复杂度也提高了,所以一般通过实现Serializable接口进行序列化。
总结
- 所有需要网络传输的对象都需要实现序列化接口,通过建议所有的javaBean都实现Serializable接口。
- 对象的类名、实例变量(包括基本类型,数组,对其他对象的引用)都会被序列化;方法、类变量、transient实例变量都不会被序列化。
- 如果想让某个变量不被序列化,使用transient修饰。
- 序列化对象的引用类型成员变量,也必须是可序列化的,否则,会报错。
- 反序列化时必须有序列化对象的class文件。
- 当通过文件、网络来读取序列化后的对象时,必须按照实际写入的顺序读取。
- 单例类序列化,需要重写readResolve()方法;否则会破坏单例原则。
- 同一对象序列化多次,只有第一次序列化为二进制流,以后都只是保存序列化编号,不会重复序列化。
- 建议所有可序列化的类加上serialVersionUID 版本号,方便项目升级。
JAVA中各种锁机制
https://www.cnblogs.com/jyroy/p/11365935.html
JAVA异常机制
https://www.cnblogs.com/yc211/p/9910949.html
JAVA类加载
加载
加载是类加载过程的一个阶段,这两个概念一定不要混淆。在加载阶段, 虚拟机需要完成以下三件事情:
1)通过一个类的全限定名来获取定义此类的二进制字节流。
2 )将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
3 ) 将类的class文件读入内存,并为之创建一个java.lang.Class对象,也就是说当程序中使用任何类时,系统都会为之建立一个java.lang.Class对象, 作为方法区这个类的各种数据的访问入口。
通过使用不同的类加载器,可以从不同来源加载类的二进制数据,通常有如下几种来源:
- 从本地文件系统加载class文件;
- 从一个ZIP、 JAR、 CAB或者其他某种归档文件中提取Java class文件,JDBC编程时使用到的数据库驱动就是放在JAR文件中,JVM可以直接从JAR包中加载class文件;
- 通过网络加载class文件,这种场景最典型的应用就是 Applet;
- 把一个java源文件动态编译、并执行加载
- 运行时计算生成, 这种场景使用得最多的就是动态代理接术, 在 java.lang.reflect.Proxy中 , 就是用了 ProxyGenerator.generateProxyClass来为特定接口生成形式为“*$Proxy”的代理类的二进制字节流。
连接
当类被加载后,系统为之生成一个对应的Class对象,接着会进入连接阶段,连接阶段将会负责把类的二进制文件合并到JRE中。类连接分为如下三个阶段:
- 验证:验证阶段用于检验被加载的类是否有正确的内部结构,并和其他类协调一致;
- 准备:准备阶段则负责为类的静态属性分配内存,并设置默认初始值;
- 解析:将类的二进制数据中的符号引用替换成直接引用(符号引用是用一组符号描述所引用的目标;直接引用是指向目标的指针)
验证
验证是连接阶段的第一步, 这一阶段的目的是为了确保 Class文件的字节流中包含的信息符合当前虚拟机的要求, 井且不会危害虚拟机自身的安全。
Java语言本身是相对安全的语言,但前面已经说过, Class文件并不一定要求用 Java源码编译而来, 可以使用任何途径, 包括用十六进制编译器直接编写来产生 Class 文件。在字节码的语言层面上, 上述 Java代码无法做到的事情都是可以实现的, 至少语义上是可以表达出来的。虚拟机如果不检査输入的字节流,对其完全信任的话, 很可能会因为载入了有害的字节流而导致系统崩溃 , 所以验证是虚拟机对自身保护的一项重要工作。从整体上看,验证阶段会完成下面四个阶段的检验过程: 文件格式验证、 元数据验证、 字节码验证、符号引用验证。
1、文件格式验证
第一阶段要验证字节流是否符合 Class文件格式的规范, 井且能被当前版本的虚拟机处理。这一阶段可能包括下面这些验证点:
- 是否以魔数 0xCAFEBABE开头
- 主、次版本号是否在当前虚拟机处理范围之内 。
- 常量池的常量中是否有不被支持的常量类型(检査常量tag 标志)。
- 指向常量的各种索引值中是否有指向不存在的常量或不符合装型的常量 。
- CONSTANT_Utf8_info型的常量中是否有不符合 UTF8编码的数据
- Class 文件中各个部分及文件本身是否有被删除的或附加的其他信息
实际上第一阶段的验证点还远不止这些, 上面这些只是从 HotSpot虚拟机源码中摘抄的一小部分而已。只有通过了这个阶段的验证之后, 字节流才会进入内存的方法区中进行存储, 所以后面的三个验证阶段全部是基于方法区的存储结构进行的,不会再直接操作字节流。
2、元数据验证
第二阶段是对字节码描述的信息进行语义分析,以保证其描述的信息符合Java语言规范的要求,这个阶段可能包括的验证点如下:
这个类是否有父类(除了 java.lang.0bject之外,所有的类都应当有父类)
这个类的父类是否继承了不允许被继承的类(被finaI修饰的类)
如果这个类不是抽象类, 是否实現了其父类或接口之中要求实现的所有方法
类中的字段、 方法是否与父类产生了矛盾(例如覆盖了父类的final字段, 或者出現不符合规则的方法重载, 例如方法参数都一致, 但返回值类型却不同等)
第二阶段的验证点同样远不止这些,这一阶段的主要目的是对类的元数据信息进行语义检验, 保证不存在不符合 Java语言规范的元数据信息。
3、字节码验证
第三阶段是整个验证过程中最复杂的一个阶段, 主要目的是通过数据流和控制流的分析,确定语义是合法的。符号逻辑的。在第二阶段对元数据信息中的数据类型做完校验后,这阶段将对类的方法体进行校验分析,保证被校验类的方法在运行时不会做出危害虚拟机安全的行为,例如:
- 保证任意时刻操作数栈的数据装型与指令代码序列都能配合工作, 例如不会出现类似这样的情况:在操作栈中放置了一个 int类型的数据, 使用时却按long类型来加载入本地变量表中。
- 保证跳转指令不会跳转到方法体以外的字节码指令上
- 保证方法体中的类型转换是有效的, 例如可以把一个子类对象赋值给父类数据装型,这是安全的,但是把父类对象意赋值给子类数据类型,甚至把对象赋值给与它毫无继承关系、 完全不相干的一个数据类型, 则是危险和不合法的。
即使一个方法体通过了字节码验证, 也不能说明其一定就是安全的。
4、符号引用验证
最后一个阶段的校验发生在虚拟机将符号引用转化为直接引用的时候 , 这个转化动作将在连接的第三个阶段——解析阶段中发生。符号引用验证可以看做是对类自身以外(常量池中的各种符号引用) 的信息进行匹配性的校验, 通常需要校验以下内容:
- 符号引用中通过字将串描述的全限定名是否能找到对应的类
- 在指定类中是否存在符合方法的字段描述符以及简单名称所描述的方法和字段 。
- 符号引用中的类、字段和方法的访问性(private、 protected、 public、 default)是否可被当前类访问
符号引用验证的目的是确保解析动作能正常执行, 如果无法通过符号引用验证, 将会抛出一个 java.lang.IncompatibleClassChangError异常的子类, 如 java.lang.IllegalAccessError、 java.lang.NoSuchFieldError、java.lang.NoSuchMethodError等。
对于虚拟机的装加载机制来说 ,验证阶段是一个非常重要的、 但不一定是必要的阶段(因为对程序没有影响)。如果所运行的全部代码(包括自己编写的以及第三方包中的代码)都已经被反复使用和验证过 , 那么在实施阶段就可以考虑使用一Xverify;none 参数来关闭大部分的验证措施, 以缩短虚拟机类加载的时间。
准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些变量所使用的内存都将在方法区中进行分配 。这个阶段中有两个容易产生混淆的概念需要强调一下, 首先,这时候进行内存分配的仅包括类变量(被static修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在 Java 堆中 。 其次,这里所说的初始值“通常情况”下是数据类型的零值。
解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程, 解新动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行,分别对应于常量池的CONSTANT_Class_info、 CONSTANT_Fieldref_info、CONSTANT_Methodref_info、CONSTANT_IntrfaceMethodref_info、CONSTANT_MethodType_info、CONSTANT_MethodHandle_info和CONSTANT_InvokeDynamic_info7种常量类型,解析阶段中所说的直接引用与符号引用关系如下:
- 符号引用(Symlxiuc References):符号引用以一组符号来描述所引用的日标,符号可以是任何形式的字面量, 只要使用时能无歧义地定位到目标即可, 特号引用与配組机实现的内存1布.局11i-美 , 引用的日标并不一定已组加裁到内存中
- 直接引用(Direct References):直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是与虚拟机实现的内存布局相关的 , 同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同. 如果有了直接引用, 那引用的目标必定已经在内存中存在
初始化
初始化阶段是类加载过程的最后一步 , 前面的几个阶段, 除了在加载阶段用户应用程序可以通过自定 义类加载器參与之外, 其余动作完全由虚拟机主导和控制。到了初始化阶段, 才真正开始执行类中定义的 Java程序代码。从代码角度,初始化阶段是执行类构造器
()方法是由编译器自动收集类中的所有类变量的赋值动作和静志语句块(static{}块)中的语句合并产生的, 编译器收集的顺序是由语句在源文件中出现的顺序所决定的, 静态语句块中只能访问到定义在静态语句块之前的变量, 定义在它之后的変量 , 在前面的静态语句块可以赋值 , 但是不能访问 ()方法与类的构造函数 (或者说实例构造器 ()方法)不同,它不需要显式地调用父类构造器, 虚期机会保证在子类的 ()方法执行之前, 父类的 ()方法已经执行完毕, 因此在虚期机中第一个被执行的 ()方法的类肯定是 java,lang.Object - 由于父类的
()方法先执行,也就意味着父类中定义的静态语句块要优先于子类的变量赋值操作 ()方法对于类或接口来说并不是必须的, 如果一个类中没有静态语句块,也没有对变量的赋值操作, 那么编译器可以不为这个类生成 ()方法 - 接口中不能使用静态语句块,但仍然有变量初始化的赋值操作, 因此接口与类一样都会生成
()方法。 但接口与类不同的是, 执行接口的 ()方法不需要先执行父接口的 ()方法。只有当父接口中定义的变量被使用时, 父接口才会被初始化。 另外, 接口的实现类在初始化时也一样不会执行接口的 ()方法 - 虚拟机会保证一个类的
()方法在多线程环境中被正确地加锁和同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的 ()法,其他线程部需要阻塞等待,直到活动线程执行 ()方法完毕。如果在一个类的 ()方法中有耗时很长的操作, 那就可能造成多个进程阻塞, 在实际应用中这种阻塞往往是隐蔽的。
类的初始化阶段主要是对类变量进行初始化,在Java类中对类变量指定初始值有两种方式:
- 声明类变量时指定初始值
- 使用静态初始化块为类变量指定初始值
JVM初始化一个类一般包括如下几个步骤:
- 假如这个类还没有被加载和连接,程序先加载并连接该类;
- 假如该类的直接父类还没有被初始化,则先初始化其直接父类;
- 假如类中有初始化语句,则系统依次执行这些初始化语句
当执行第二步时,系统对直接父类的初始化也遵循此1、2、3步骤,如果该直接父类又有直接父类,系统再次重复这三步,所以JVM最先初始化的总是java.lang.Object类。
synchronized
https://blog.csdn.net/javazejian/article/details/72828483
synchronized锁释放有两种机制,一种就是执行完释放;另外一种就是发送异常,虚拟机释放。图中第二个monitorexit就是发生异常时执行的流程,这就是我开头说的“会有2个流程存在“。
synchronized 和 lock的区别
| 类别 | synchronized | Lock |
|---|---|---|
| 存在层次 | Java的关键字,在jvm层面上 | 是一个类 |
| 锁的释放 | 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁 | 在finally中必须释放锁,不然容易造成线程死锁 |
| 锁的获取 | 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待 | 分情况而定,Lock有多个锁获取的方式,具体下面会说道,大致就是可以尝试获得锁,线程可以不用一直等待 |
| 锁状态 | 无法判断 | 可以判断 |
| 锁类型 | 可重入 不可中断 非公平 | 可重入 可判断 可公平(两者皆可) |
| 性能 | 少量同步 | 大量同步 |
Lock支持的功能:
- 公平锁:Synchronized是非公平锁,Lock支持公平锁,默认非公平锁
- 可中断锁:ReentrantLock提供了lockInterruptibly()的功能,可以中断争夺锁的操作,抢锁的时候会check是否被中断,中断直接抛出异常,退出抢锁。而Synchronized只有抢锁的过程,不可干预,直到抢到锁以后,才可以编码控制锁的释放。
- 快速反馈锁:ReentrantLock提供了trylock() 和 trylock(tryTimes)的功能,不等待或者限定时间等待获取锁,更灵活。可以避免死锁的发生。
- 读写锁:ReentrantReadWriteLock类实现了读写锁的功能,类似于Mysql,锁自身维护一个计数器,读锁可以并发的获取,写锁只能独占。而synchronized全是独占锁
- Condition:ReentrantLock提供了比Sync更精准的线程调度工具,Condition,一个lock可以有多个Condition,比如在生产消费的业务下,一个锁通过控制生产Condition和消费Condition精准控制。
copyonwritelist的原理
CopyOnWriteArrayList是Java并发包中提供的一个并发容器,它是个线程安全且读操作无锁的ArrayList,写操作则通过创建底层数组的新副本来实现,是一种读写分离的并发策略,我们也可以称这种容器为”写时复制器”,Java并发包中类似的容器还有CopyOnWriteSet。
我们都知道,集合框架中的ArrayList是非线程安全的,Vector虽是线程安全的,但由于简单粗暴的锁同步机制,性能较差。而CopyOnWriteArrayList则提供了另一种不同的并发处理策略(当然是针对特定的并发场景)。
很多时候,我们的系统应对的都是读多写少的并发场景。CopyOnWriteArrayList容器允许并发读,读操作是无锁的,性能较高。至于写操作,比如向容器中添加一个元素,则首先将当前容器复制一份,然后在新副本上执行写操作,结束之后再将原容器的引用指向新容器。
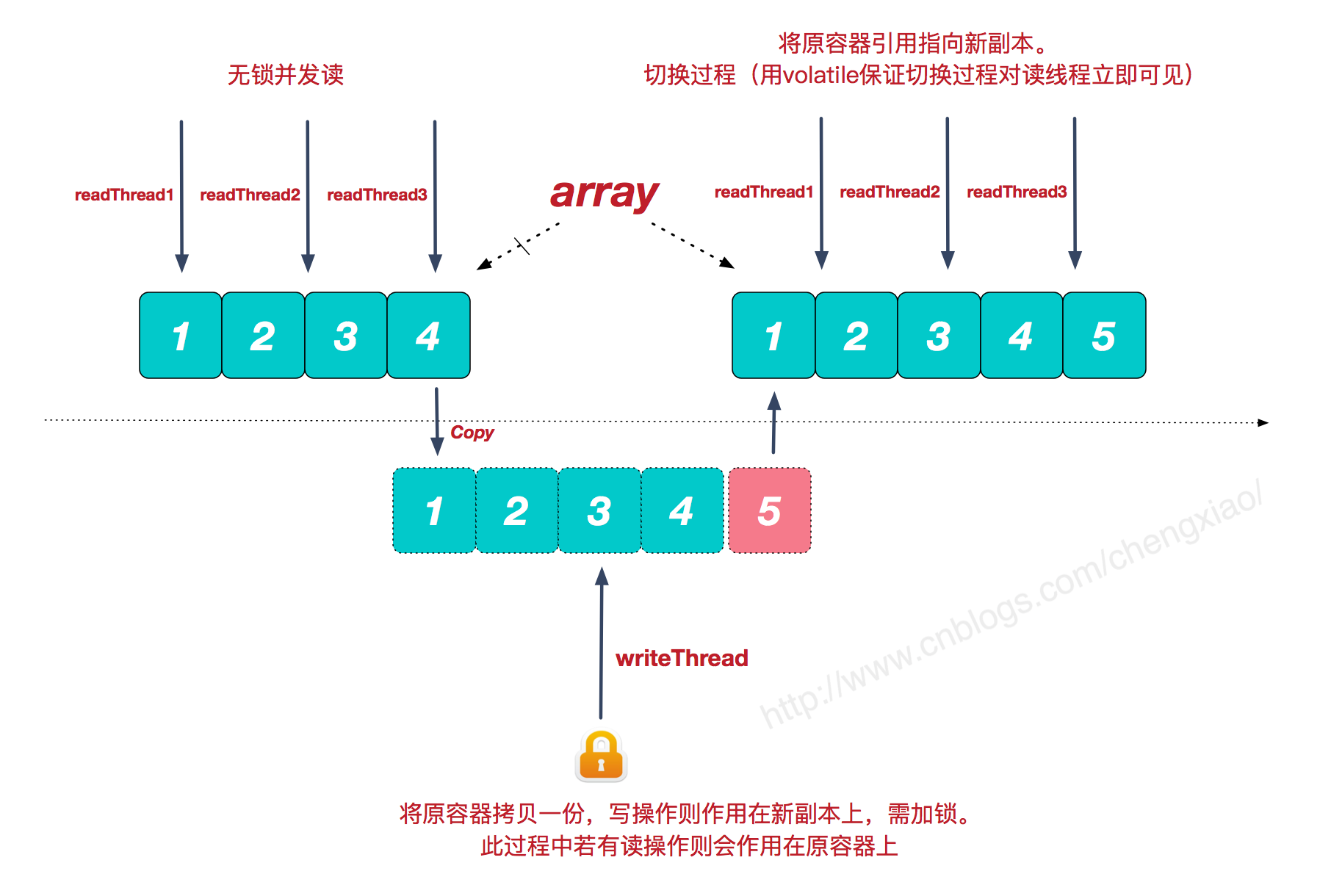
优缺点分析
了解了CopyOnWriteArrayList的实现原理,分析它的优缺点及使用场景就很容易了。
优点:
读操作性能很高,因为无需任何同步措施,比较适用于读多写少的并发场景。Java的list在遍历时,若中途有别的线程对list容器进行修改,则会抛出ConcurrentModificationException异常。而CopyOnWriteArrayList由于其”读写分离”的思想,遍历和修改操作分别作用在不同的list容器,所以在使用迭代器进行遍历时候,也就不会抛出ConcurrentModificationException异常了
缺点:
缺点也很明显,一是内存占用问题,毕竟每次执行写操作都要将原容器拷贝一份,数据量大时,对内存压力较大,可能会引起频繁GC;二是无法保证实时性,Vector对于读写操作均加锁同步,可以保证读和写的强一致性。而CopyOnWriteArrayList由于其实现策略的原因,写和读分别作用在新老不同容器上,在写操作执行过程中,读不会阻塞但读取到的却是老容器的数据。
1 | public boolean add(E e) { |
添加的逻辑很简单,先将原容器copy一份,然后在新副本上执行写操作,之后再切换引用。当然此过程是要加锁的。
1 | public E remove(int index) { |
删除操作同理,将除要删除元素之外的其他元素拷贝到新副本中,然后切换引用,将原容器引用指向新副本。同属写操作,需要加锁。
1 | public E get(int index) { |
G1 GC
http://ghoulich.xninja.org/2018/01/27/understanding-g1-garbage-collector-in-java/
Android
Activty生命周期
活动在系统中被活动堆栈管理。当一个新的活动开始时,将会强加于堆栈的顶端并成为运行活动状态。而之前的活动总是被放置在这个活动下面的堆栈中,并且不会被移动到前台直到新的活动退出为止。
活动从开始到结束经历各种状态。从一个状态到另一个状态的转变,从无到有再到无,这样一个过程中所经历的各个状态就叫做生命周期。Activity拥有自己的生命周期,而它的意义就在于,当我们对当前的界面进行展示的过程中,本身也会经历各个阶段去准备和处理当前的activity,然后展示给用户,而开发者为了界面上一些炫酷的效果与功能,做一些特殊处理时,就离不开这些生命周期。
关于activity的四个状态:
running-poused-stopped-killed
- running->当前显示在屏幕的activity(位于任务栈的顶部),用户可见状态。
- poused->依旧在用户可见状态,但是界面焦点已经失去,此Activity无法与用户进行交互。
- stopped->用户看不到当前界面,也无法与用户进行交互 完全被覆盖.
