来源Leetcode第28题实现strstr()
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1:
输入: haystack = “hello”, needle = “ll”
遍历匹配
最简单的直接遍历匹配,没什么好说的,但是我最开始的时候还是越界了,脑子不够用,考虑的不够周全吧。
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 public int strStr(String haystack, String needle) {
if(needle.length() == 0)
return 0;
if(needle.length() > haystack.length())
return -1;
int index = -1;
int j = 1;
for(int i = 0;i < haystack.length() - needle.length() + 1;i++){
j = 0;
while (haystack.charAt(i + j) == needle.charAt(j)) {
j++;
if (j == needle.length()) {
return i;
}
}
}
return index;
}
库函数
题解里有种写法都是用到了库函数,虽然效率高了,但是感觉这不是题目所要求考察的方向。
代码如下:1
2
3
4
5for (int i = 0; i < haystack.length() - needle.length() + 1; i++) {
if (haystack.substring(i, i + needle.length()).equals(needle)) {
return i;
}
}
源码
以下是来自源码的解答:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52/**
* Code shared by String and AbstractStringBuilder to do searches. The
* source is the character array being searched, and the target
* is the string being searched for.
*
* @param source the characters being searched.
* @param target the characters being searched for.
* @param fromIndex the index to begin searching from.
*/
static int indexOf(String source, String target, int fromIndex) {
final int sourceLength = source.length();
final int targetLength = target.length();
if (fromIndex >= sourceLength) {
return (targetLength == 0 ? sourceLength : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetLength == 0) {
return fromIndex;
}
char first = target.charAt(0);
// 计算出最多比较的次数
int max = (sourceLength - targetLength);
for (int i = fromIndex; i <= max; i++) {
// 寻找在source中出现和target第一个字符相等的位置
if (source.charAt(i)!= first) {
while (++i <= max && source.charAt(i) != first);
}
if (i <= max) {
// 找到第一个相等的字符后,从下一个字符开始再比较(下次比较开始的位置)
int j = i + 1;
// 除target第一个字符,剩下字符再比较结束的位置
// 可以理解为:j+(targetLength-1), 即开始的位置+ target剩下要比较字符的长度
int end = j + targetLength - 1;