- killed->当前界面被销毁,等待这系统被回收
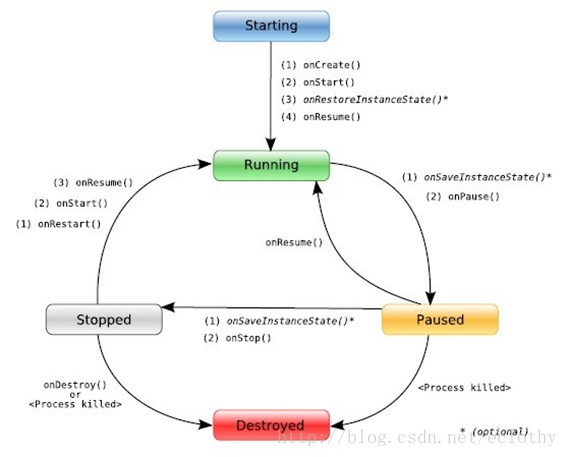
由上图我们得知:
Starting ——–>Running 所执行的生命周期顺序 onCreate()->onstart()->onResume()
当前称为活动状态(Running),此activity所处于任务栈的top中,可以与用户进行交互。
Running ——>Paused 所执行Activity生命周期中的onPause()
当前称为暂停状态(Paused),该Activity已失去了焦点但仍然是可见的状态(包括部分可见)。
Paused ——>Running所执行的生命周期为:OnResume()
当前重新回到活动状态(Running),此情况用户操作home键,然后重新回到当前activity界面发生。
Paused ——>Stoped所执行的生命周期为:onStop()
该Activity被另一个Activity完全覆盖的状态,该Activity变得不可见,所以系统经常会由于内存不足而将该Activity强行结束。
Stoped——>killed所执行的生命周期为:onDestroy()
该Activity被系统销毁。当一个Activity处于暂停状态或停止状态时就随处可能进入死亡状态,因为系统可能因内存不足而强行结束该Activity。
注:还有一种情况由于系统内存不足可能在Paused状态中直接被系统杀死达到killed状态。
activity的生命周期
oncreate()->onstart()->onResume()->onRestart()->onPouse()->onStop()->onDestory()
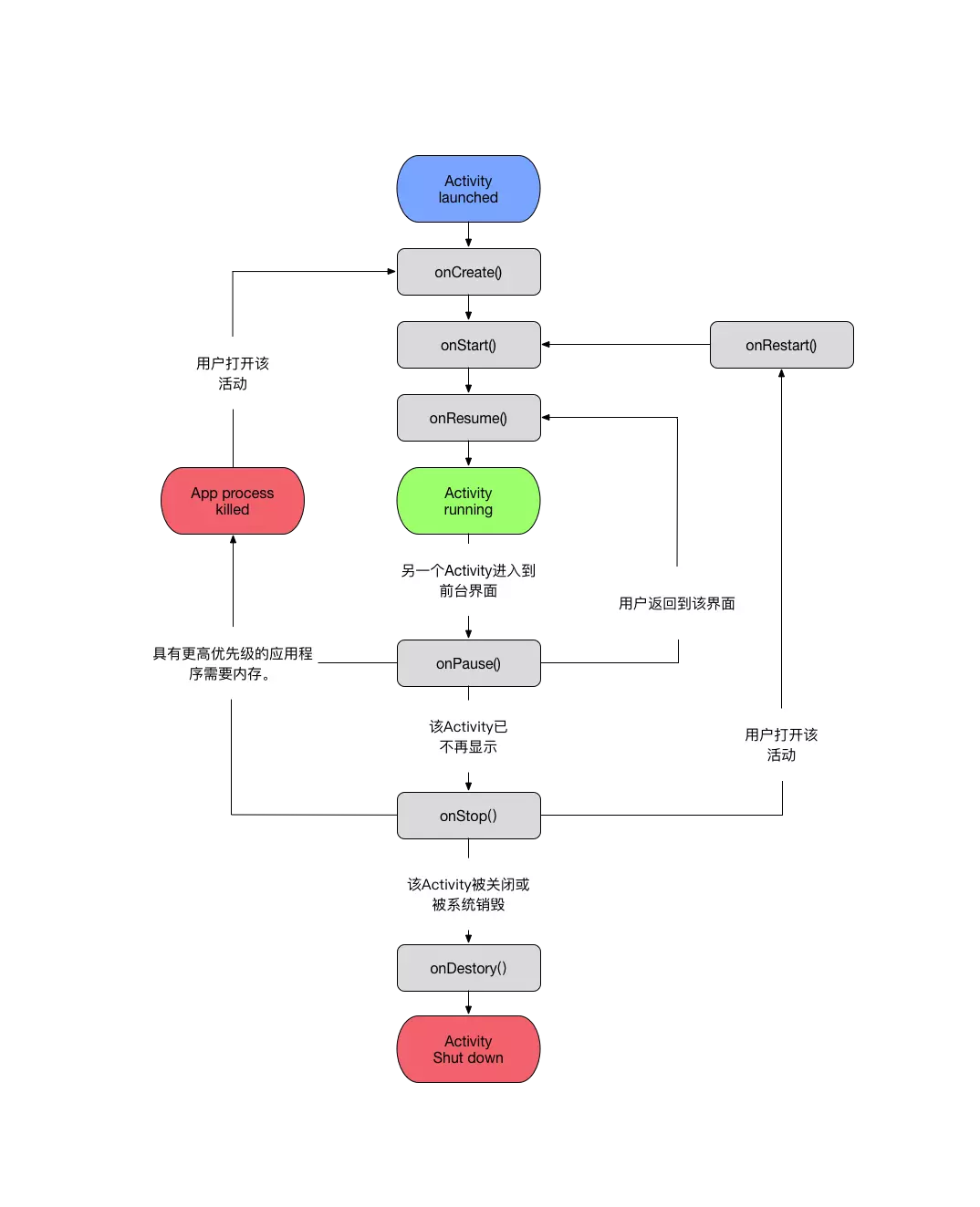
onCreate():
当我们点击activity的时候,系统会调用activity的oncreate()方法,在这个方法中我们会初始化当前布局setContentLayout()方法。
onStart():
onCreate()方法完成后,此时activity进入onStart()方法,当前activity是用户可见状态,但没有焦点,与用户不能交互,一般可在当前方法做一些动画的初始化操作。
onResume():
onStart()方法完成之后,此时activity进入onResume()方法中,当前activity状态属于运行状态 (Running),可与用户进行交互。
onPause()
当另外一个activity覆盖当前的acitivty时,此时当前activity会进入到onPause()方法中,当前activity是可见的,但不能与用户交互状态。
onStop()
onPouse()方法完成之后,此时activity进入onStop()方法,此时activity对用户是不可见的,在系统内存紧张的情况下,有可能会被系统进行回收。所以一般在当前方法可做资源回收。
onDestory()
onStop()方法完成之后,此时activity进入到onDestory()方法中,结束当前activity。
onRestart()
onRestart()方法在用户按下home()之后,再次进入到当前activity的时候调用。调用顺序onPouse()->onStop()->onRestart()->onStart()->onResume().
onSaveInstanceState(Bundle outState):
onSaveInstanceState函数在Activity生命周期中执行。
outState 参数作用 :
数据保存 : Activity 声明周期结束的时候, 需要保存 Activity 状态的时候, 会将要保存的数据使用键值对的形式 保存在 Bundle 对象中;
调用时机 :
Activity 被销毁的时候调用, 也可能没有销毁就调用了;
按下Home键 : Activity 进入了后台, 此时会调用该方法;
按下电源键 : 屏幕关闭, Activity 进入后台;
启动其它 Activity : Activity 被压入了任务栈的栈底;
横竖屏切换 : 会销毁当前 Activity 并重新创建;
onSaveInstanceState方法调用注意事项 :
用户主动销毁不会调用 : 当用户点击回退键 或者 调用了 finish() 方法, 不会调用该方法;
调用时机不固定 : 该方法一定是在 onStop() 方法之前调用, 但是不确定是在 onPause() 方法之前 还是 之后调用;
布局中组件状态存储 : 每个组件都 实现了 onSaveInstance() 方法, 在调用函数的时候, 会自动保存组件的状态, 注意, 只有有 id 的组件才会保存;
关于默认的 super.onSaveInstanceState(outState) : 该默认的方法是实现 组件状态保存的;
onRestoreInstanceState(Bundle outState):
方法回调时机 : 在 Activity 被系统销毁之后 恢复 Activity 时被调用, 只有销毁了之后重建的时候才调用, 如果内存充足, 系统没有销毁这个 Activity, 就不需要调用;
– Bundle 对象传递 : 该方法保存的 Bundle 对象在 Activity 恢复的时候也会通过参数传递到 onCreate() 方法中;
activity的进程优先级。
前台进程>可见进程>service进程>后台进程>空进程
fragmengt生命周期
Fragment是可以让你的app纵享丝滑的设计,如果你的app想在现在基础上性能大幅度提高,并且占用内存降低,同样的界面Activity占用内存比Fragment要多,响应速度Fragment比Activty在中低端手机上快了很多,甚至能达到好几倍!如果你的app当前或以后有移植平板等平台时,可以让你节省大量时间和精力。
Fragment表示 Activity 中的行为或用户界面部分。您可以将多个片段(片段就是指 Fragment )组合在一个 Activity 中来构建多窗格 UI,以及在多个 Activity 中重复使用某个片段。您可以将片段视为 Activity 的模块化组成部分,它具有自己的生命周期,能接收自己的输入事件,并且您可以在 Activity 运行时添加或移除片段(有点像您可以在不同 Activity 中重复使用的“子 Activity”)。
片段必须始终嵌入在 Activity 中,其生命周期直接受宿主 Activity 生命周期的影响。 例如,当 Activity 暂停时,其中的所有片段也会暂停;当 Activity 被销毁时,所有片段也会被销毁。
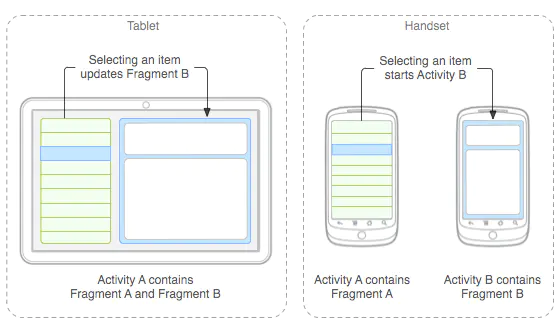
当您将片段作为 Activity 布局的一部分添加时,它存在于 Activity 视图层次结构的某个 ViewGroup 内部,并且片段会定义其自己的视图布局。您可以通过在 Activity 的布局文件中声明片段,将其作为 `` 元素插入您的 Activity 布局中,即静态添加。或者通过将其添加到某个现有 ViewGroup,利用应用代码进行动态插入。不过,片段并非必须成为 Activity 布局的一部分;您还可以将没有自己 UI 的片段用作 Activity 的不可见工作线程。
下图是文档中给出的一个Fragment分别对应手机与平板间不同情况的处理图:
Fragment 生命周期
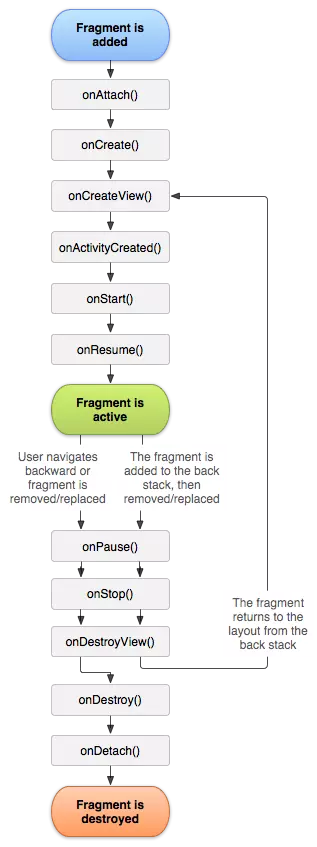
可以看到 Fragment 的生命周期和 Activity 很相似,只是多了一下几个方法:
onAttach() 在Fragment 和 Activity 建立关联是调用(Activity 传递到此方法内)
onCreateView() 当Fragment 创建视图时调用
onActivityCreated() 在相关联的 Activity 的 onCreate() 方法已返回时调用。
onDestroyView() 当Fragment中的视图被移除时调用
onDetach() 当Fragment 和 Activity 取消关联时调用。
可以看下几种操作情况下Fragment 的生命周期变化

管理 Fragment 生命周期和 Activity 生命周期很相似,同时 Activity 的生命周期对 Fragment 的生命周期也有一定的影响,如下图所示
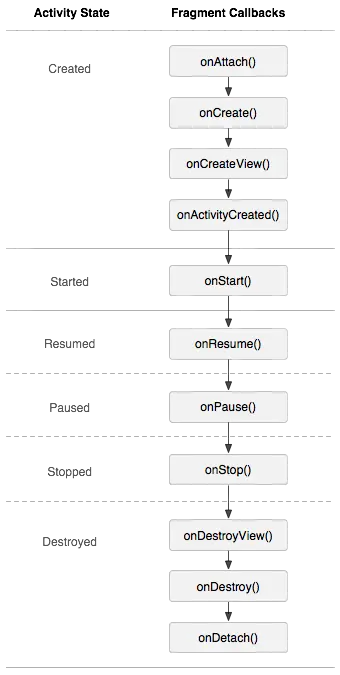
用下图(来源)来表示 Activity 和 Fragment 的生命周期变化的先后过程是:

Activity 和 Fragment 生命周期执行过程
Fragment 生命周期与 Activity 生命周期的一个关键区别就在于,Fragment 的生命周期方法是由托管Activity而不是操作系统调用的。Activity 中生命周期方法都是 protected,而 Fragment 都是 public,也能印证了这一点,因为 Activity 需要调用 Fragment 那些方法并管理它。
加载 Fragment
- 静态加载
- 动态加载
静态加载 在 Activity 的布局文件内声明片段,其中 fragment 中的 android:name 属性要指定 fragment 对应的具体包名路径,当系统创建此 Activity 布局时,会实例化在布局中指定的每个 fragment,并为每个 fragment 调用 onCreateView()方法,以检索每个 fragment 的布局。系统会直接插入 fragment 返回的 View 来替代 fragment 元素。
并且在 Activity 活动里可以直接使用 findViewById() 方法获取 fragment 对应布局里的控件。同样在 fragment 里可以直接使用 getActivity()方法获得绑定的主 Activity 实例,并调用 Activity 里的方法或其他 fragment 实例。
动态加载 通过编程方式将 fragment 添加到某个activity布局里现有的 ViewGroup (例如 LinearLayout 或 FrameLayout)里。
要想在 Avtivity 中执行 Fragment 事务 (如添加、删除或替换 Fragment),必须使用 FragmentTransaction 中的 API。可以使用下面这样从 Activity 中获取一个 FragmentTransaction。1
2FragmentManager fragmentManager = getFragmentManager();
FragmentTransaction fragmentTransaction = fragmentManager.beginTransaction();然后可以使用 add()方法添加一个 fragment ,指定要添加的 fragment 和插入到哪个视图。例如
1 | ExampleFragment exampleFragment = new ExampleFragment(); |
add 方法中第一个参数是一个activity 对应布局文件中的 ViewGroup,即应该放置 fragment 的位置,由资源 ID 指定,第二个参数是加入的 fragment ,一旦通过 fragmentTransaction 做了更改,最后必须使用 commit 方法以使更改生效。
在 Activity 中使用 Fragment 可以很方便的进行添加 add、替换 replace、移除 remove 等操作,这样提交给 Activity 的每组更改都可以称为事务。像上边动态添加 fragment 那样,使用 FragmentTransaction 里的 API 就可以执行一项事务。同时也可以将此事务保存到 Activity 管理的返回栈中,从而用户可以回退到 fragment 改变之前的状态(类似于 activity 回退到上一个页面)。
Fragment 与 Activity 通信
上边说过,在 fragment 中可以调用 getActivity() 获取 activity 的实例并调用 activity 里的方法和布局,同样在 activity 里也可以通过 findFragmentById()(对于在 activity 提供 fragment 布局的) 或 findFragmentByTag() (对于在 activity 提供或者不提供 fragment 布局的)方法获取 fragment 的实例,例如在 activity 中从 FragmentManager 获取对 Fragment 的引用来调用 fragment 中的方法:
1 | Fragment fragment = getFragmentManager.findFragmentById(R.id.fragment_container); |
使用 FragmentManager 还可以执行的操作包括:
- 通过 findFragmentById 或 findFragmentByTag 获取 activity 中存在的 fragment 的实例
- 通过 popBackStack (模拟用户点击返回按钮操作)将 fragment 从返回栈中弹出
- 通过 addOnBackStackChangedListener() 注册一个监听返回栈改变的监听器
- 像上边生成 fragmentTransaction 的方法,可以使用 fragmentManager 生成一个 fragmentTransaction 来执行某些事务,比如添加、替换、移除、addToBackStack()等。
Activity中View的生命周期方法回调
Activity有生命周期,同样的,View从添加到界面到从界面中移除也有一个生命周期,在官方文档中介绍了自定义View需要重写的一些方法,可以认为这些方法就是View的生命周期方法。
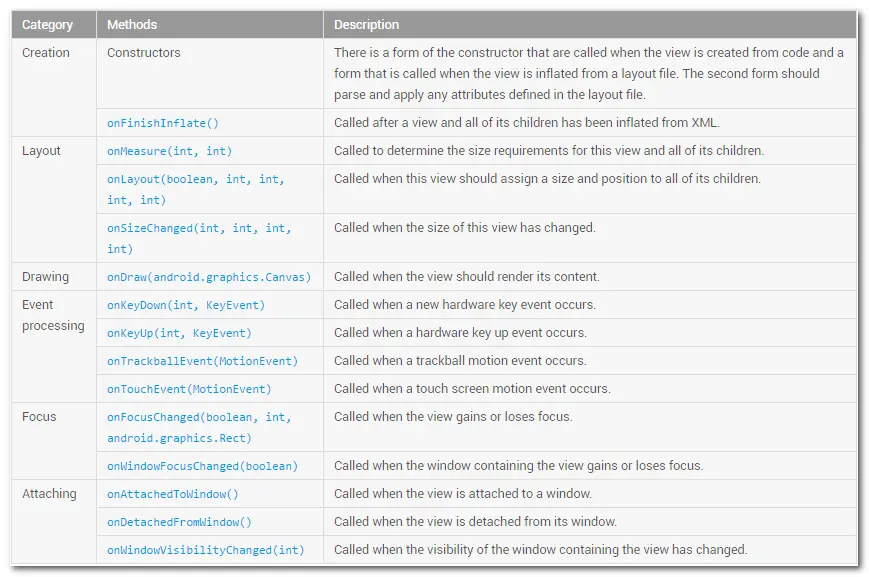
从Activity启动到退出,这个View 的过程是这样的。
在Activity的onCreate()方法中调用setContentView方法,Activity显示到界面时的View的回调
- 构造方法,这是肯定的,View也是一个Java类。
- onFinishInflate,这个一般是通过LayoutInflater进行填充的时候会走这个方法。如果我们是直接在代码中new出来的View进行添加,是不会走这个方法的。
- onAttachedToWindow,这个方法表明现在这个View已经跟它对应的Window已经绑定了
- onWindowVisibilitChanged(int visibility) ,这个值等于 View.VISIBLE,代表View所在的Window已经可见了。
- onMeasure,开始测量。我们发现,这个measure过程是在Window可见的情况下才会去调用了,仔细想想这个也不难理解,如果你都不准备显示,我何必去花精力测量你呢。这个测量过程可能会多次调用。
- onSizeChanged ,测量之后会回调这个方法。onSizeChanged,顾名思义就是当尺寸发生变化的时候会调用。一般是第一次测量之后调用,后面再测量,如果尺寸没变化就不会再去调用了。
- onLayout,测量时候就进行布局,这个时候如果是View的话一般不用去管,因为具体放在哪个位置是由父控件去控制的,如果是ViewGroup,就需要去确定子View的位置。
- onDraw,确定完位置和宽高,就可以进行绘制了。
- onWindowFocusChanged(boolean hasWindowFocus),为true这个说明View所绑定的Window开始获取焦点
当按back键退出当前Activity后,走下面几个方法
- onWindowVisibilitChanged(int visibility) ,这个值等于 View.GONE,此时Window已经不可见了
- onWindowFocusChanged(boolean hasWindowFocus),这个也变为false,说明已经没有焦点了。有一点比较奇怪,为什么是先不可见才是没有焦点的呢?
- onDetachedFromWindow, 当前View与它对应的Window解除绑定。
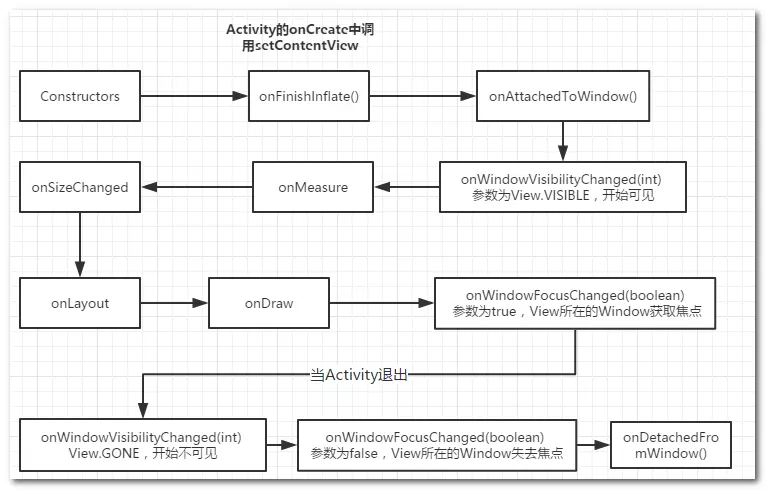
结合与Activity的启动过程可以看到
- Activity 调用onCreate方法,这个时候我们setContentView加载了带View的布局
- Activity 调用onWindowAttributesChanged 方法,而且这个方法连续调用多次
View调用构造方法View调用onFinishInflate方法,说明这个时候View已经填充完毕,但是这个时候还没开始触发绘制过程- Activity 调用onstart方法
- Activity 再次调用 onWindowAttributesChanged 方法,说明这个方法在onResume之前会多次调用
- Activity 调用onResume,我们一般认为当Activity调用onResume的时候,整个Activit已经可以和用户进行交互了,但事实上可能并不是这样,后面解释原因。
- Activity 调用onAttachedToWindow,说明跟Window进行了绑定。发现了吗,Activity在onResume之后才跟Window进行了绑定。
View调用onAttachedToWindow,View开始跟Window进行绑定,这个过程肯定是在Activity绑定之后才进行的。View调用 onWindowVisibilityChanged(int visibility),参数变为View.VISIABLE,说明Window已经可见了,这个时候我们发现一个问题就是其实onResume的时候似乎并不代表Activity中的View已经可见了。View调用onMeasure,开始测量View调用onSizeChanged,表示测量完成,尺寸发生了变化View调用onLayout,开始摆放位置View调用 onDraw,开始绘制- Activity 调用onWindowFocusChanged(boolean hasFocus),此时为true,代表窗体已经获取了焦点
View调用 onWindowFocusChanged(boolean hasWindowFocus),此时为true,代表当前的控件获取了Window焦点,当调用这个方法后说明当前Activity中的View才是真正的可见了。
当退出当前的Activity的时候
- Activity 调用 onPause
View调用 onWindowVisibilityChanged(int visibility),参数变为View.GONE,View中对应的Window隐藏- Activity 调用onWindowFocusChanged(boolean hasFocus),此时为false,说明Actvity所在的Window已经失去焦点
- Activity 调用 onStop,此时Activity已经切换到后台
- Activity 调用 onDestory,此时Activity开始准备销毁,实际上调用onDestory并不代表Activity已经销毁了。
View调用 onDetachedFromWindow,此时View 与Window解除绑定- Activity 调用 onDetathedFromWindow ,此时Activity 与Window 解除绑定
当View进行与Window解除绑定之后,View即将被销毁。我们可以在 View 的 onDetachedFromWindow 方法中可以做一些资源的释放,防止内存泄漏。
android进程间通信
| 名称 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Bundle | 简单易用 | 只能传输Bundle支持的数据类型 | 四大组件间的进程间通信 |
| 文件共享 | 简单易用 | 不适用高并发场景,并且无法做到进程间即时通信 | 适用于无关发的情况下,交换简单的数据,对实时性要求不高的场景。 |
| AIDL | 功能强大,支持一对多实时并发通信 | 使用稍复杂,需要处理好线程间的关系 | 一对多通信且有RPC需求 |
| Messenger | 功能一般,支持一对多串行通信,支持实时通信 | 不能很好地处理高并发的情形,不支持RPC,由于数据通过Message传输,因此只能传输Bundle支持的数据类型 | 低并发的一对多实时通信,无RPC需求,或者无需要返回结果的RPC需求 |
| ContentProvider | 支持一对多的实时并发通信,在数据源共享方面功能强大,可通过Call方法扩展其它操作 | 可以理解为受约束的AIDL,主要提供对数据源的CRUD操作 | 一对多的进程间数据共享 |
| BroadcastReceiver | 操作简单,对持一对多实时通信 | 只支持数据单向传递,效率低且安全性不高 | 一对多的低频率单向通信 |
| Socket | 功能强大,可通过网络传输字节流,支持一对多实时并发通信 | 实现细节步骤稍繁琐,不支持直接的RPC | 网络间的数据交换 |
Android中PX、DP、SP的区别
px
Pixels 我们看到屏幕上的图像由一个个像素组成,像素里包含色彩信息。
如常说的手机分辨率:1080 x 1920 指的是手机宽度可展示1080像素,高度可展示1920像素。
ppi
Pixels Per Inch 每英寸长度所具有的像素个数,单位面积内像素越多,图像显示越清晰。
ppi一般用在显示器、手机、平板等描述屏幕精细度。
dpi
Dots Per Inch 每英寸长度所具有的点数。
dpi一般用来描述打印(书本、杂志、电报)的精细度
dp/dip
density-independent pixels (device-independent pixels 我查了一下,官网更多时候使用前者,有的时候也显示后者),dip是缩写,也可以更简单些称作dp。该单位的目的是屏蔽不同设备密度差异,后面细说。
sp
Scalable pixels 用于设置字体,在用户更改字体大小时候会适配。
Android系统使用dpi来描述屏幕的密度,使用dp来描述密度与像素的关系。
A设备dpi=240
B设备dpi=420
Android系统最终识别的单位是px,怎么将dpi和px关联起来呢?,答案是dp。
Android规定当dpi=160时,1dp=1px,当dpi=240时,1dp=1.5px,依此类推,并且给各个范围的dpi取了简易的名字加以直观的识别,如120<dpi<=160,称作为mdpi,120<dpi<=240 称作hdpi,最终形成如下规则:
ldpi(value <= 120 dpi)
mdpi(120 dpi < value <= 160 dpi)
hdpi(160 dpi < value <= 240 dpi)
xhdpi(240 dpi < value <= 320 dpi)
xxhdpi(320 dpi < value <= 480 dpi)
xxxhdpi(480 dpi < value <= 640 dpi)
现在知道了dp能够在不同dpi设备上对应不同px,相当于中间转换层,我们只需要将view长宽单位设置为合适的dp,就无需关注设备之间密度差异,系统会帮我们完成dp-px转换。
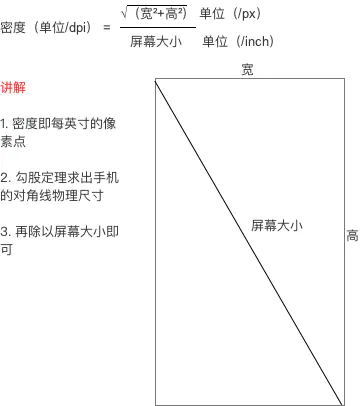
1 | private static final float scale = mContext.getResources().getDisplayMetrics().density; |
点击应用图标以后的流程
Instrumentation: 监控应用与系统相关的交互行为。
ActivityManagerService(AMS):组件管理调度中心,什么都不干,但是什么都管。
ActivityStarter:Activity启动的控制器,处理Intent与Flag对Activity启动的影响,具体说来有:1 寻找符合启动条件的Activity,如果有多个,让用户选择;2 校验启动参数的合法性;3 返回int参数,代表Activity是否启动成功。
ActivityStackSupervisior:这个类的作用你从它的名字就可以看出来,它用来管理任务栈。
ActivityStack:用来管理任务栈里的Activity。
ActivityThread:在Android中它就代表了Android的主线程,注意是代表而不是说它就是一个Thread类,它是创建完新进程之后(肯定是在
一个线程中啊),main函数被加载,然后执行一个loop的循环使当前线程进入消息循环,并且作为主线程。
ApplicationThread:最终干活的人,是ActivityThread的内部类,也是一个Binder对象。在此处它是作为IApplicationThread对象的server端等待client端的请求然后进行处理,最大的client就是AMS.Activity、Service、BroadcastReceiver的启动、切换、调度等各种操作都在这个类里完成。
注意:这里单独提一下ActivityStackSupervisior,这是高版本才有的类,它用来管理多个ActivityStack,早期的版本只有一个ActivityStack对应着手机屏幕,后来高版本支持多屏以后,就有了多个ActivityStack,于是就引入了ActivityStackSupervisior用来管理多个ActivityStack。
整个流程主要涉及四个进程:
- 调用者进程,如果是在桌面启动应用就是Launcher应用进程。
- ActivityManagerService等所在的System Server进程,该进程主要运行着系统服务组件。
- Zygote进程,该进程主要用来fork新进程。
- 新启动的应用进程,该进程就是用来承载应用运行的进程了,它也是应用的主线程(新创建的进程就是主线程),处理组件生命周期、界面绘制等相关事情。
整个流程如下
- 点击桌面应用图标,Launcher进程将启动Activity(MainActivity)的请求以Binder的方式发送给了AMS。
- AMS接收到启动请求后,交付ActivityStarter处理Intent和Flag等信息,然后再交给ActivityStackSupervisior/ActivityStack处理Activity进栈相关流程。同时以Socket方式请求Zygote进程fork新进程。
- Zygote接收到新进程创建请求后fork出新进程。
- 在新进程里创建ActivityThread对象,新创建的进程就是应用的主线程,在主线程里开启Looper消息循环,开始处理创建Activity。ActivityThread利用ClassLoader去加载Activity、创建Activity实例,并回调Activity的onCreate()方法。这样便完成了Activity的启动。
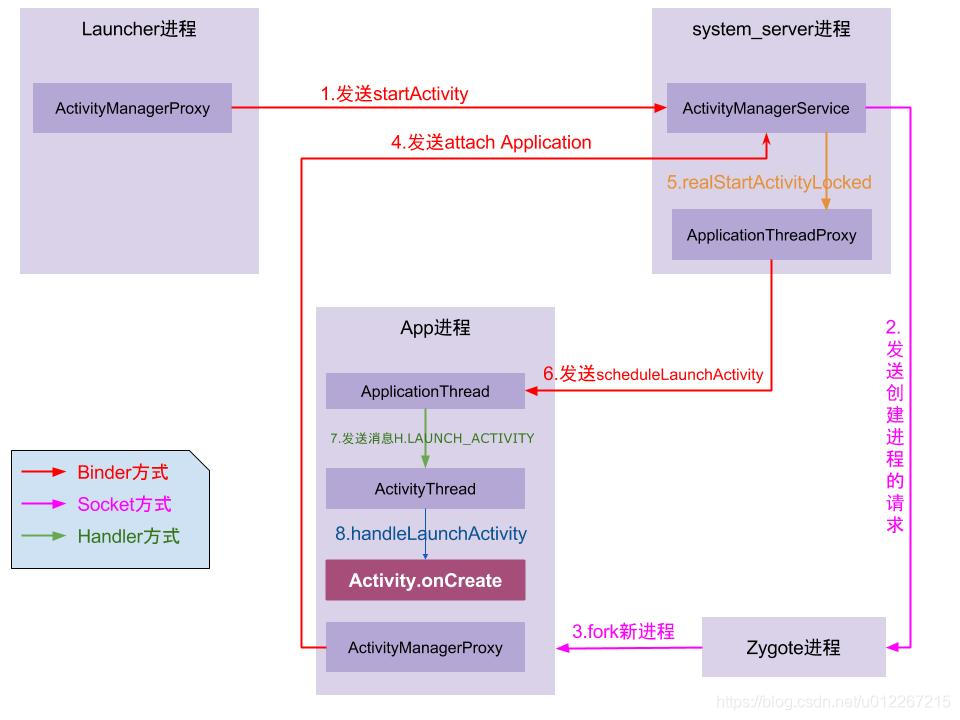
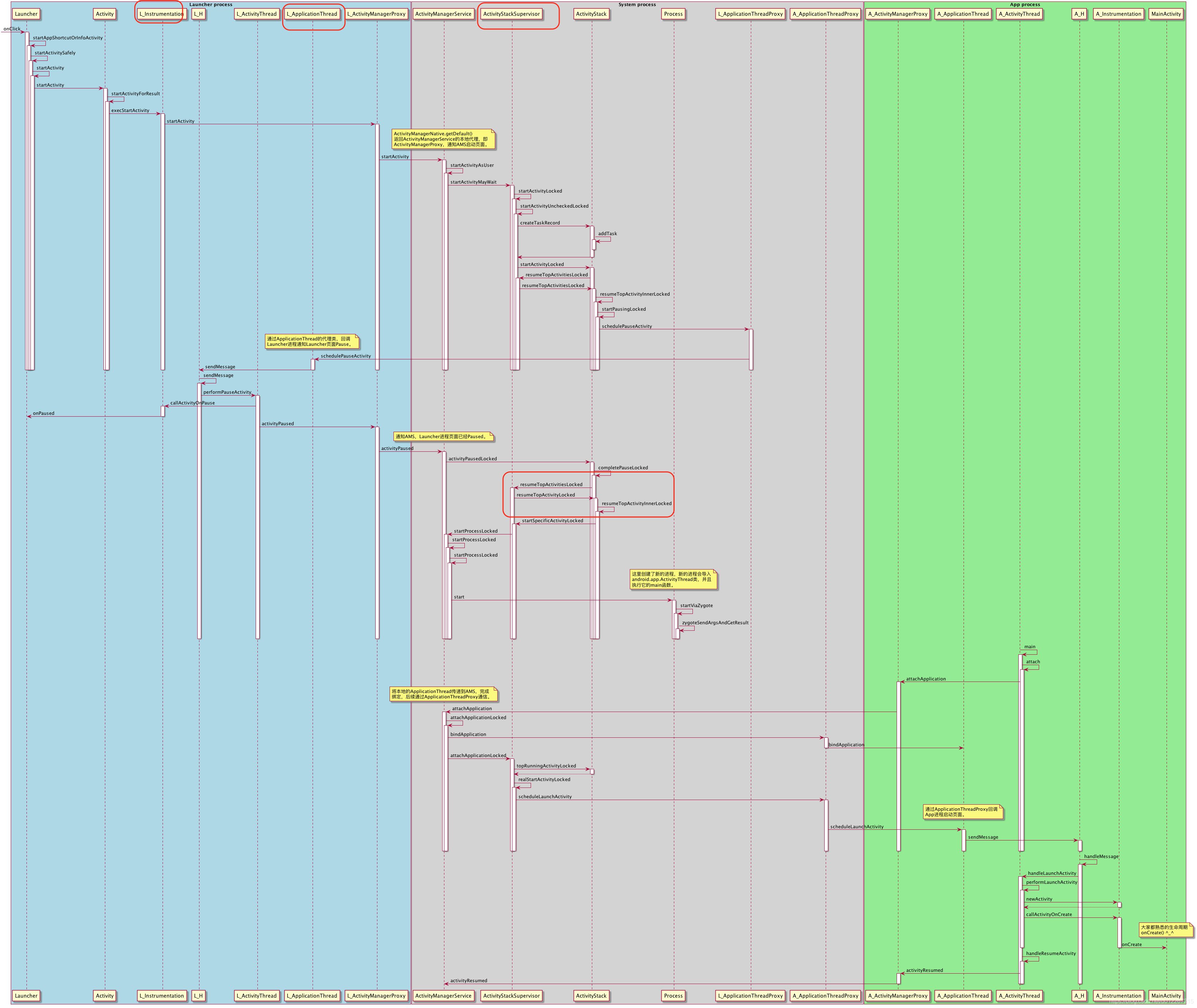
Launcher:Launcher通知AMS要启动activity。
startActivitySafely->startActivity->Instrumentation.execStartActivity()(AMP.startActivity)->AMS.startActivity
AMS:PMS的resoveIntent验证要启动activity是否匹配。
如果匹配,通过ApplicationThread发消息给Launcher所在的主线程,暂停当前Activity(Launcher);
暂停完,在该activity还不可见时,通知AMS,根据要启动的Activity配置ActivityStack。然后判断要启动的Activity进程是否存在?