/* j < end 说明还没有比较完
* j < end && source.charAt(j) == target.charAt(k) 是真说明在还没比较完的情况下比较的字符相等,
* 那么继续循环,直到条件为false
*/
for (int k = 1; j < end && source.charAt(j) == target.charAt(k); j++, k++);
// 上面循环结束时 j刚好等于结束比较的位置,那么就返回上面找到的target第一个字符相等的位置
if (j == end) {
return i;
}
}
}
return -1;
}
KMP算法
最后附上KMP算法的解答,来自题解,先摸了。
题解算法的思路与传统的KMP算法不一致,题解采用了一个dp[par.length()][256]的数组来标记有限状态机的下一步该怎么走,示意图如下:
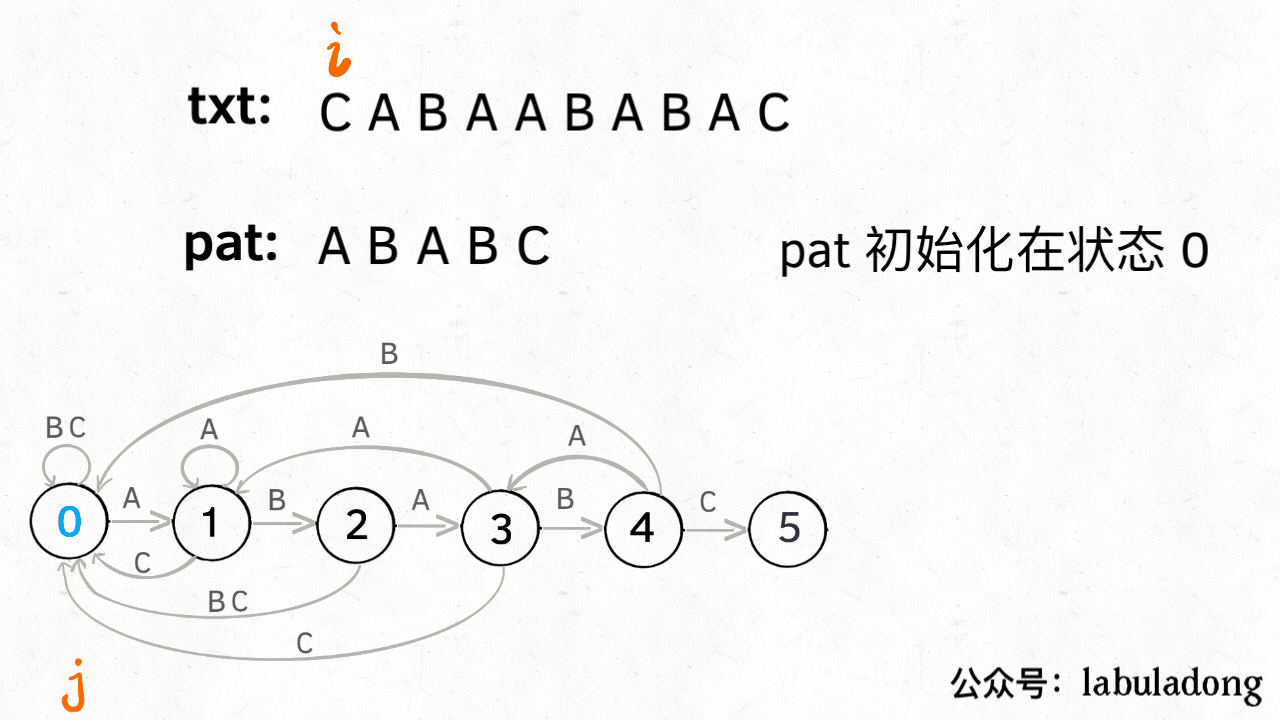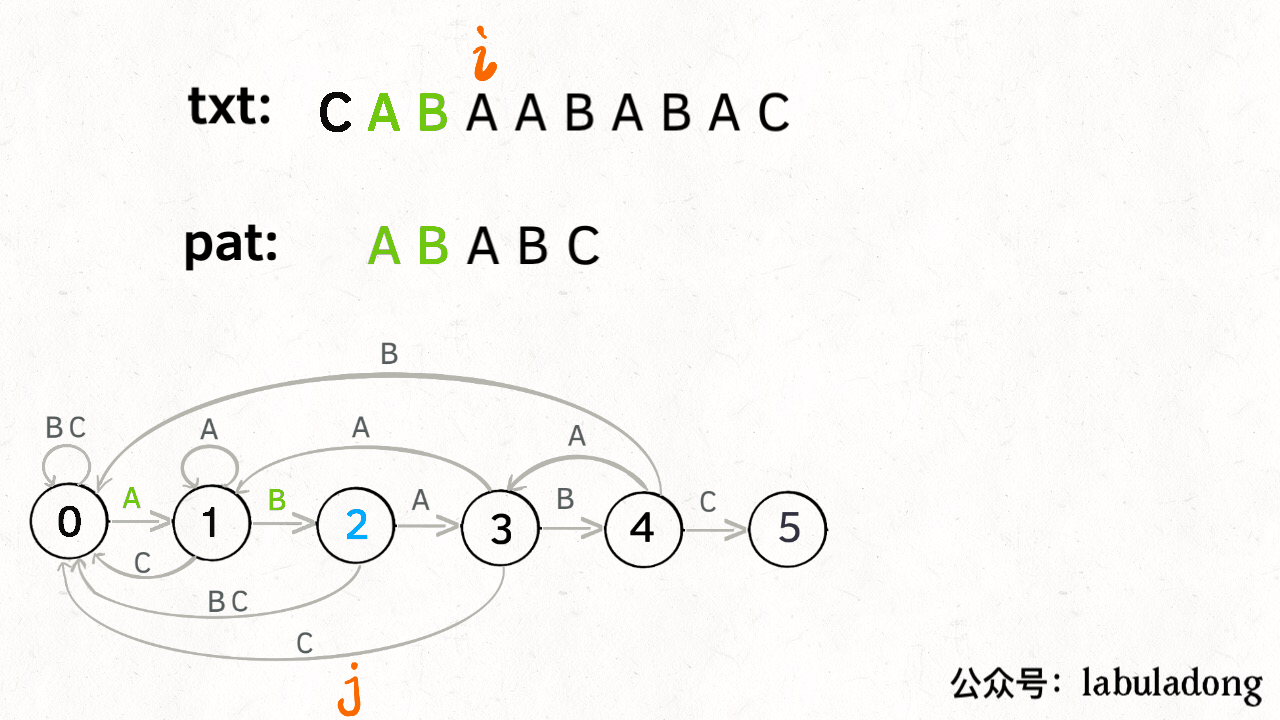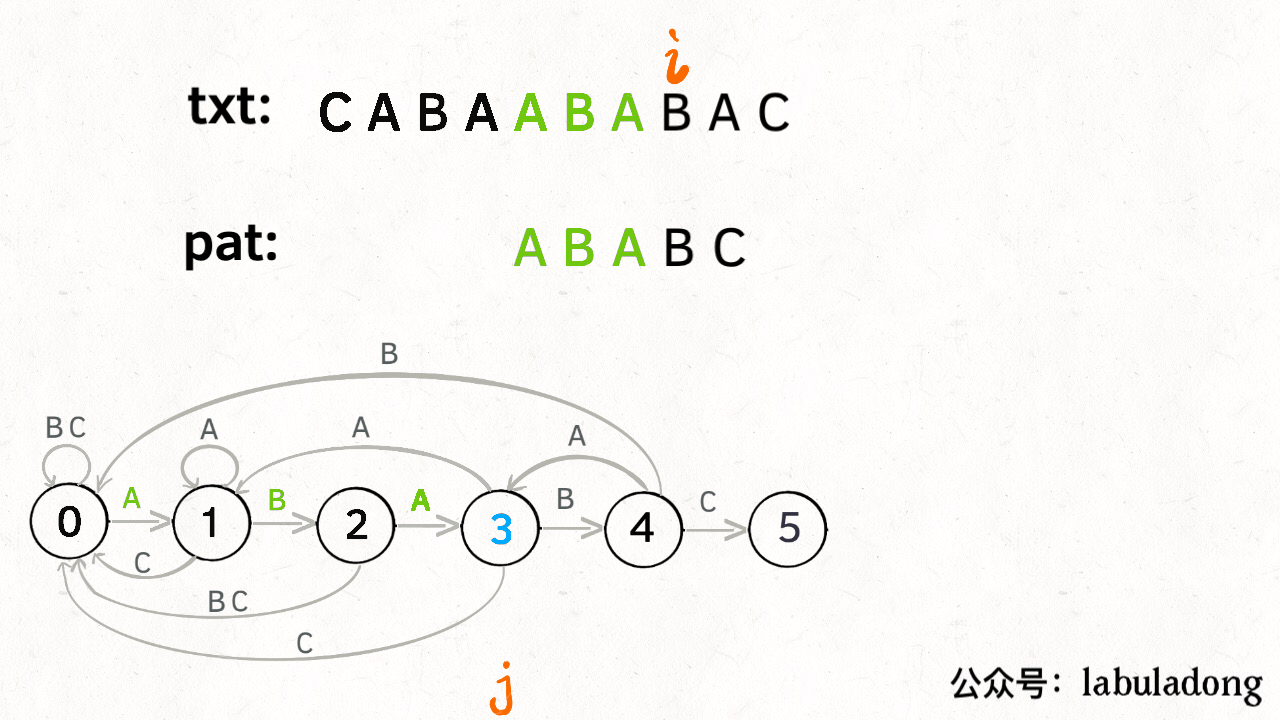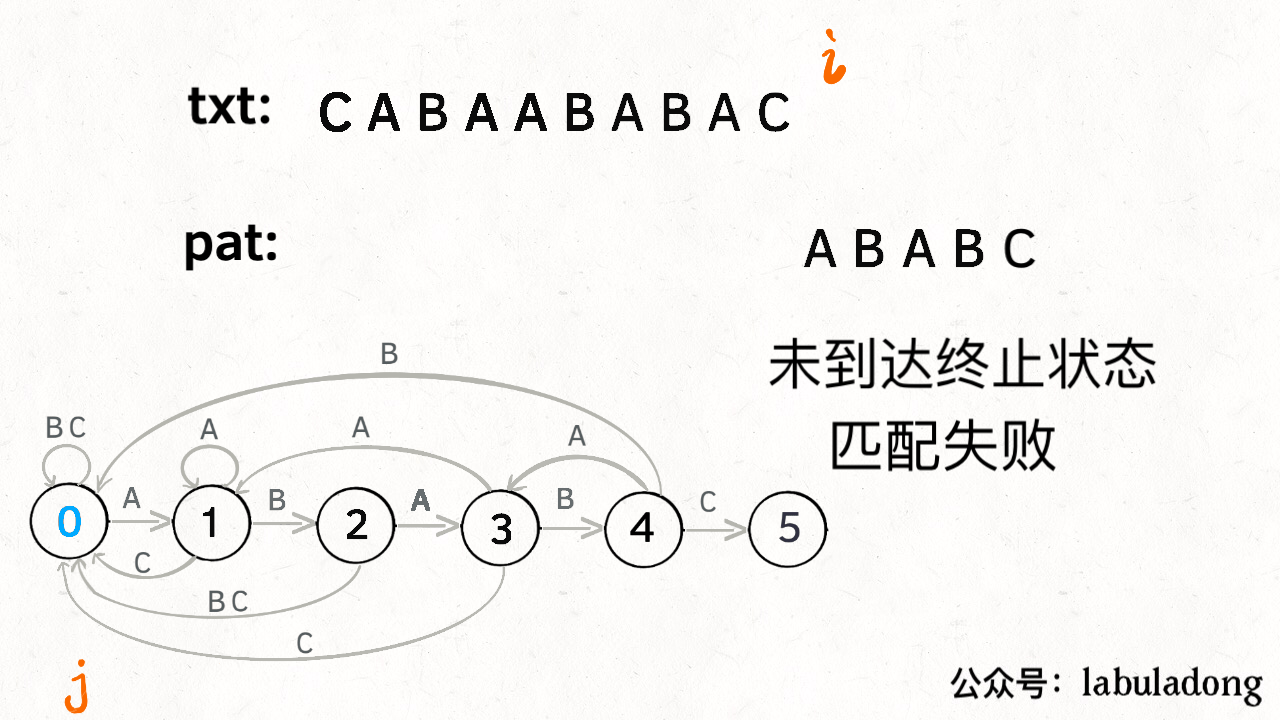
具体过程在题解里说的很清楚了,这里补一下题解的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class KMP {
private int[][] dp;
private String pat;
public KMP(String pat) {
this.pat = pat;
int M = pat.length();
// dp[状态][字符] = 下个状态
dp = new int[M][256];
// base case
dp[0][pat.charAt(0)] = 1;
// 影子状态 X 初始为 0
int X = 0;
// 构建状态转移图(稍改的更紧凑了)
for (int j = 1; j < M; j++) {
for (int c = 0; c < 256; c++) {
dp[j][c] = dp[X][c];