存在:发送消息LAUNCH_ACTIVITY给需要启动的Activity主线程,执行handleLaunchActivity
不存在:通过socket向zygote请求创建进程。进程启动后,ActivityThread.attach
判断Application是否存在,若不存在,通过LoadApk.makeApplication创建一个。在主线程中通过thread.attach方法来关联ApplicationThread。
在通过ActivityStackSupervisor来获取当前需要显示的ActivityStack。
继续通过ApplicationThread来发送消息给主线程的Handler来启动Activity(handleLaunchActivity)。
handleLauchActivity:调用了performLauchActivity,里边Instrumentation生成了新的activity对象,继续调用activity生命周期。
AMS
https://www.cnblogs.com/ganchuanpu/p/8384471.html
activity与service通信
为何要进行Secvice和Activity的通信?
常用的服务一般是普通服务,即是不可交互的后台服务,该服务在活动中启动,但是启动之后,活动基本就和服务没有什么关系了。确实如此,我们在普通服务里是用startService()方法来启动Service这个服务的,之后服务会一直处于运行状态,但具体运行的是什么逻辑,活动控制不了,活动并不知道服务到底做了什么,完成的如何。
但是在很多场景下,活动是需要和服务进行交互的,比如音乐播放界面,用户可以根据播放进度条掌握播放的进度,用户也可以自己根据歌词的进度选择调整整首歌的进度。
要实现上面所示的功能,就要选择服务的另外一种类型——*可交互的后台服务。以最常见的后台下载,前台显示的操作为例。实现这个功能的思路是创建一个专门的Binder类来对下载进行管理。
https://blog.csdn.net/weixin_41101173/article/details/79718718
WebView
https://www.jianshu.com/p/3c94ae673e2a
WebView是android中一个非常重要的控件,它的作用是用来展示一个web页面。它使用的内核是webkit引擎,4.4版本之后,直接使用Chrome作为内置网页浏览器。
作用:
- 显示和渲染网页;
- 可与页面JavaScript交互,实现混合开发。
加载页面一般有以下几种形式:
1 | //方式一:加载一个网页 |
其中,方式一和方式二比较好理解,方式三可能有些朋友不明白,我在这里解释一下。
WebView.loadData()和WebView.loadDataWithBaseURL()是表示加载某一段代码,其中,WebView.loadDataWithBaseURL()兼容性更好,适用场景更多,因此,我着重介绍一下这个方法。
WebView.loadDataWithBaseURL(String baseUrl, String data, String mimeType, String encoding, String historyUrl))的五个参数:baseUrl表示基础的网页,data表示要加载的内容,mimeType表示加载网页的类型,encoding表示编码格式,historyUrl表示可用历史记录,可以为null值。
举个例子:
1 | String body = "示例:这里有个img标签,地址是相对路径<img src='/uploads/allimg/130923/1FP02V7-0.png' />"; |
WebView的生命周期一般跟随Activity:
1 |
|
https://www.jianshu.com/p/3e0136c9e748
Service
https://blog.csdn.net/weixin_41101173/article/details/79684183
Activity启动模式
在实际的项目中我们应该根据特定的需求为每个活动指定恰当的启动模式。
启动模式一共有4种。standard、singleTop、singleTask和singleInstance
通过在AndroidManifest.xml中给android:launchMode属性来选择启动模式。
standard
默认模式,可以不用写配置。在这个模式下,都会默认创建一个新的实例。因此,在这种模式下,可以有多个相同的实例,也允许多个相同Activity叠加。
在该模式下,每当启动一个新活动,它就会在返回栈中入栈,并处于栈顶的位置,并且,不管此活动是否已经存在于返回栈中,每次启动都会创建该活动的一个新实例。
例如:
若我有一个Activity名为A1, 上面有一个按钮可跳转到A1。那么如果我点击按钮,便会新启一个Activity A1叠在刚才的A1之上,再点击,又会再新启一个在它之上……
点back键会依照栈顺序依次退出。
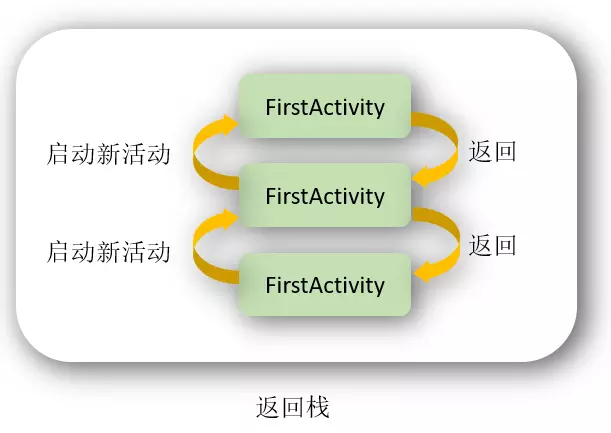
singleTop
可以有多个实例,但是不允许多个相同Activity叠加。即,如果Activity在栈顶的时候,启动相同的Activity,不会创建新的实例,而会调用其onNewIntent方法。不过当FirstActivity并未处于栈顶时,若再启动FirstActivity还是会创建新的实例。
例如:
若我有两个Activity名为B1,B2,两个Activity内容功能完全相同,都有两个按钮可以跳到B1或者B2,唯一不同的是B1为standard,B2为singleTop。
若我意图打开的顺序为B1->B2->B2,则实际打开的顺序为B1->B2(后一次意图打开B2,实际只调用了前一个的onNewIntent方法)
若我意图打开的顺序为B1->B2->B1->B2,则实际打开的顺序与意图的一致,为B1->B2->B1->B2。
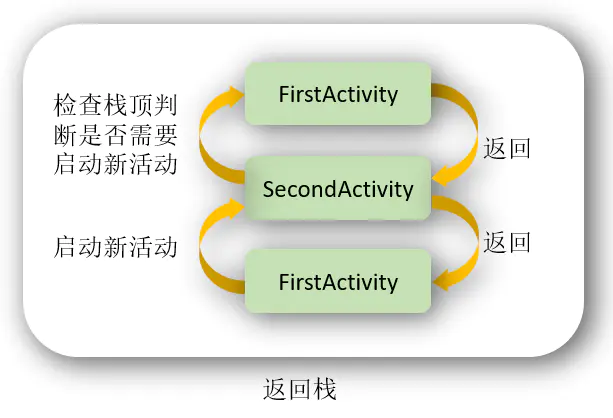
singleTask
使用 single Top模式可以很好地解决重复创建栈顶活动的问题,但是如你在上一节所看到的,如果该活动并没有处于栈顶的位置,还是可能会创建多个活动实例的。那么有没有什么办法可以让某个活动在整个应用程序的上下文中只存在一个实例呢?这就要借助 singleTask模式来实现了。当活动的启动模式指定为 singleTask,每次启动该活动时系统首先会在返回栈中检查是否存在该活动的实例,如果发现已经存在则直接使用该实例,并把在这个活动之上的所有活动统统出栈,如果没有发现就会创建一个新的活动实例。
只有一个实例。在同一个应用程序中启动他的时候,若Activity不存在,则会在当前task创建一个新的实例,若存在,则会把task中在其之上的其它Activity destory掉并调用它的onNewIntent方法。
如果是在别的应用程序中启动它,则会新建一个task,并在该task中启动这个Activity,singleTask允许别的Activity与其在一个task中共存,也就是说,如果我在这个singleTask的实例中再打开新的Activity,这个新的Activity还是会在singleTask的实例的task中。
例如:
若我的应用程序中有三个Activity,C1,C2,C3,三个Activity可互相启动,其中C2为singleTask模式,那么,无论我在这个程序中如何点击启动,如:C1->C2->C3->C2->C3->C1-C2,C1,C3可能存在多个实例,但是C2只会存在一个,并且这三个Activity都在同一个task里面。
但是C1->C2->C3->C2->C3->C1-C2,这样的操作过程实际应该是如下这样的,因为singleTask会把task中在其之上的其它Activity destory掉。
操作:C1->C2 C1->C2->C3 C1->C2->C3->C2 C1->C2->C3->C2->C3->C1 C1->C2->C3->C2->C3->C1-C2
实际:C1->C2 C1->C2->C3 C1->C2 C1->C2->C3->C1 C1->C2
若是别的应用程序打开C2,则会新启一个task。
如别的应用Other中有一个activity,taskId为200,从它打开C2,则C2的taskIdI不会为200,例如C2的taskId为201,那么再从C2打开C1、C3,则C2、C3的taskId仍为201。
注意:如果此时你点击home,然后再打开Other,发现这时显示的肯定会是Other应用中的内容,而不会是我们应用中的C1 C2 C3中的其中一个。
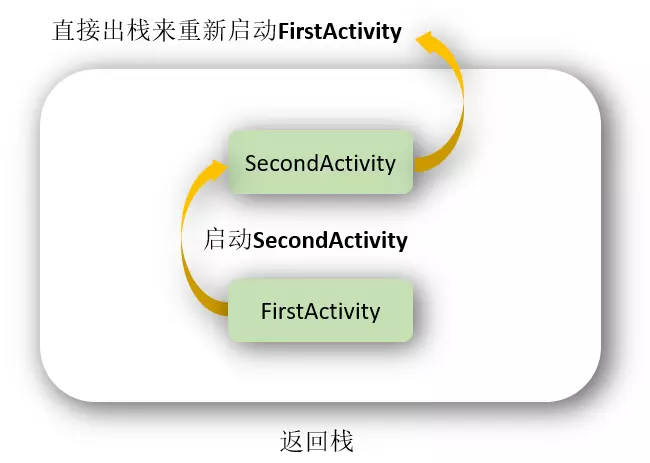
singleInstance
singleInstance模式算是4种启动模式中最复杂的一个了,不同于以上三种模式,该模式下活动会启用一个新的返回栈来管理这个活动(其实如果singleTask模式指定了不同的taskAffinity,也会启动一个新的返回栈)。
那么这样做有什么意义呢?想象以下场景,假设我们的程序中有一个活动是允许其他程序调用的,如果我们想实现其他程序和我们的程序可以共享这个活动的实例,应该如何实现呢?使用前面3种启动模式肯定是做不到的,因为每个应用程序都会有自己的返回栈,同一个活动在不同的返回栈中入栈时必然是创建了新的实例。而使用singlelnstance模式就可以解决这个问题,在这种模式下会有一个单独的返回栈来管理这个活动,不管是哪个应用程序来访问这个活动,都共用的同一个返回栈,也就解决了共享活动实例的问题。
只有一个实例,并且这个实例独立运行在一个task中,这个task只有这个实例,不允许有别的Activity存在。
例如:
程序有三个ActivityD1,D2,D3,三个Activity可互相启动,其中D2为singleInstance模式。那么程序从D1开始运行,假设D1的taskId为200,那么从D1启动D2时,D2会新启动一个task,即D2与D1不在一个task中运行。假设D2的taskId为201,再从D2启动D3时,D3的taskId为200,也就是说它被压到了D1启动的任务栈中。
若是在别的应用程序打开D2,假设Other的taskId为200,打开D2,D2会新建一个task运行,假设它的taskId为201,那么如果这时再从D2启动D1或者D3,则又会再创建一个task,因此,若操作步骤为other->D2->D1,这过程就涉及到了3个task了。
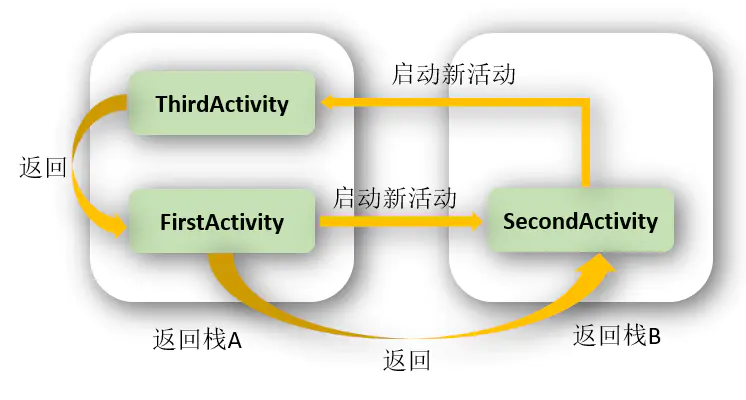
触摸事件分发机制
手机屏幕我们可以称为一个窗口,也就是一个window,在android中这个window类是一个抽象类,它规定了一些管理窗口的方法,但是具体实现是由它的唯一实现类phonewindow去实现的,这样phonewindow就是整个屏幕的实际“掌控者”,而phonewindow又是通过它的内部类decorview去对view进行管理;
接下来进行流程分析,我们就以点击事件为例:
当用户点击了屏幕,首先Activity先监测到,事件先传递到Activity中,Activity通过它的dispatchTouchEvent将事件分发到phoneWindow,phonewindow则会调用superdispatchTouchEvent方法的内部是调用了其内部类DecorView的superdispatchTouchEvent,而DecorView又会调用dispatchTouchEvent去进行事件分发,如果不拦截事件,那么就会继续下传到rootview,rootview中的操作是一样的,同样在dispatchTouchEvent内部调用onInterceptTouchEvent去判断是否拦截,不拦截就会把事件分发给下一个viewgroupA,拦截就直接在onTouchEvent返回true,viewgroupA中做的判断也是一样,最后事件传递到view1,view1是最底层控件,不会有onInterceptTouchEvent,它的选择就只有处理后不处理,处理就在onTouchEvent进行处理并返回true,不处理的话事件也不会被销毁,view1这时会把事件回传,经过上述流程后回传给activity,如果Activity还不处理,那么这个事件才会被销毁;
- Android中的控件都是直接或者间接继承View的,Viewgroup也是继承View的,ViewGroup中可以包含View,也可以包含ViewGroup,我们平时接触的譬如说LinearLayout啊、RelativeLayout就是ViewGroup的子类。
- Android的事件分发机制我有看过它的源码,总的来说就是Android中触摸事件的传递都是先传递到ViewGroup,再传递到View的。我就举Button点击这个例子来讲解一下Android中触摸事件分发的大致流程吧。
- 当点击Button的时候,会调用这个控件所在布局的dispatchTouchEvent(),然后在这个布局中dispatchTouchEvent()方法中找到被点击控件的dispatchTouchEvent()方法。
- 在调用被点击控件的dispatchTouchEvent()方法之前会有一次触摸事件的拦截判断,如果触摸事件被拦截了,就不会再去执行被点击控件的dispatchTouchEvent函数了,也就不会再执行onClick点击事件了。而是执行ViewGroup控件中的dispatchTouchEvent()的onTouch触摸事件然后返回。
- 如果触摸事件没被拦截的话又是怎么做呢,就会ViewGroup中dispatchTouchEvent()方法中被点击控件的dispatchTouchEvent()方法,就不会执行ViewGroup中的onTouch方法了。
- 以上只是阐述了touch事件在ViewGroup中和View中的事件分发过程,但是具体得在一个View中的touch事件分发机制又是怎么样的呢,我们继续往下看
- android里面当触摸到任何一个控件的时候就一定会调用这个控件的dispatchTouchEvent方法。dispatchTouchEvent方法中的源码首先会调用onTouch方法,不过这个方法要执行的话也需要有两个前提条件,一个是这个控件注册了触摸监听、第二个是这个控件的状态要是enabled的。
- 执行完onTouch方法之后,会有一个返回值,如果返回这为true的话代表这个点击事件不继续往下传递了,为false的话就表示点击事件继续往下传递,就会执行onTouchEvent方法,onClick方法就是在onTouchEvent中被调用的。
- 这样的话一个控件的触摸事件在ViewGroup以及View中的分发过程就完成了。
handler机制,多个handler怎么确定哪个handler处理哪个Message
一、Handler是什么?
Handler在我们android开发中是一项非常重要的机制,那Handler是什么呢?Handler是android提供用于更新UI的一套机制,也是消息处理机制。
https://blog.csdn.net/qq_30379689/article/details/53394061
Handler的主要作用有两个:
(1).在新启动的线程中发送消息
(2).在主线程中获取,处理消息。
解释:(1) 当应用程序启动时,Android首先会开启一个主线程 (也就是UI线程) , 主线程为管理界面中的UI控件, 进行事件分发, 比如说, 你要是点击一个 Button ,Android会分发事件到Button上,来响应你的操作。 主线程(UI线程)就是android程序从启动运行到最后的程序。
(2) 如果此时需要一个耗时的操作,例如: 联网读取数据,或者读取本地较大的一个文件的时候,你不能把这些操作放在主线程中,如果你放在主线程中的话,界面会出现假死现象, 如果5秒钟还没有完成的话,会收到Android系统的一个错误提示 “强制关闭”。
(3)这个时候我们需要把这些耗时的操作,放在一个子线程中,因为子线程涉及到UI更新,Android主线程是线程不安全的, 也就是说,更新UI只能在主线程中更新,子线程中操作是危险的。
(4)这个时候,Handler就出现了。来解决这个复杂的问题 ,由于Handler运行在主线程中(UI线程中), 它与子线程可以通过Message对象来传递数据, 这个时候,Handler就承担着接受子线程传过来的(子线程用sendMessage()方法传递)Message对象(里面包含数据) , 把这些消息放入主线程队列中,配合主线程进行更新UI。
二、为什么要用Handler
如果我们不用Handler去发送消息,更新UI可以吗?
答案是不行的。 Android在设计的时候,就封装了一套消息创建,传递,处理机制,如果不遵循这样的机制,就没有办法更新UI信息的,就会抛出异常信息。
抛出异常的描述:不能在非UI线程中去更新UI
三、 Handler怎么用
handler可以分发Message对象和Runnable对象到主线程中,每个Handler实例,都会绑定到创建他的线程中(一般是位于主程),它有两个作用:
(1)合理调度安排消息和runnable对象,使它们在将来的某个点被执行
(2)安排一个动作在不同的线程中执行
Handler中开启线程和分发消息的一些方法:
post(Runnable)直接开启Runnable线程
postAtTime(Runnable,long)在指定的时间long,开始启动线程
postDelayed(Runnable long)在延迟long时间后,启动Runnable线程
sendEmptyMessage(int) 发送指定的消息,通过参数int**来区分不同的消息
sendMessage(Message)发送消息到UI线程中
sendMessageAtTime(Message,long) 这个long代表的是系统时间,不推荐用
sendMessageDelayed(Message,long) 此方法long代表调用后几秒后执行。
sendMessage类方法, 允许你安排一个带数据的Message对象到队列中,等待更新.
handler基本使用: 1)在主线程中,使用handler很简单,new一个Handler对象实现其handleMessage方法,在 handleMessage 中提供收到消息后相应的处理方法即可。(接收消息,并且更新UI)
2)在新启动的线程中发送消息
示例:
1 | public class HandlerActivity extends AppCompatActivity { |
handler运行机制:
Handler机制也可叫异步消息机制,它主要由4个部分组成:Message,Handler,MessageQueue,Looper,在上面图中我们已经有了大致印象,接下来我们对4个成员进行着重的了解:
1.Message
Message是在线程之间传递的消息,它可以在内部携带少量的信息,用于在不同线程之间交换数据。使用Message的arg1和arg2便可携带int数据,使用obj便可携带Object类型数据。
2.Handler
Handler顾名思义就是处理者的意思,它只要用于在子线程发送消息对象Message,在UI线程处理消息对象Message,在子线程调用sendMessage方法发送消息对象Message,而发送的消息经过一系列地辗转之后最终会被传递到Handler的handleMessage方法中,最终在handleMessage方法中消息对象Message被处理。
3.MessageQueue
MessageQueue就是消息队列的意思,它只要用于存放所有通过Handler发送过来的消息。这部分消息会一直存放于消息队列当中,等待被处理。每个线程中只会有一个MessageQueue对象,请牢记这句话。其实从字面上就可以看出,MessageQueue底层数据结构是队列,而且这个队列只存放Message对象。
4.Looper
Looper是每个线程中的MessageQueue的管家,调用Looper的loop()方法后,就会进入到一个无限循环当中,然后每当MesssageQueue中存在一条消息,Looper就会将这条消息取出,并将它传递到Handler的handleMessage()方法中。每个线程只有一个Looper对象。
了解了上述Handler机制的4个成员后,我们再来把思路理一遍:首先在UI线程我们创建了一个Handler实例对象,无论是匿名内部类还是自定义类生成的Handler实例对象,我们都需要对handleMessage方法进行重写,在handleMessage方法中我们可以通过参数msg来写接受消息过后UIi线程的逻辑处理,接着我们创建子线程,在子线程中需要更新UI的时候,新建一个Message对象,并且将消息的数据记录在这个消息对象Message的内部,比如arg1,arg2,obj等,然后通过前面的Handler实例对象调用sendMessge方法把这个Message实例对象发送出去,之后这个消息会被存放于MessageQueue中等待被处理,此时MessageQueue的管家Looper正在不停的把MessageQueue存在的消息取出来,通过回调dispatchMessage方法将消息传递给Handler的handleMessage方法,最终前面提到的消息会被Looper从MessageQueue中取出来传递给handleMessage方法,最终得到处理。这就是Handler机制整个的工作流程。
避免ANR
ANR(Application Not Responding)定义
在Android上,如果你的应用程序有一段时间响应不够灵敏,系统会向用户显示一个对话框,这个对话框称作应用程序无响应(ANR:Application Not Responding)对话框。用户可以选择“等待”而让程序继续运行,也可以选择“强制关闭”。所以一个流畅的合理的应用程序中不能出现anr,而让用户每次都要处理这个对话框。因此,在程序里对响应性能的设计很重要,这样系统不会显示ANR给用户。默认情况下,在android中Activity的最长执行时间是5秒,BroadcastReceiver的最长执行时间则是10秒。
Android应用程序通常是运行在一个单独的线程(例如,main)里。这意味着你的应用程序所做的事情如果在主线程里占用了太长的时间的话,就会引发ANR对话框,因为你的应用程序并没有给自己机会来处理输入事件或者Intent广播。
因此,运行在主线程里的任何方法都尽可能少做事情。特别是,Activity应该在它的关键生命周期方法(如onCreate()和onResume())里尽可能少的去做创建操作。潜在的耗时操作,例如网络或数据库操作,或者高耗时的计算如改变位图尺寸,应该在子线程里(或者以数据库操作为例,通过异步请求的方式)来完成。然而,不是说你的主线程阻塞在那里等待子线程的完成——也不是调用Thread.wait()或是Thread.sleep()。替代的方法是,主线程应该为子线程提供一个Handler,以便完成时能够提交给主线程。以这种方式设计你的应用程序,将能保证你的主线程保持对输入的响应性并能避免由于5秒输入事件的超时引发的ANR对话框。这种做法应该在其它显示UI的线程里效仿,因为它们都受相同的超时影响。
IntentReceiver执行时间的特殊限制意味着它应该做:在后台里做小的、琐碎的工作如保存设定或者注册一个Notification。和在主线程里调用的其它方法一样,应用程序应该避免在BroadcastReceiver里做耗时的操作或计算。但不再是在子线程里做这些任务(因为BroadcastReceiver的生命周期短),替代的是,如果响应Intent广播需要执行一个耗时的动作的话,应用程序应该启动一个Service。顺便提及一句,你也应该避免在Intent Receiver里启动一个Activity,因为它会创建一个新的画面,并从当前用户正在运行的程序上抢夺焦点。如果你的应用程序在响应Intent广播时需要向用户展示什么,你应该使用Notification Manager来实现。
一般来说,在应用程序里,100到200ms是用户能感知阻滞的时间阈值。因此,这里有一些额外的技巧来避免ANR,并有助于让你的应用程序看起来有响应性。
如果你的应用程序为响应用户输入正在后台工作的话,可以显示工作的进度(ProgressBar和ProgressDialog对这种情况来说很有用)。
特别是游戏,在子线程里做移动的计算。
如果你的应用程序有一个耗时的初始化过程的话,考虑可以显示一个Splash Screen或者快速显示主画面并异步来填充这些信息。在这两种情况下,你都应该显示正在进行的进度,以免用户认为应用程序被冻结了。
ThreadLocal->Looper->MessageQueue->Message->target->handler
不会,一句话谁发送的消息,谁处理,为什么,因为每个Message消息都会绑定一个target来指定这个消息由谁来处理。
Message消息在被发送时会被绑定Handler
追溯源码发现,无论使用Handler的哪个方法来发送消息,最终都会调用到下面方法来发送,在这里 msg对象会被绑定target,而这里的值为this,正是发送消息的Handler的本身,
1 | private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) { |
Message消息在被处理的时候
追溯源码
1 | public static void loop() { |
msg.target.dispatchMessage(msg); 关键的这一句,msg调用了自身绑定的target的dispatchMessage方法来处理消息,而这里的target正是msg在被发送的时候所绑定的handler.
AIDL
AIDL是Android中IPC(Inter-Process Communication)方式中的一种,AIDL是Android Interface definition language的缩写,对于小白来说,AIDL的作用是让你可以在自己的APP里绑定一个其他APP的service,这样你的APP可以和其他APP交互。
线程通信方式
https://blog.csdn.net/liuxingyuzaixian/article/details/78893392
Intent显示跳转与隐式跳转
https://blog.csdn.net/sinat_22949049/article/details/80064261
apk编译,apk安装过程
- Android通过
AAPT工具将.xml资源文件编译成R.java的二进制文件,除了assets、raw目录下的文件; - 将java文件编译成.class文件;
- 通过dex工具将.class文件转换成.dex文件
- 优化dex文件 : Davlik模式下使用
dexopt工具将.dex文件优化得到.odex文件 ; Art模式下使用dexoat工具将.dex文件优化得到.oat文件; apkbuilder会将.dex文件和未被编译的文件编译成apk;apkSinger对apk签名;zipalign对签名后的apk进行优化
Android 安装的apk文件实际上是以.zip结尾的压缩文件,解压后的文件内容如上图所示
- AndroidManifest.xml对应源代码中的AndroidManifest.xml, 但这里是编译过的,文件内容已经不同了;
- assets对应源代码的assets目录, 是直接复制过来的;
- classes.dex(classes2.dex、classes3.dex等等)是包含所有Java文件对应的字节码,其中
classes.dex是程序主包; - lib目录对应源代码中的libs目录,包含so文件;
- META-INF目录包含CERT.RSA、CERT.SF、MANIFEST.MF等, 保存了各个资源文件的SHA1值,用于校验资源文件是否被篡改,从而防止二次打包时资源文件被替换;
- res目录对应源码的res目录, 包含各种图片、xml等;
- resources.arsc包含了各个资源文件的映射, 可以理解为索引, 通过该文件能找到对应的资源文件信息。
androidManifest文件的作用
AndroidManifest.xml是Android应用的入口文件,它描述了package中暴露的组件(activities, services, 等等),他们各自的实现类,各种能被处理的数据和启动位置。 除了能声明程序中的Activities, ContentProviders, Services, 和Intent Receivers,还能指定permissions和instrumentation(安全控制和测试)。
https://blog.csdn.net/weixin_41729259/article/details/87910512
ProGuard
ProGuard 是一款免费的Java类文件压缩器、优化器和混淆器。它能发现并删除无用类、字段(field)、方法和属性值(attribute)。它也能优化字节码 并删除无用的指令。最后,它使用简单无意义的名字来重命名你的类名、字段名和方法名。经过以上操作的jar文件会变得更小,并很难进行逆向工程。这里提到 了ProGuard的主要功能是压缩、优化和混淆,下面我就先介绍一下这些概念,然后再介绍ProGuard的基本使用方法。
ProGuard支持那些种类的优化:
除了在压缩操作删除的无用类,字段和方法外,ProGuard也能在字节码级提供性能优化,内部方法有:
² 常量表达式求值
² 删除不必要的字段存取
² 删除不必要的方法调用
² 删除不必要的分支
² 删除不必要的比较和instanceof验证
² 删除未使用的代码
² 删除只写字段
² 删除未使用的方法参数
² 像push/pop简化一样的各种各样的peephole优化
² 在可能的情况下为类添加static和final修饰符
² 在可能的情况下为方法添加private, static和final修饰符
² 在可能的情况下使get/set方法成为内联的
² 当接口只有一个实现类的时候,就取代它
² 选择性的删除日志代码
Service的onBind和onStart差别
Service的生命周期方法比Activity少一些,只有onCreate, onStart, onDestroy
我们有两种方式启动一个Service,他们对Service生命周期的影响是不一样的。
1 通过startService
Service会经历 onCreate —> onStart
stopService的时候直接onDestroy
如果是 调用者 直接退出而没有调用stopService的话,Service会一直在后台运行。
下次调用者再起来仍然可以stopService。
2 通过bindService
Service只会运行onCreate, 这个时候 调用者和Service绑定在一起
调用者退出了,Srevice就会调用onUnbind—>onDestroyed
所谓绑定在一起就共存亡了。
注意:Service的onCreate的方法只会被调用一次,
就是你无论多少次的startService又 bindService,Service只被创建一次。
如果先是bind了,那么start的时候就直接运行Service的onStart方法,
如果先是start,那么bind的时候就直接运行onBind方法。如果你先bind上了,就stop不掉了,
只能先UnbindService, 再StopService,所以是先start还是先bind行为是有区别的。
Android中的服务和windows中的服务是类似的东西,服务一般没有用户操作界面,它运行于系统中不容易被用户发觉,可以使用它开发如监控之类的程序。
服务不能自己运行,需要通过调用Context.startService()或Context.bindService()方法启动服务。
这两个方法都可以启动Service,但是它们的使用场合有所不同。使用startService()方法启用服务,调用者与服务之间没有关连,
即使调用者退出了,服务仍然运行。使用bindService()方法启用服务,调用者与服务绑定在了一起,调用者一旦退出,服务也就终止,大有“不求同时生,必须同时死”的特点。
如果打算采用Context.startService()方法启动服务,在服务未被创建时,系统会先调用服务的onCreate()方法,
接着调用onStart()方法。如果调用startService()方法前服务已经被创建,多次调用startService()方法并不会导致多次创建服务,
但会导致多次调用onStart()方法。采用startService()方法启动的服务,只能调用Context.stopService()方法结束服务,服务结束时会调用onDestroy()方法。
如果打算采用Context.bindService()方法启动服务,在服务未被创建时,系统会先调用服务的onCreate()方法,
接着调用onBind()方法。这个时候调用者和服务绑定在一起,调用者退出了,系统就会先调用服务的onUnbind()方法,
接着调用onDestroy()方法。如果调用bindService()方法前服务已经被绑定,
多次调用bindService()方法并不会导致多次创建服务及绑定(也就是说onCreate()和onBind()方法并不会被多次调用)。
如果调用者希望与正在绑定的服务解除绑定,可以调用unbindService()方法,调用该方法也会导致系统调用服务的onUnbind()—>onDestroy()方法.
onBind将返回给客户端一个IBind接口实例,IBind允许客户端回调服务的方法,比如得到Service运行的状态或其他操作。这个时候调用者会和Service绑定在一起,但onBind只能一次,不可多次绑定。
在Service每一次的开启关闭过程中,只有onStart可被多次调用(通过多次startService调用),其他onCreate,onBind,onUnbind,onDestory在一个生命周期中只能被调用一次。
由于Android 中的Service使用了onBind 的方法去绑定服务,返回一个Ibinder对象进行操作,而我们要获取具体的Service方法的内容的时候,我们需要Ibinder对象返回具体的Service对象才能操作,所以说具体的Service对象必须首先实现Binder对象,这个样子的话我们才能利用bindService的方法对Service进行绑定,获取Binder对象之后获取具体的Service对象,然后才获取Service中的方法等等。
与采用Context.startService()方法启动服务有关的生命周期方法
onCreate() —onStart() —onDestroy()
onCreate()该方法在服务被创建时调用,该方法只会被调用一次,无论调用多少次startService()或bindService()方法,服务也只被创建一次。
onStart() 只有采用Context.startService()方法启动服务时才会回调该方法。该方法在服务开始运行时被调用。多次调用startService()方法尽管不会多次创建服务,但onStart() 方法会被多次调用。
onDestroy()该方法在服务被终止时调用。
与采用Context.bindService()方法启动服务有关的生命周期方法
onCreate()— onBind() — onUnbind() — onDestroy()
onBind()只有采用Context.bindService()方法启动服务时才会回调该方法。该方法在调用者与服务绑定时被调用,当调用者与服务已经绑定,多次调用Context.bindService()方法并不会导致该方法被多次调用。
View的绘制过程
https://www.jianshu.com/p/c151efe22d0d
Binder
https://www.jianshu.com/p/4920c7781afe
自定义view
https://www.jianshu.com/p/31a76bf6b816
对于自定义view,很多时候需要使用到自定义属性,我们向实现一个view的自定义属性,需要遵循以下几部:
a.自定义一个CustomView(extends View )类
b.编写values/attrs.xml,在其中编写styleable和item等标签元素
c.在布局文件中CustomView使用自定义的属性(注意namespace)
导入自定义属性,以下两种方式都可(namespace)
http://schemas.android.com/apk/res/包名
http://schemas.android.com/apk/res-auto
d.在CustomView的构造方法中通过TypedArray获取
图片三级缓存
使用三级缓存目的
- 速度快,可以提升用户体验度
- 避免重复请求网络,重复加载,节省流量
三级缓存简介
- 内存缓存, 优先加载, 速度最快(加载到内存,就容易出现OOM)
- 本地缓存, 次优先加载, 速度快
- 网络缓存, 不优先加载, 速度慢,浪费流量
ListView与RecyclerView对比浅析
https://www.jianshu.com/p/193fb966e954
内存溢出OOM
- Android默认给每个app只分配16M的内存(个别的不是)
- java中的引用
- 强引用 垃圾回收器不会回收, java默认引用都是强引用
- 软引用 SoftReference 在内存不够时,垃圾回收器会考虑回收
- 弱引用 WeakReference 在内存不够时,垃圾回收器会优先回收
- 虚引用 PhantomReference 在内存不够时,垃圾回收器最优先回收
注意: Android2.3+, 系统会优先将SoftReference的对象提前回收掉, 即使内存够用
所以:一般都只使用强引用,弱引用太弱了
viewStub
https://www.jianshu.com/p/175096cd89ac
计网
三次握手四次挥手使用哪个协议
建立TCP需要三次握手才能建立,而断开连接则需要四次握手。首先Client端发送连接请求报文,Server段接受连接后回复ACK报文,并为这次连接分配资源。Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了。假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说”我Client端没有数据要发给你了”,但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,”告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息”。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,”告诉Client端,好了,我这边数据发完了,准备好关闭连接了”。Client端收到FIN报文后,”就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,”就知道可以断开连接了”。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
在TIME_WAIT状态中,如果TCP client端最后一次发送的ACK丢失了,它将重新发送。TIME_WAIT状态中所需要的时间是依赖于实现方法的。典型的值为30秒、1分钟和2分钟。等待之后连接正式关闭,并且所有的资源(包括端口号)都被释放。
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,”你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
第三次失败会怎么样
当客户端收到服务端的SYN+ACK应答后,其状态变为ESTABLISHED,并会发送ACK包给服务端,准备发送数据了。如果此时ACK在网络中丢失,过了超时计时器后,那么Server端会重新发送SYN+ACK包,重传次数根据/proc/sys/net/ipv4/tcp_synack_retries来指定,默认是5次。如果重传指定次数到了后,仍然未收到ACK应答,那么一段时间后,Server自动关闭这个连接。但是Client认为这个连接已经建立,如果Client端向Server写数据,Server端将以RST包响应,方能感知到Server的错误。
当失败时服务器并不会重传ack报文,而是直接发送RTS报文段,进入CLOSED状态。这样做的目的是为了防止SYN洪泛攻击。
TCP和UDP区别,工作在哪一层,这一层的主要功能,数据在TCP下有什么变化;(增加tcp头部,udp头部)
TCP和UDP协议都是传输层的协议。
TCP与UDP基本区别
1.基于连接与无连接
2.TCP要求系统资源较多,UDP较少;
3.UDP程序结构较简单
4.流模式(TCP)与数据报模式(UDP);
5.TCP保证数据正确性,UDP可能丢包
6.TCP保证数据顺序,UDP不保证
UDP应用场景:
1.面向数据报方式
2.网络数据大多为短消息
3.拥有大量Client
4.对数据安全性无特殊要求
5.网络负担非常重,但对响应速度要求高
TCP编程的服务器端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt(); * 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();
4、开启监听,用函数listen();
5、接收客户端上来的连接,用函数accept();
6、收发数据,用函数send()和recv(),或者read()和write();
7、关闭网络连接;
8、关闭监听;
TCP编程的客户端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt(); 可选
3、绑定IP地址、端口等信息到socket上,用函数bind(); 可选
4、设置要连接的对方的IP地址和端口等属性;
5、连接服务器,用函数connect();
6、收发数据,用函数send()和recv(),或者read()和write();
7、关闭网络连接;
\UDP:**
与之对应的UDP编程步骤要简单许多,分别如下:
UDP编程的服务器端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();
4、循环接收数据,用函数recvfrom();
5、关闭网络连接;
UDP编程的客户端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt(); 可选
3、绑定IP地址、端口等信息到socket上,用函数bind(); 可选
4、设置对方的IP地址和端口等属性;
5、发送数据,用函数sendto();
6、关闭网络连接;
TCP补充:
TCP充分实现了数据传输时各种控制功能,可以进行丢包的重发控制,还可以对次序乱掉的分包进行顺序控制。而这些在UDP中都没有。此外,TCP作为一种面向有连接的协议,只有在确认通信对端存在时才会发送数据,从而可以控制通信流量的浪费。TCP通过检验和、序列号、确认应答、重发控制、连接管理以及窗口控制等机制实现可靠性传输。
TCP与UDP区别总结:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
TCP头部
/TCP头定义,共20个字节/
typedef struct _TCP_HEADER
{
short m_sSourPort; // 源端口号16bit
short m_sDestPort; // 目的端口号16bit
unsigned int m_uiSequNum; // 序列号32bit
unsigned int m_uiAcknowledgeNum; // 确认号32bit
short m_sHeaderLenAndFlag; // 前4位:TCP头长度;中6位:保留;后6位:标志位
short m_sWindowSize; // 窗口大小16bit
short m_sCheckSum; // 检验和16bit
short m_surgentPointer; // 紧急数据偏移量16bit
}attribute((packed))TCP_HEADER, *PTCP_HEADER;
TCP layer 没有IP地址的概念,那个是IP 层的,所以前4个字节是源端口和目的端口
Sequence Number:传输数据过程中,为每一个封包分配一个序号,保证网络传输数据的顺序性
Acknowledgment Number:用来确认确实有收到相关封包,内容表示期望收到下一个报文的序列号,用来解决丢包的问题
TCP Flags:这部分主要标志数据包的属性,比如SYN,RST,FIN等,操控TCP的状态机
Window:滑动窗口,主要用于解决流控拥塞的问题
Checksum:校验值
Urgent Pointer:紧急指针,可以告知紧急的数据位置,需要和Flag的U flag 配合使用
TCP Options:一般包含在三次握手中,有Option的选项!