dp[j][pat.charAt(j)] = j + 1;
// 更新影子状态
X = dp[X][pat.charAt(j)];
}
}
public int search(String txt) {
int M = pat.length();
int N = txt.length();
// pat 的初始态为 0
int j = 0;
for (int i = 0; i < N; i++) {
// 计算 pat 的下一个状态
j = dp[j][txt.charAt(i)];
// 到达终止态,返回结果
if (j == M) return i - M + 1;
}
// 没到达终止态,匹配失败
return -1;
}
}
传统的 KMP 算法是使用一个一维数组 next 记录前缀信息,而本文是使用一个二维数组 dp 以状态转移的角度解决字符匹配问题,但是空间复杂度仍然是 O(256M) = O(M)。
在 pat 匹配 txt 的过程中,只要明确了「当前处在哪个状态」和「遇到的字符是什么」这两个问题,就可以确定应该转移到哪个状态(推进或回退)。
对于一个模式串 pat,其总共就有 M 个状态,对于 ASCII 字符,总共不会超过 256 种。所以我们就构造一个数组 dp[M][256] 来包含所有情况,并且明确 dp 数组的含义:
dp[j][c] = next 表示,当前是状态 j,遇到了字符 c,应该转移到状态 next。
明确了其含义,就可以很容易写出 search 函数的代码。
对于如何构建这个 dp 数组,需要一个辅助状态 X,它永远比当前状态 j 落后一个状态,拥有和 j 最长的相同前缀,我们给它起了个名字叫「影子状态」。
在构建当前状态 j 的转移方向时,只有字符 pat[j] 才能使状态推进(dp[j][pat[j]] = j+1);而对于其他字符只能进行状态回退,应该去请教影子状态 X 应该回退到哪里(dp[j][other] = dp[X][other],其中 other 是除了 pat[j] 之外所有字符)。
对于影子状态 X,我们把它初始化为 0,并且随着 j 的前进进行更新,更新的方式和 search 过程更新 j 的过程非常相似(X = dp[X][pat[j]])。