UDP头结构的定义
/UDP头定义,共8个字节/
typedef struct _UDP_HEADER
{
unsigned short m_usSourPort; // 源端口号16bit
unsigned short m_usDestPort; // 目的端口号16bit
unsigned short m_usLength; // 数据包长度16bit
unsigned short m_usCheckSum; // 校验和16bit
}attribute((packed))UDP_HEADER, *PUDP_HEADER;
http使用了哪些技术?Get,post区别
https://blog.fundebug.com/2019/02/22/compare-http-method-get-and-post/
GET请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,参数之间以&相连,如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0%E5%A5%BD。如果数据是英文字母或数字,则原样发送;如果是空格,转换为+;如果是中文或其他字符,则直接把字符串用BASE64加密,得出如:%E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII码值。而与之对应的,POST把提交的数据放置在HTTP包的包体中,文章最下面将会有代码示例。
POST的安全性要比GET的安全性高。注意:这里所说的安全性和上面GET提到的“安全”不是同个概念。上面“安全”的含义仅仅是不作数据修改,而这里安全的含义是真正的Security的含义。比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为:(1)登录页面有可能被浏览器缓存,(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击(CSRF,跨站请求伪造,也被称为:one click attack/session riding)。
HTTP 协议采用明文传输信息,存在信息窃听、信息篡改和信息劫持的风险,而协议 TLS/SSL 具有身份验证、信息加密和完整性校验的功能,可以避免此类问题。
TLS/SSL 全称安全传输层协议 Transport Layer Security, 是介于 TCP 和 HTTP 之间的一层安全协议,不影响原有的 TCP 协议和 HTTP 协议,所以使用 HTTPS 基本上不需要对 HTTP 页面进行太多的改造。
HTTPS 协议的主要功能基本都依赖于 TLS/SSL 协议,本节分析安全协议的实现原理。
TLS/SSL 的功能实现主要依赖于三类基本算法:散列函数 Hash、对称加密和非对称加密,其利用非对称加密实现身份认证和密钥协商,对称加密算法采用协商的密钥对数据加密,基于散列函数验证信息的完整性。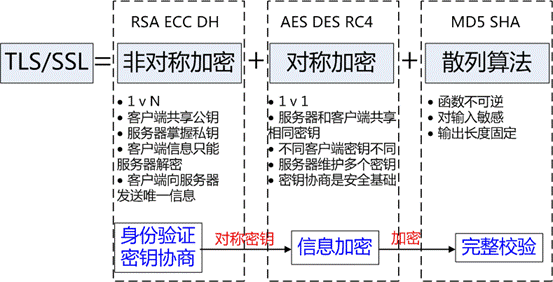

- 在使用HTTPS是需要保证服务端配置正确了对应的安全证书
- 客户端发送请求到服务端
- 服务端返回公钥和证书到客户端
- 客户端接收后会验证证书的安全性,如果通过则会随机生成一个随机数,用公钥对其加密,发送到服务端
- 服务端接受到这个加密后的随机数后会用私钥对其解密得到真正的随机数,随后用这个随机数当做私钥对需要发送的数据进行对称加密
- 客户端在接收到加密后的数据使用私钥(即生成的随机值)对数据进行解密并且解析数据呈现结果给客户
- SSL加密建立
如何实现UDP的可靠传输
传输层无法保证数据的可靠传输,只能通过应用层来实现了。实现的方式可以参照tcp可靠性传输的方式,只是实现不在传输层,实现转移到了应用层。
最简单的方式是在应用层模仿传输层TCP的可靠性传输。下面不考虑拥塞处理,可靠UDP的简单设计。
- 1、添加seq/ack机制,确保数据发送到对端
- 2、添加发送和接收缓冲区,主要是用户超时重传。
- 3、添加超时重传机制。
详细说明:送端发送数据时,生成一个随机seq=x,然后每一片按照数据大小分配seq。数据到达接收端后接收端放入缓存,并发送一个ack=x的包,表示对方已经收到了数据。发送端收到了ack包后,删除缓冲区对应的数据。时间到后,定时任务检查是否需要重传数据。
TIME_WAIT状态处在哪一方以及为什么需要它
在TCP连接中四次挥手关闭连接时,主动关闭连接的一方(上图中时Client)会在发送最后一条ACK报文后维持一段时长2MSL(MSL指的是数据包在网络中的最大生存时间)的等待时间后才会真正关闭连接到CLOSED状态,该时间段内主动关闭方的状态为TIME_WAIT。即在TIME_WAIT状态时,定义这个连接的四元组(源/目的IP、源/目的端口)不能被使用。
为实现TCP连接的可靠释放
若主动断开连接方(上图中Client)最后一次ACK报文丢失了,会触发被动方(上图中Server)的超时重传机制,Server再次向Client发送FIN+ACK报文,如果Client在发送完最后一次ACK后立即断开连接(没有TIME_WAIT状态),则Server会收到RST=1的报文响应,表示连接建立异常,而此时并非异常,只是正常的关闭连接过程,进而导致Server端不能正常关闭连接。因此,Client必须维护2MSL的等待时间,确保在Server端第二次发送的FIN+ACK被Client正常接收,收到后Client立即发送ACK给Server,并重新启动2MSL计时器。(因为极端情况涉及两次报文传输(Client向Server的ACK,Server向Client的FIN+ACK),所以等待时间为2MSL)
为使旧的重复数据包在网络中因过期而消失
可能存在一些数据包在传输过程中出现异常而导致严重推迟,而在它到来之前发送方已经重发了该报文,并完成其任务。如果在被推迟的报文未抵达前接收方断开了连接,随后又建立了一个与之前相同IP、Port的连接,而之前被推迟的报文在这时恰好到达,而此时此新连接非彼连接,从而会发生数据错乱,进而导致无法预知的情况。因此必须维持一段等待时间,使迟到的报文在网络中完全消失,并且在等待时间内,因为连接并未关闭,所以不能建立相同四元组的新连接,就不会出现数据错乱。
在高并发短连接的TCP服务器上,当服务器处理完请求后主动请求关闭连接,这样服务器上会有大量的连接处于TIME_WAIT状态,服务器维护每一个连接需要一个socket,也就是每个连接会占用一个文件描述符,而文件描述符的使用是有上限的,如果持续高并发,会导致一些连接失败。
可设置套接字选项为SO_REUSEADDR,该选项的意思是,告诉操作系统,如果端口忙,但占用该端口TCP连接处于TIME_WAIT状态,并且套接字选项为SO_REUSEADDR,则该端口可被重用。如果TCP连接处于其他状态,依然返回端口被占用。该选项对服务程序重启非常有用。
HTTPs的握手过程
https://razeencheng.com/post/ssl-handshake-detail
客户端发起HTTPS请求
服务端的配置
采用HTTPS协议的服务器必须要有一套数字证书,可以是自己制作或者CA证书。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用CA证书则不会弹出提示页面。这套证书其实就是一对公钥和私钥。公钥给别人加密使用,私钥给自己解密使用。
- 传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等。
- 客户端解析证书
这部分工作是有客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随即值,然后用证书对该随机值进行加密。
- 传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
- 服务段解密信息
服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密。所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。
- 传输加密后的信息
这部分信息是服务段用私钥加密后的信息,可以在客户端被还原。
- 客户端解密信息
客户端用之前生成的私钥解密服务段传过来的信息,于是获取了解密后的内容。
PS: 整个握手过程第三方即使监听到了数据,也束手无策。
总结
为什么HTTPS是安全的?
在HTTPS握手的第四步中,如果站点的证书是不受信任的,会显示出现下面确认界面,确认了网站的真实性。另外第六和八步,使用客户端私钥加密解密,保证了数据传输的安全。
HTTPS和HTTP的区别
https协议需要到ca申请证书或自制证书。
http的信息是明文传输,https则是具有安全性的ssl加密。
http是直接与TCP进行数据传输,而https是经过一层SSL(OSI表示层),用的端口也不一样,前者是80(需要国内备案),后者是443。
http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
注意https加密是在传输层
https报文在被包装成tcp报文的时候完成加密的过程,无论是https的header域也好,body域也罢都是会被加密的。
当使用tcpdump或者wireshark之类的tcp层工具抓包,获取是加密的内容,而如果用应用层抓包,使用Charels(Mac)、Fildder(Windows)抓包工具,那当然看到是明文的。
为什么数据传输不用非对称加密
因为非对称加密加密解密算法效率较低,不适合客户端和服务器端这样高频率的通信过程,在某些极端情况下,甚至能比非对称加密慢上1000倍。
非对称加密的优势在于它可以很好帮助完成秘钥的交换,所以前期交换秘钥必须使用非对称加密算法。
对称密钥加密是指加密和解密使用同一个密钥的方式,这种方式存在的最大问题就是密钥发送问题,即如何安全地将密钥发给对方;为什么叫对称加密?
一方通过密钥将信息加密后,把密文传给另一方,另一方通过这个相同的密钥将密文解密,转换成可以理解的明文。他们之间的关系如下:
1 | 明文 <-> 密钥 <-> 密文 |
常见的对称加密算法:DES,AES,3DES等等。
而非对称加密是指使用一对非对称密钥,即公钥和私钥,公钥可以随意发布,但私钥只有自己知道。发送密文的一方使用对方的公钥进行加密处理,对方接收到加密信息后,使用自己的私钥进行解密。
非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatekey)。公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密。因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。
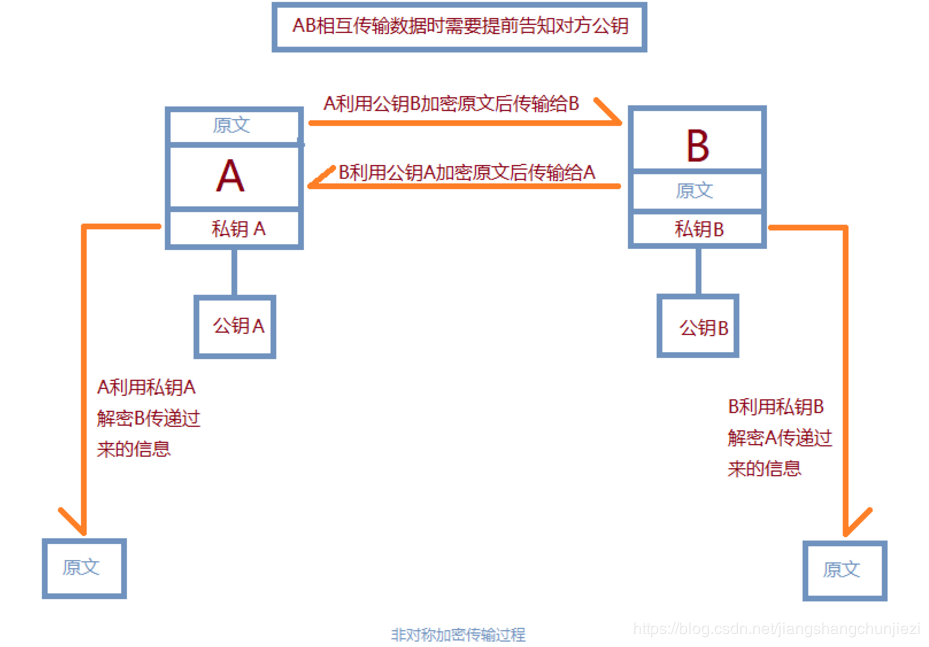
由于非对称加密的方式不需要发送用来解密的私钥,所以可以保证安全性;但是和对称加密比起来,它非常的慢,所以我们还是要用对称加密来传送消息,但对称加密所使用的密钥我们可以通过非对称加密的方式发送出去。
但是此时交换的两个公钥不一定正确
常见的非对称加密算法:RSA,ECC
转发和重定向的区别
转发是服务器行为,重定向是客户端行为。
转发(Forword) 通过 RequestDispatcher 对象的forward(HttpServletRequest request,HttpServletResponse response)方法实现的。RequestDispatcher 可以通过HttpServletRequest 的 getRequestDispatcher()方法获得。例如下面的代码就是跳转到 login_success.jsp 页面。
1 | request.getRequestDispatcher("login_success.jsp").forward(request, response); |
重定向(Redirect) 是利用服务器返回的状态码来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过 HttpServletRequestResponse 的 setStatus(int status)方法设置状态码。如果服务器返回 301 或者 302,则浏览器会到新的网址重新请求该资源。
- 从地址栏显示来说:forward 是服务器请求资源,服务器直接访问目标地址的 URL,把那个 URL 的响应内容读取过来,然后把这些内容再发给浏览器。浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址。redirect 是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址。所以地址栏显示的是新的 URL。
- 从数据共享来说:forward:转发页面和转发到的页面可以共享 request 里面的数据。redirect:不能共享数据。
- 从运用地方来说:forward:一般用于用户登陆的时候,根据角色转发到相应的模块。redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等。
- 从效率来说:forward:高。redirect:低。
在浏览器中输入 url 地址到显示主页的过程,整个过程会使用哪些协议
总体来说分为以下几个过程:
- DNS 解析
- TCP 连接
- 发送 HTTP 请求
- 服务器处理请求并返回 HTTP 报文
- 浏览器解析渲染页面
- 连接结束
具体可以参考下面这篇文章:
select poll epoll
https://blog.csdn.net/nanxiaotao/article/details/90612404
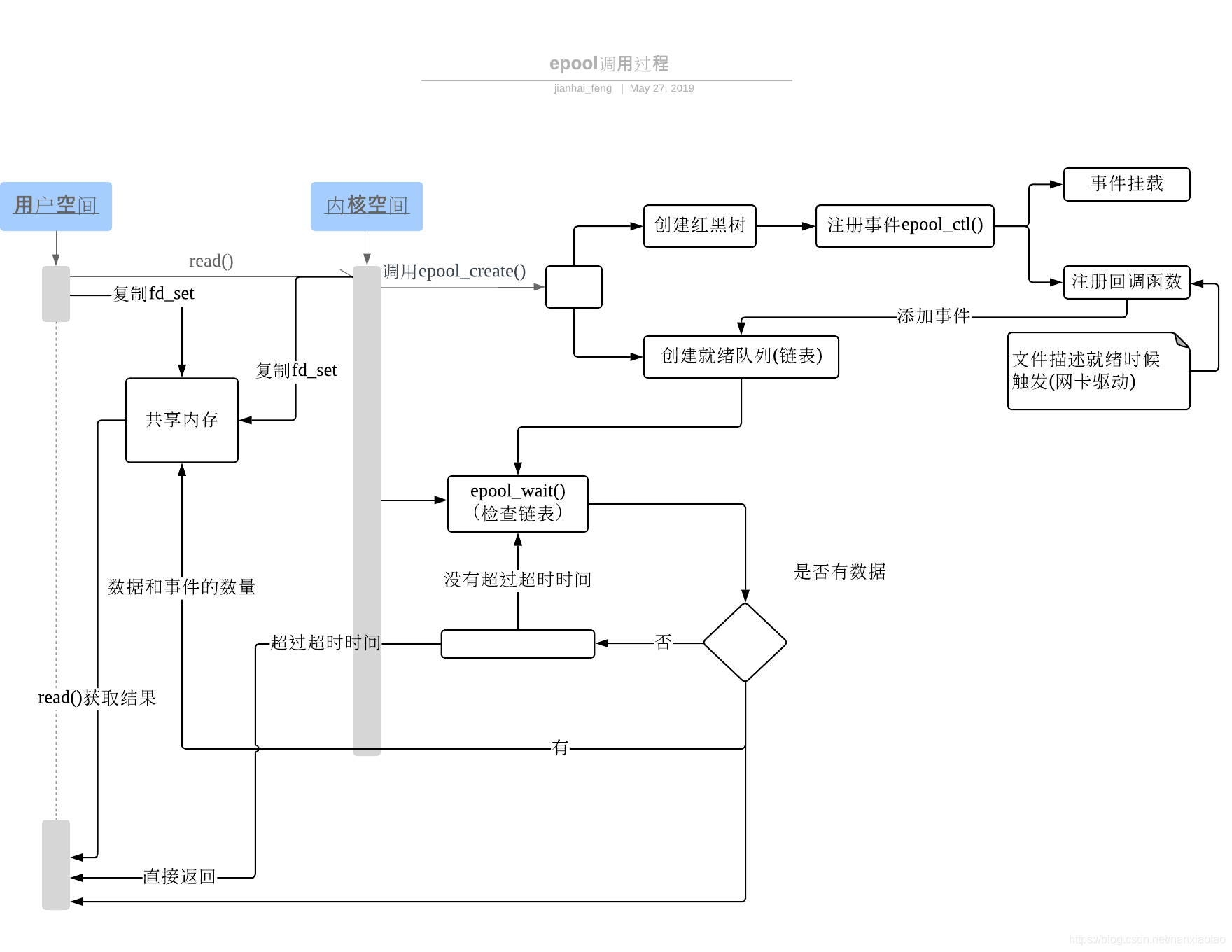
\select——>**
\原理概述:**
select 的核心功能是调用tcp文件系统的poll函数,不停的查询,如果没有想要的数据,主动执行一次调度(防止一直占用cpu),直到有一个连接有想要的消息为止。从这里可以看出select的执行方式基本就是不同的调用poll,直到有需要的消息为止。
缺点:
1、每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大;
2、同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大;
3、select支持的文件描述符数量太小了,默认是1024。
\优点:**
1、select的可移植性更好,在某些Unix系统上不支持poll()。
2、select对于超时值提供了更好的精度:微秒,而poll是毫秒。
\poll——>**
\原理概述:**
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
\缺点:**
1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义;
2、与select一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
\优点:**
1、poll() 不要求开发者计算最大文件描述符加一的大小。
2、poll() 在应付大数目的文件描述符的时候速度更快,相比于select。
3、它没有最大连接数的限制,原因是它是基于链表来存储的。
\epoll——>**
\原理概述:**
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时, 返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一 个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射技术,这 样便彻底省掉了这些文件描述符在系统调用时复制的开销。
\epoll的优点就是改进了前面所说缺点:**
1、支持一个进程打开大数目的socket描述符:相比select,epoll则没有对FD的限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
2、IO效率不随FD数目增加而线性下降:epoll不存在这个问题,它只会对”活跃”的socket进行操作—- 这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有”活跃”的socket才会主动的去调用 callback函数,其他idle状态socket则不会,在这点上,epoll实现了一个”伪”AIO,因为这时候推动力在os内核。在一些 benchmark中,如果所有的socket基本上都是活跃的—-比如一个高速LAN环境,epoll并不比select/poll有什么效率,相 反,如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上了。
3、使用mmap加速内核与用户空间的消息传递:这点实际上涉及到epoll的具体实现了。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就 很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。
\三者对比与区别:**
1、select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
2、select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
OS
线程和进程区别,线程可以脱离进程单独运行吗?
1.定义
进程:具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位.
线程:进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
2.关系
一个线程可以创建和撤销另一个线程;同一个进程中的多个线程之间可以并发执行.
相对进程而言,线程是一个更加接近于执行体的概念,它可以与同进程中的其他线程共享数据,但拥有自己的栈空间,拥有独立的执行序列。
3.区别
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程拥有独立的堆栈空间和数据段,所以每当启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这对于多进程来说十分“奢侈”,系统开销比较大,而线程不一样,线程拥有独立的堆栈空间,但是共享数据段。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
1) 简而言之,一个程序至少有一个进程,一个进程至少有一个线程.
2) 线程的划分尺度小于进程,使得多线程程序的并发性高。
3) 另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
4) 线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
5) 从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。
6)体现在通信机制上面,正因为进程之间互不干扰,相互独立,进程的通信机制相对很复杂,譬如管道,信号,消息队列,共享内存,套接字等通信机制,而线程由于共享数据段所以通信机制很方便。
7)属于同一个进程的所有线程共享该进程的所有资源,包括文件描述符。而不同过的进程相互独立。
8)线程又称为轻量级进程,进程有进程控制块,线程有线程控制块。
9)线程必定也只能属于一个进程,而进程可以拥有多个线程而且至少拥有一个线程。
死锁概念,他的四个必要条件,什么是资源独占
- 互斥条件:资源是独占的且排他使用,进程互斥使用资源,即任意时刻一个资源只能给一个进程使用,其他进程若申请一个资源,而该资源被另一进程占有时,则申请者等待直到资源被占有者释放。
- 不可剥夺条件:进程所获得的资源在未使用完毕之前,不被其他进程强行剥夺,而只能由获得该资源的进程资源释放。
- 请求和保持条件:进程每次申请它所需要的一部分资源,在申请新的资源的同时,继续占用已分配到的资源。
- 循环等待条件:在发生死锁时必然存在一个进程等待队列{P1,P2,…,Pn},其中P1等待P2占有的资源,P2等待P3占有的资源,…,Pn等待P1占有的资源,形成一个进程等待环路,环路中每一个进程所占有的资源同时被另一个申请,也就是前一个进程占有后一个进程所深情地资源。
以上给出了导致死锁的四个必要条件,只要系统发生死锁则以上四个条件至少有一个成立。事实上循环等待的成立蕴含了前三个条件的成立,似乎没有必要列出然而考虑这些条件对死锁的预防是有利的,因为可以通过破坏四个条件中的任何一个来预防死锁的发生。
1.临界资源:我们将一次只允许一个进程使用的资源成为临界资源,临界资源又名 独占资源。
2.临界区:进程中访问临界资源的那段代码,称为临界区,又名 临界段。
什么是僵尸进程
我们知道在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
由于子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束. 那么会不会因为父进程太忙来不及wait子进程,或者说不知道 子进程什么时候结束,而丢失子进程结束时的状态信息呢? 不会。因为UNⅨ提供了一种机制可以保证只要父进程想知道子进程结束时的状态信息, 就可以得到。这种机制就是: 在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。但是仍然为其保留一定的信息(包括进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等)。直到父进程通过wait / waitpid来取时才释放. 但这样就导致了问题,如果进程不调用wait / waitpid的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
孤儿进程是没有父进程的进程,孤儿进程这个重任就落到了init进程身上,init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤 儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。因此孤儿进程并不会有什么危害。
任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理。这是每个 子进程在结束时都要经过的阶段。如果子进程在exit()之后,父进程没有来得及处理,这时用ps命令就能看到子进程的状态是“Z”。如果父进程能及时 处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态。 如果父进程在子进程结束之前退出,则子进程将由init接管。init将会以父进程的身份对僵尸状态的子进程进行处理。
僵尸进程的避免
⒈父进程通过wait和waitpid等函数等待子进程结束,这会导致父进程挂起。
⒉ 如果父进程很忙,那么可以用signal函数为SIGCHLD安装handler,因为子进程结束后, 父进程会收到该信号,可以在handler中调用wait回收。
⒊ 如果父进程不关心子进程什么时候结束,那么可以用signal(SIGCHLD,SIG_IGN) 通知内核,自己对子进程的结束不感兴趣,那么子进程结束后,内核会回收, 并不再给父进程发送信号。
⒋ 还有一些技巧,就是fork两次,父进程fork一个子进程,然后继续工作,子进程fork一 个孙进程后退出,那么孙进程被init接管,孙进程结束后,init会回收。不过子进程的回收 还要自己做。
协程
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
1) 一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
2) 线程进程都是同步机制,而协程则是异步
3) 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
协程的特点:
- 线程的切换由操作系统负责调度,协程由用户自己进行调度,因此减少了上下文切换。
- 线程的默认Stack大小是1M,而协程更轻量,接近1K。因此可以在相同的内存中开启更多的协程。
- 由于在同一个线程上,因此可以避免竞争关系而使用锁。
协程是怎么来处理的呢,就是对于一个阻塞的业务操作,我们不是用线程来处理,而是用用协程,这样当出现IO阻塞的时候,并且你还没运行完时间片,你不会让CPU跑掉,而是调起你的另一个协程任务,让他继续进行计算。而通常我们知道,代码纯计算执行是非常快的,5ms可能跑了N个方法了,因此这样充分的利用时间片,并且减少CPU切换的时间。
多线程和线程池
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。线程池线程都是后台线程。每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中。如果某个线程在托管代码中空闲(如正在等待某个事件),则线程池将插入另一个辅助线程来使所有处理器保持繁忙。如果所有线程池线程都始终保持繁忙,但队列中包含挂起的工作,则线程池将在一段时间后创建另一个辅助线程但线程的数目永远不会超过最大值。超过最大值的线程可以排队,但他们要等到其他线程完成后才启动。
线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。 例如,线程数一般取cpu数量+2比较合适,线程数过多会导致额外的线程切换开销。
任务调度以执行线程的常见方法是使用同步队列,称作任务队列。池中的线程等待队列中的任务,并把执行完的任务放入完成队列中。
线程池模式一般分为两种:HS/HA半同步/半异步模式、L/F领导者与跟随者模式。
- 半同步/半异步模式又称为生产者消费者模式,是比较常见的实现方式,比较简单。分为同步层、队列层、异步层三层。同步层的主线程处理工作任务并存入工作队列,工作线程从工作队列取出任务进行处理,如果工作队列为空,则取不到任务的工作线程进入挂起状态。由于线程间有数据通信,因此不适于大数据量交换的场合。
- 领导者跟随者模式,在线程池中的线程可处在3种状态之一:领导者leader、追随者follower或工作者processor。任何时刻线程池只有一个领导者线程。事件到达时,领导者线程负责消息分离,并从处于追随者线程中选出一个来当继任领导者,然后将自身设置为工作者状态去处置该事件。处理完毕后工作者线程将自身的状态置为追随者。这一模式实现复杂,但避免了线程间交换任务数据,提高了CPU cache相似性。在ACE(Adaptive Communication Environment)中,提供了领导者跟随者模式实现。
线程池的伸缩性对性能有较大的影响。
- 创建太多线程,将会浪费一定的资源,有些线程未被充分使用。
- 销毁太多线程,将导致之后浪费时间再次创建它们。
- 创建线程太慢,将会导致长时间的等待,性能变差。
- 销毁线程太慢,导致其它线程资源饥饿。
进程间有什么通讯方式
1、管道
我们来看一条 Linux 的语句
1 | netstat -tulnp | grep 8080 |
学过 Linux 命名的估计都懂这条语句的含义,其中”|“是管道的意思,它的作用就是把前一条命令的输出作为后一条命令的输入。在这里就是把 netstat -tulnp 的输出结果作为 grep 8080 这条命令的输入。如果两个进程要进行通信的话,就可以用这种管道来进行通信了,并且我们可以知道这条竖线是没有名字的,所以我们把这种通信方式称之为匿名管道。
并且这种通信方式是单向的,只能把第一个命令的输出作为第二个命令的输入,如果进程之间想要互相通信的话,那么需要创建两个管道。
居然有匿名管道,那也意味着有命名管道,下面我们来创建一个命名管道。
1 | mkfifo test |
这条命令创建了一个名字为 test 的命名管道。
接下来我们用一个进程向这个管道里面写数据,然后有另外一个进程把里面的数据读出来。
1 | echo "this is a pipe" > test // 写数据 |
这个时候管道的内容没有被读出的话,那么这个命令就会一直停在这里,只有当另外一个进程把 test 里面的内容读出来的时候这条命令才会结束。接下来我们用另外一个进程来读取
1 | cat < test // 读数据 |
我们可以看到,test 里面的数据被读取出来了。上一条命令也执行结束了。
从上面的例子可以看出,管道的通知机制类似于缓存,就像一个进程把数据放在某个缓存区域,然后等着另外一个进程去拿,并且是管道是单向传输的。
这种通信方式有什么缺点呢?显然,这种通信方式效率低下,你看,a 进程给 b 进程传输数据,只能等待 b 进程取了数据之后 a 进程才能返回。
所以管道不适合频繁通信的进程。当然,他也有它的优点,例如比较简单,能够保证我们的数据已经真的被其他进程拿走了。我们平时用 Linux 的时候,也算是经常用。
2、消息队列
那我们能不能把进程的数据放在某个内存之后就马上让进程返回呢?无需等待其他进程来取就返回呢?
答是可以的,我们可以用消息队列的通信模式来解决这个问题,例如 a 进程要给 b 进程发送消息,只需要把消息放在对应的消息队列里就行了,b 进程需要的时候再去对应的
消息队列里取出来。同理,b 进程要个 a 进程发送消息也是一样。这种通信方式也类似于缓存吧。
这种通信方式有缺点吗?答是有的,如果 a 进程发送的数据占的内存比较大,并且两个进程之间的通信特别频繁的话,消息队列模型就不大适合了。因为 a 发送的数据很大的话,意味发送消息(拷贝)这个过程需要花很多时间来读内存。
哪有没有什么解决方案呢?答是有的,请继续往下看。
3、共享内存
共享内存这个通信方式就可以很好着解决拷贝所消耗的时间了。
这个可能有人会问了,每个进程不是有自己的独立内存吗?两个进程怎么就可以共享一块内存了?
我们都知道,系统加载一个进程的时候,分配给进程的内存并不是实际物理内存,而是虚拟内存空间。那么我们可以让两个进程各自拿出一块虚拟地址空间来,然后映射到相同的物理内存中,这样,两个进程虽然有着独立的虚拟内存空间,但有一部分却是映射到相同的物理内存,这就完成了内存共享机制了。
4、信号量
共享内存最大的问题是什么?没错,就是多进程竞争内存的问题,就像类似于我们平时说的线程安全问题。如何解决这个问题?这个时候我们的信号量就上场了。
信号量的本质就是一个计数器,用来实现进程之间的互斥与同步。例如信号量的初始值是 1,然后 a 进程来访问内存1的时候,我们就把信号量的值设为 0,然后进程b 也要来访问内存1的时候,看到信号量的值为 0 就知道已经有进程在访问内存1了,这个时候进程 b 就会访问不了内存1。所以说,信号量也是进程之间的一种通信方式。
5、Socket
上面我们说的共享内存、管道、信号量、消息队列,他们都是多个进程在一台主机之间的通信,那两个相隔几千里的进程能够进行通信吗?
答是必须的,这个时候 Socket 这家伙就派上用场了,例如我们平时通过浏览器发起一个 http 请求,然后服务器给你返回对应的数据,这种就是采用 Socket 的通信方式了。
总结
所以,进程之间的通信方式有:
1、管道
2、消息队列
3、共享内存
4、信号量
5、Socket
虚拟内存 页表
每条指令在被执行时,读取操作数时需要给出操作数所在的内存地址,这个地址不能是物理主存地址,因为该程序在哪种硬件设置的机器上运行并不能事前确定,那操作系统就不能在此给出对应于某台机器的物理地址。
一、物理内存和虚拟内存
我们先来了解一下,什么是物理内存,什么又是虚拟内存?
1.物理内存:指通过物理内存条而获得的内存空间,主要作用是在计算机运行时为操作系统和各种程序提供临时储存。
2.虚拟内存:对内存架构(内存、缓存、硬盘)进行管理(内存管理系统)的一种手段。简单理解就是在硬盘上划分出一块区域作为内存使用。
2.1 对于用户:
计算机主要面向的是对操作系统等计算机知识几乎没有了解的普通大众,他们大多是不了解什么主存外存的,所以为了方便用户的使用,就有必要使得程序不管是位于内存架构的哪个层次,对于用户来说都是一样的。虚拟内存就是让内存管理实现媒介透明的手段。
2.2 对于主存:
众所周知,一个程序要想运行,就必须加载到物理主存(内存)中,但是物理主存的容量是非常有限的,我们当然可以选择购买更大的物理主存,可是很费钱,那么还有没有什么办法可以在不明显增加成本的基础上扩大内存容量的呢?
虚拟内存就可以做到,它的手段就是将物理主存扩大到便宜、容量大的磁盘上,即将磁盘空间也看作是主存空间的一部分。
用户程序可以存放在主存,也可以部分存放在主存、部分存放在磁盘,那么程序发出的地址到底是在哪里是由操作系统的内存管理模块负责的。
虚拟内存让用户“感觉”内存容量大大增加了,内存速度也加快了,就像魔法师一样,让观众觉得小箱子能够“装下”一只巨大的雄狮。
二、内存管理——分页内存管理
1.内存管理使用的方法
内存管理的方法有许多种,固定加载地址的、固定分区的、非固定分区的和交换内存管理,其中只有第一种固定加载地址的内存管理适用于单道编程,其余三种则适合多道编程。与此同时,它们的共同实现机制是——基址和极限。
2.交换内存管理中的机制——基址和极限
交换内存管理是这些方法中最灵活的。它使用的基址和极限机制实际上就是“将程序发出的虚拟地址加上基址得到物理地址”。
见下图:
3.交换内存管理的两大问题
3.1 空间浪费:程序不断的执行并释放的过程中,造成了内存空间中的可用空间不连续就,难以加以应用,这种现象也称为“外部碎片化”。
见下图:
3.2 程序大小受限
当程序需要更多的内存空间时,需要将其全部从物理内存中“倒出”到磁盘上,再在内存中找到更大的一片区域去存放增长了的程序,这样使得程序的增长效率低下。同时,一个程序的大小还不能超过物理内存空间的大小。
4. 解决方法——分页内存管理
4.1 分页内存管理
将虚拟内存空间和物理内存空间皆划分成大小相同的页面,例如4KB、8KB和16KB等。并将页作为内存空间的最小分配单位,一个程序的一个页面(虚拟页面)可以存放在任何一个物理页面中。
一个程序发出的虚拟地址由虚拟页面号和页内偏移值两部分组成,组成见下:
4.2 分页内存管理是如何解决交换内存管理中的两个问题的?
1.空间浪费:通过将内存空间划分成大小一样的页面,并且将其作为内存分配的基本单位,这样就避免了大量外部碎片的积累,让内存空间得到有效利用。
2.程序受限:分页内存管理下,允许一个进程的部分虚拟页面存放在物理压面(物理内存)中,另一部分存放在磁盘上,等到需要使用时再将其从磁盘中加载到物理内存中。也就是说,当程序需要额外的空间时,只需要对其分配新的页即可,这样做使得程序的增长效率较高。
4.3 虚拟地址->物理地址的转化(地址翻译)
翻译工作则是交给MMU(内存管理单元),它只对虚拟地址的页面号进行翻译,而不处理页内偏移值。
MMU为每一个程序都配备了一个页表,里面存放的是虚拟页面到物理页面的映射,如果MMU接收到了程序发出的虚拟地址,在查找相对应的物理页面号时,没有找到,那么将会通过缺页中断来将需要的虚拟页面从磁盘中加载到物理内存的页面中。
并且随着虚拟页面的进出内存,页表的内容也是不断地变化的。
4.4 页表中的具体信息
MMU为每一个程序配备的页表除了有虚拟地址到物理地址的映射(虚拟页面号到物理页面号),还有其他的与页面的管理活动有关的信息,因为mmu要依赖页表来进行与页面相关的管理活动。
例如,页表如何知道需要的虚拟页面是否在物理页面中?那么页表中就有一项信息记录的是该虚拟页面是否在当前的物理页面中——在内存否。
再说,有一些虚拟页面是受到保护的,对它的读、写和执行操作是有限制的,记录该页面的保护信息的则是——保护标识区。
等等。
可以参考下图中,页表中存储的具体内容:
进程调度算法
https://www.jianshu.com/p/673c9e4817a8
https://blog.csdn.net/u011080472/article/details/51217754
- 先来先服务
- 短作业优先
- 最短剩余时间优先
- 高相应比优先
- 优先级
- 时间片轮转
页面置换算法
https://blog.csdn.net/jankin6/article/details/78179320
数据结构
B+树与红黑树的区别
红黑树:带有平衡性的二叉搜索树增强版
红黑树是每个节点都带有颜色属性的二叉查找树,颜色或红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
性质1. 节点是红色或黑色。
性质2. 根节点是黑色。
性质3 每个叶节点是黑色的。
性质4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
性质5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
这些约束强制了红黑树的关键性质: 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。
要知道为什么这些特性确保了这个结果,注意到性质4导致了路径不能有两个毗连的红色节点就足够了。最短的可能路径都是黑色节点,最长的可能路径有交替的红色和黑色节点。因为根据性质5所有最长的路径都有相同数目的黑色节点,这就表明了没有路径能多于任何其他路径的两倍长。
考虑一棵黑色高度为3的红黑树:从根结点到叶结点的最短路径长度显然是2(黑-黑-黑),最长路径为4(黑-红-黑-红-黑)。由于性质4,不可能在最长路经中加入更多的黑色 结点, 此外根据性质3,红色结点的子结点必须是黑色的,因此在同一简单路径中不允许有两个连续的红色结点。综上,我们能够建立的最长路经将是一个红黑交替的路径。
由此我们可以得出结论:对于给定的黑色高度为n的红黑树,从根到叶结点的简单路径的最短长度为n-1,最大长度为2(n-1)。
B, B-, B+树总结:
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;(关键字可以在非叶子节点和叶子节点)M指的是树的阶数
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
性能比较:
性能相当,都等价于在关键字全集做一次二分查找;
B-树 改善了B树的平衡问题,
B+树比 B-树 更适合文件索引系统(结构上的改善),
B*树比B+树改善了空间利用率。
红黑树:
(1)并不追求“完全平衡”——它只要求部分地达到平衡要求,降低了对旋转的要求,从而提高了性能。红黑树能够以O(log2 n) 的时间复杂度进行搜索、插入、删除操作。
(2)此外,由于它的设计,任何不平衡都会在三次旋转之内解决。红黑树能够给我们一个比较“便宜”的解决方案。红黑树的算法时间复杂度和AVL相同,但统计性能比AVL树更高。
B树
二叉排序树(Binary Sort Tree)又称二叉查找(二路搜索)树,也叫B树。 它或者是一棵空树;或者是具有下列性质的二叉树:
(1)若左子树不空,则左子树上所有结点的值均小于左子树所在树的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于右子树所在树的根结点的值;
(3)左、右子树也分别为二叉排序树;
B树的特点:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
B树的搜索:从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找
B-树
B-树是一种平衡的多路查找树,在文件系统中有所应用。主要用作文件的索引。
B-树是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;如:(M=3)
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
B+树
B+树是应文件系统所需而出的一种B-树的变型树。
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
4.为所有叶子结点增加一个链指针;
5.所有关键字都在叶子结点出现;
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性: 1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
B树和B+树的区别
B/B+树用在磁盘文件组织、数据索引和数据库索引中。其中B+树比B 树更适合实际应用中操作系统的文件索引和数据库索引,因为:
1、B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2、B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、B树在元素遍历的时候效率较低
B+树只要遍历叶子节点就可以实现整棵树的遍历。在数据库中基于范围的查询相对频繁,所以此时B+树优于B树。
??一言而知就是树的深度较高,在磁盘I/O方面的表现不如B树。
??要获取磁盘上数据,必须先通过磁盘移动臂移动到数据所在的柱面,然后找到指定盘面,接着旋转盘面找到数据所在的磁道,最后对数据进行读写。磁盘IO代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘IO频繁读写。根据磁盘查找存取的次数往往由树的高度所决定。
??所以,在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下。在这方面,B树表现相对优异,B树可以有多个子女,从几十到上千,可以降低树的高度。
共享内存与Socket的优缺点与性能比较
要使用一块共享内存,进程必须首先分配它。随后需要访问这个共享内存块的每一个进程都必须将这个共享内存绑定到自己的地址空间中。当完成通信之后,所有进程都将脱离共享内存,并且由一个进程释放该共享内存块。理解 Linux 系统内存模型可以有助于解释这个绑定的过程。在 Linux 系统中,每个进程的虚拟内存是被分为许多页面的。这些内存页面中包含了实际的数据。每个进程都会维护一个从内存地址到虚拟内存页面之间的映射关系。尽管每个进程都有自己的内存地址,不同的进程可以同时将同一个内存页面映射到自己的地址空间中,从而达到共享内存的目的。分配一个新的共享内存块会创建新的内存页面。因为所有进程都希望共享对同一块内存的访问,只应由一个进程创建一块新的共享内存。再次分配一块已经存在的内存块不会创建新的页面,而只是会返回一个标识该内存块的标识符。一个进程如需使用这个共享内存块,则首先需要将它绑定到自己的地址空间中。这样会创建一个从进程本身虚拟地址到共享页面的映射关系。当对共享内存的使用结束之后,这个映射关系将被删除。当再也没有进程需要使用这个共享内存块的时候,必须有一个(且只能是一个)进程负责释放这个被共享的内存页面。
共享内存号称是最快的进程间通信方式,她在系统内存中开辟一块内存区,分别映射到各个进程的虚拟地址空间中,任何一个进程操作了内存区都会反映到其他进程中,各个进程之间的通信并没有像copy数据一样从内核到用户,再从用户到内核的拷贝。这种方式可以像访问自己的私有空间一样访问共享内存区,但是这事这种特性加大了共享内存的编程难度,对于数据的同步问题是一个难点,没有一定的经验很 容易造成数据的混乱。但是我们可以使用一个折中的方法,我们可以结合它和管道来使用。
这样就不会因为,多个进程同时鞋一块内存造成数据的混乱了,看起来是不是有点像管道,其实就是管道的机制,但是不同的是,她的速度要比管道快的多,他的数据大小没有限制(当然不能超过系统的内存大小),当然也不会有阻塞问题。但是这种方式也有明显的缺点,它只适合点对点的通信,如果要多个进程间通信,内存区的数量会呈线性增长,会造成数据的冗余,并且管理起来也会变得困难,如果你的进程数量在各位数着中方式是一个好的选择,否则就要采用一块共享内存,同时做好数据的同步了。
它是基于内存的,所以他只能在同一主机上使用,如果我们要做分布式应用或者跨物理机通信,那么socket就是我们唯一的选择了。
共享内存通信(SHARED MEMORY)
针对消息缓冲需要占用CPU进行消息复制的缺点.OS提供了一种进程间直接进行数据交换的通信方式一共享内存 顾名思义.这种通信方式允许多个进程在外部通信协议或同步,互斥机制的支持下使用同一个内存段(作为中间介质)进行通信.它是一种最有效的数据通信方式,其特点是没有中间环节.直接将共享的内存页面通过附接.映射到相互通信的进程各自的虚拟地址空间中.从而使多个进程可以直接访问同一个物理内存页面.如同访问自己的私有空间一样(但实质上不是私有的而是共享的)。因此这种进程间通信方式是在同一个计算机系统中的诸进程间实现通信的最快捷的方法.而它的局限性也在于此.即共享内存的诸进程必须共处同一个计算机系统.有物理内存可以共享才行。
共享内存针对消息缓冲的缺点改而利用内存缓冲区直接交换信息,无须复制,快捷、信息量大是其优点。但是共享内存的通信方式是通过将共享的内存缓冲区直接附加到进程的虚拟地址空间中来实现的.因此,这些进程之间的读写操作的同步问题操作系统无法实现。必须由各进程利用其他同步工具解决。另外,由于内存实体存在于计算机系统中.所以只能由处于同一个计算机系统中的诸进程共享。不方便网络通信。
其他
帧率,比特率,分辨率
帧速率
帧速率也称为FPS(Frames PerSecond)的缩写——帧/秒。是指每秒钟刷新的图片的帧数,也可以理解为图形处理器每秒钟能够刷新几次。越高的帧速率可以得到更流畅、更逼真的动画。每秒钟帧数(FPS)越多,所显示的动作就会越流畅。
比特率
比特率是指每秒传送的比特(bit)数。单位为bps(Bit Per Second),比特率越高,传送的数据越大。在视频领域,比特率常翻译为码率 !!!
比特率表示经过编码(压缩)后的音、视频数据每秒钟需要用多少个比特来表示,而比特就是二进制里面最小的单位,要么是0,要么是1。比特率与音、视频压缩的关系,简单的说就是比特率越高,音、视频的质量就越好,但编码后的文件就越大;如果比特率越少则情况刚好相反。
比特率是指将数字声音、视频由模拟格式转化成数字格式的采样率,采样率越高,还原后的音质、画质就越好。
常见编码模式:
VBR(Variable Bitrate)动态比特率 也就是没有固定的比特率,压缩软件在压缩时根据音频数据即时确定使用什么比特率,这是以质量为前提兼顾文件大小的方式,推荐编码模式;
ABR(Average Bitrate)平均比特率 是VBR的一种插值参数。LAME针对CBR不佳的文件体积比和VBR生成文件大小不定的特点独创了这种编码模式。ABR在指定的文件大小内,以每50帧(30帧约1秒)为一段,低频和不敏感频率使用相对低的流量,高频和大动态表现时使用高流量,可以做为VBR和CBR的一种折衷选择。
CBR(Constant Bitrate),常数比特率 指文件从头到尾都是一种位速率。相对于VBR和ABR来讲,它压缩出来的文件体积很大,而且音质相对于VBR和ABR不会有明显的提高。
分辨率
就是帧大小每一帧就是一副图像。
720p对应的分辨率为像素1280*720=92w像素
1080p对应的分辨率为1920*1080=207w像素
640*480分辨率的视频,建议视频的码速率设置在700以上,音频采样率44100就行了
一个音频编码率为128Kbps,视频编码率为800Kbps的文件,其总编码率为928Kbps,意思是经过编码后的数据每秒钟需要用928K比特来表示。
计算输出文件大小公式:
(音频编码率(KBit为单位)/8 +视频编码率(KBit为单位)/8)×影片总长度(秒为单位)=文件大小(MB为单位)
电影一般是24帧的,24帧的视频就能满足人眼,然后大家墨守成规,同时为了音画同步,大家就都统一使用24帧的画面。即便是在数字时代,更高的帧数依然需要高昂的成本,24帧依然是主流。当然也有一些例外,如《霍比特人》使用了48帧技术,《比利林恩的中场故事》使用了120帧技术。更高的帧数会有什么效果呢?可以在b站就可以找到很多60帧视频。李安使用4K加取120 帧技术绝对是一项技术革命,从光源,到播放技术,到演员的表演,因为在这种清晰度下真的是毫发毕现,但是这也造成了一种电视剧感,因为我们理解的电影就因为是有一种距离感,一种old school的美学。为什么帧率越高越清晰呢?电影不是连续曝光,24帧是在一秒内拍摄了24张照片,但是不是说每一张照片的曝光时间就是1/24秒,曝光时间应该是1/48秒。曝光时间是通过叫做叶子板的半圆形装置进行的,通过改变开角就可以调整曝光时间,可以理解为快门。只要快门时间不为0,理论上就会造成残影。更高的帧率就代表了每一张照片的曝光时间更短,对比于30帧的视频,60帧的视频中每一幅画面的快门时间更短,造成的模糊效应更小,所以虽然分辨率没有改变,但是视频更加清晰。
电视剧等电视节目与电影除了美学方面的区别,还有很多技术方面的区别:电视的显像管的扫描方式是隔行扫描,而即便是胶片电影,其形成的数字中间片是逐行扫描的;在帧率方面,PAL和SECAM制式是25fps,在美国等一些国家使用的电视扫描频率是59.94Hz,帧率是29.97fps。
我国和大多数欧洲国家使用的交流电是50Hz,由于采用隔行扫描,在PAL或者SECAM视频标准中播放是25 frames per second(fps),PAL标准中为电视节目录制的电影也是25 frames per second,所以对于每一个film frame,捕获得到一个video frame。但是对于最初以24frames/s拍摄的电影,在播放时要加快1/24来匹配,这样就会导致声音不同步,需要使用音高变换器进行校正。使用pulldown方法可以避免加速的过程。为了适应mismatch,需要将24电影帧分配在50个PAL fields中。
NTSC制下交流电频率信号是60Hz,而如果采用间隔扫描下,其实每秒是30张图片,就是30fps,为了把信号和载波区分开,频率降低千分之一,变成了29.97fps。而在电影上播放时,要变成24帧,问题是你不能随便删掉开头的6帧或者结尾的6帧,这样画面会变得很不连续,所以就想出一个方法,叫做2:3pulldown,硬是把5帧的内容缩成了4帧第一个电影帧显示两次,第二帧显示3次,第三帧又显示两次,按照这个规律循环,这样29.97*4/5就是23.976fps了。
隔行扫描
每一帧被分割为两场,每一场包含了一帧中所有的奇数扫描行或者偶数扫描行,通常是先扫描奇数行得到第一场,然后扫描偶数行得到第二场。
无论是逐行扫描还是隔行扫描,都有视频文件、传输和显像三个概念,这三个概念相通但不相同。最早出现的是隔行扫描显像,同时就配套产生了隔行传输。而隔行扫描视频文件是到数字视频时代才出现的,其目的是为了兼容原有的隔行扫描体系(隔行扫描还依然在广泛应用)。
通常显示器分“隔行扫描” 和 “逐行扫描”两种扫描方式。逐行扫描相对于隔行扫描是一种先进的扫描方式,它是指显示屏显示图像进行扫描时,从屏幕左上角的第一行开始逐行进行,整个图像扫描一次完成。因此图像显示画面闪烁小,显示效果好。先进的显示器大都采用逐行扫描方式。
隔行扫描情况下,由于视觉暂留效应,人眼将会看到平滑的运动而不是闪动的半帧半帧的图像。但是这种方法造成了两幅图像显示的时间间隔比较大,从而导致图像画面闪烁较大。 因此该种扫描方式较为落后,通常用在早期的显示产品中。
每一帧图像由电子束顺序地一行接着一行连续扫描而成,这种扫描方式称为逐行扫描。把每一帧图像通过两场扫描完成则是隔行扫描,两场扫描中,第一场(奇数场)只扫描奇数行,依次扫描1、3、5…行,而第二场(偶数场)只扫描偶数行,依次扫描2、4、6…行。隔行扫描技术在传送信号带宽不够的情况下起了很大作用,逐行扫描和隔行扫描的显示效果主要区别在稳定性上面,隔行扫描的行间闪烁比较明显,逐行扫描克服了隔行扫描的缺点,画面平滑自然无闪烁。
高数据库读写效率
可以从以下多个方面优化数据库设计提高数据库查询效率
a. 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
b. 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0
c. 并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
d. 索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
e. 应尽可能的避免更新索引数据列,因为索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新索引数据列,那么需要考虑是否应将该索引建为索引。
f. 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
g. 尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
h. 尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
i. 避免频繁创建和删除临时表,以减少系统表资源的消耗。
j. 临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
k. 在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
l. 如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
可以从以下多个方面比较数据库写入效率:
一、普通方式
普通采用jdbc插入
时间:10万条:16672ms 折合100万条 = 166.72秒
二、事务提交
jdbc用事务进行提交 —> 事务提交是把语句一起执行
时间:10万条:13558ms 折合100万条 = 135.5秒
三、批处理
内部实现是是把 values 后面的插入值变成成 values(,,,),(,,,,)
特别注意:需要url参数加:rewriteBatchedStatements=true
url范例: jdbc:mysql://127.0.0.1/XXX?characterEncoding=UTF-8&rewriteBatchedStatements=true
时间 : 10万条:1273ms 折合100万条 = 12.73秒
四、事务+批处理并且分批执行
结论:加事务时间无影响,但是分批次能提供效率的增加
时间:100万条:9900ms 折合100万条 = 9.99秒
时间:500万条:46943ms = 47秒
综合以上比较结论是: 普通方式 < 事务提交 < 批处理 < 事务+批处理
必要的话配合存储过程应该会进一步提升效率,,,
最后就是在系统架构设计上实施分库分表,再配合外部存储比如redis、缓存、队列等优化对数据库的压力